
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Кодирование символов
Кодирование символов
Общие соображения
- Подробности
- Родительская категория: Кодирование символов
- Категория: Кодирование символов
Текст (изначально) есть материализованная человеческая речь. Поэтому в первом приближении структура текста сходна со структурой речи: фразы — слова — фонемы для речи превращаются в фразы — слова — буквы для фонетических систем или в фразы — лексемы — знаки (иероглифы) для нефонетических. Таким образом, элементарной информационной единицей для представления текста является символ текста (буква, фонема, иероглиф).
Хочется иметь возможность изображать и обрабатывать любой текст из тех, что печатаются в книгах. Что именно хочется изображать/кодировать?
- Собственно символы, входящие в состав данного текста;
- Конфигурацию символов, используемых в данном тексте;
- Расположение фрагментов текста на странице (колонки, таблицы, направление текста, и т.п.);
- Расположение символов внутри фрагмента текста, например, надстрочные и подстрочные индексы, символы в математических или в химических формулах;
- Составные символы, включающие несколько отдельно кодируемых частей (интеграл или сумма с пределами, …).
Каково общее количество символов, которые хочется изображать:
- Буквы латинские — 26 * 2 = 52, так как строчные и прописные;
- Буквы русские — 32 * 2 = 64, строчные и прописные;
- Цифры — 10 штук;
- Знаки препинания -тоже штук 10;
- Знаки математических операций — тоже более 10;
- Греческие буквы — используются в математических текстах;
- Дополнительные знаки, используемые в текстах разного вида, такие как $,%,#,@,§,...
- Специальные символы, используемые в различных специфических областях деятельности, например, нотные знаки в музыке, типографские (корректорские) знаки, специальные математические знаки (интегралы, кванторы и т.п.);
- Если текст многоязычный, то дополнительно буквы национальных алфавитов.
Всего для исчерпывающего кодирования фонетических систем письменности требуется изображать (кодировать) несколько сотен (а может быть, и более 1000) символов.
Если хочется кодировать нефонетическое письмо (например, иероглифы), то количество потребных кодов увеличивается до тысяч.
ASCII-код. Структура кодовой таблицы
- Подробности
- Родительская категория: Кодирование символов
- Категория: Кодирование символов
American Standard Code for Information Interchange (см. таблицу ниже) использовал 7 битов. Всего можно было изобразить до 128 символов, но из них печатных было 96. 8-й бит использовали по-разному:
- для контроля четности;
- как признак "нет/есть данные";
- для расширения набора изображаемых символов;
- никак не использовали.
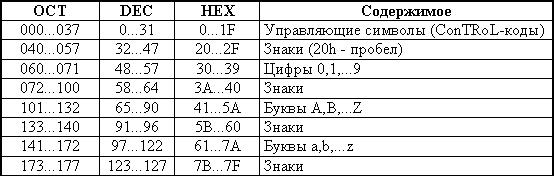
Примечание: В дальнейшем изложении все приводимые коды даны в десятичном виде, если система счисления не обозначена явно.
Алфавитно-цифровые символы и символ пробела
Они занимают часть кодов, начиная с 48, и упорядочены, что позволяет легко:
- производить преобразование из числового представления в символьное:
код_цифры = число + 30h
- переходить от порядкового номера в алфавите к коду буквы — для латинского алфавита:
код_прописной_буквы = порядковый_номер + 40h
код_строчной_буквы = порядковый_номер + 60h
Кроме того, упорядочение позволяет легко программировать сортировку записей, включая и левые пробелы, по алфавиту или по возрастанию чисел.
Арифметические знаки и знаки препинания расположены с алфавитно-цифровыми “вперемешку”.
Управляющие символы
В технике передачи символьной информации (телеграфии) надо было передавать не только печатные символы, но и дополнительную управляющую информацию, такую, как:
- переход к следующей строке;
- переход к началу строки;
- отмена последнего переданного символа, ....;
- и еще многие другие.
Для этого в таблице ASCII была выделена часть кодов с 0 по 31. Некоторые наиболее употребительные управляющие коды с их обозначениями, пришедшими из техники телеграфной связи, даны в таблице (см. таблицу ниже):
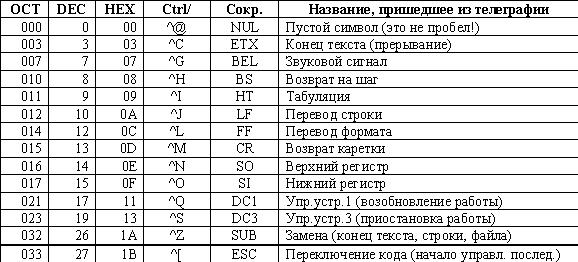
Управляющие символы называют Control-кодами (от английского слова "управление").
На старых примитивных устройствах символьного ввода-вывода — телетайпах — с каждой клавишей был однозначно связан формируемый код. Для формирования же управляющих кодов на телетайпах делалась специальная клавиша Control, удержание которой "обнуляло" три старших бита в коде, формируемом при нажатии "обычной" алфавитно-цифровой клавиши. Например, для ввода управляющего символа ESC с кодом 1Bh надо было нажать клавишу с символом ; (код 3Bh) или клавишу с символом (код 5Bh). Любой из этих кодов при обнуленных трех старших битах давал код 1Bh (символа ESC). Отсюда название клавиши Ctrl на современных клавиатурах.
Среди управляющих символов отметим символы, ипользуемые для расширения количества изображаемых символов. Это прежде всего SO (код 14) и SI (код 15), которые и раньше использовались для переключения наборов символов (например латинского и русского при 7-битовой кодировке).
Кроме того, это символ ESC (код 27). С этого кода начинаются последовательности символов, называемые управляющими. Эти последовательности также используются для переключения кодовых таблиц, а, кроме того, для изменения многих других свойств символьных устройств (клавиатур, дисплеев, принтеров и т.п.). Управляющие языки принтеров (фирм Epson, Hewlett-Paccard) основаны на таких Esc-последовательностях. Принцип формирования Esc-последовательности состоит в следующем: если в потоке кодов встретился код ESC, то несколько следующих кодов не являются кодами изображаемых символов (хотя и могут совпадать с ними), а несут информацию о команде для устройства.
Например, для Epson-совместимых принтеров:
Esc ! n — Эта последовательность из трех символов выдается на принтер в общем потоке символов. Символы ! n не печатаются, а вызывают переключение на встроенный шрифт принтера с номером n (диапазон номеров зависит от модели принтера). Это пример простой команды. Длина последовательности переменная и определяется видом команды. В данном случае символ ! говорит, что требуется переключить шрифт и что еще один символ (байт ) не должен печататься, а несет информацию о номере шрифта.
А вот более сложная команда: Esc & 0 n1nka1d1...dm. Символы & 0 после Esc говорят, что это команда, которая переопределяет конфигурацию символов текущего фонта, загруженного в ОЗУ принтера. Байты n1 и nk задают начальный и конечный коды диапазона символов, очертания которых будут переопределяться. Байт a1 задает размер матрицы, в которой рисуется символ. Байты d1 … dm определяют конфигурацию символов.
Задача кодирования изображений
- Подробности
- Родительская категория: Кодирование символов
- Категория: Кодирование символов
Задача кодирования изображений
Изображение, воспринимаемое зрительным анализатором человека (глазами), представляет собой образ динамической трехмерной сцены.
С течением времени изменяются как свойства предметов и источников (такие, как яркость и отражающие свойства), так и их взаимное положение в пространстве. Глаз воспринимает световое поле E(x,y,t,f); x, y — координаты, t — время, f — частота света. Наиболее сложная задача, которую решают современные средства ВТ при отображении графики, — моделирование динамических трехмерных сцен.
- Трехмерная (3D — образ) — означает, что в качестве исходных данных используется информация о положении объектов сцены и источников света в трехмерном пространстве.
- Динамическая — означает, что объекты сцены могут перемещаться, и для последовательных отображаемых кадров значения яркостей / цветов некоторых (или всех) отображаемых точек придется пересчитывать.
- Способы кодирования зависят от того, для чего кодируем. Кодируют для следующих целей:
- •Обработка — доступ к пикселам, соответствие формы представления и свойств системы команд;
•Хранение — компактность, совместимость, независимость от конкретных типов устройства на котором изображение было сформировано и устройства, на котором оно может быть отображено.
•Отображение (как пишем в Видео RAM) — должно быть соответствие между размерностями выводимого изображения и размерностями устройства отображения во всех трех координатах.
Для перехода от непрерывного представления 2D-изображения должны быть выполнены две операции:
- Пространственная дискретизация по x и по y (размер изображения. т.е. сколько писелов в строке/сколько строк). Параметры цвета в пределах одного пиксела принимаются постоянными.
- Дискретизация цветовых компонент по уровню — представление непрерывной величины мощности одним значением из конечного ряда значений. Для представления цветовых компонент (см. далее) можно в зависимости от требуемой точности (верности воспроизведения цвета) использовать различное количество значений (и следовательно битов для их кодирования). Во многих используемых вариантах для кодирования одного цвета используется менее одного байта — кодирование битовыми полями.
Отметим, что цифровые цветные/полутоновые 2D-изображения, полученные пространственной дискретизацией, являются растровыми, т.е. в них описываются индивидуально характеристики каждого пиксела изображения.
Упрощение растрового многоуровневого можно проводить в двух направлениях:
- Уменьшать количество уровней дискретизации цветов/тона, вплоть до двух, когда характеристика пиксела "светится — не светится", переход к бинарному изображению.
- Индивидуально описывать не все пикселы изображения, а только принадлежащие "объектам", т.е. переход к векторному описанию изображения.
Расширения кодовой таблицы
- Подробности
- Родительская категория: Кодирование символов
- Категория: Кодирование символов
Когда IBM сделал свой PC, он использовал 8-й бит и расширил кодовую таблицу (см. таблицу ниже).
| Коды | Назначение |
| 128...175 | Иностранные символы |
| 176...213 | Символы псевдографики |
| 224...254 | Научные символы |
Кодировки русскоязычные
Использовали символы переключения регистров для замены части символов — латинские буквы заменяли русскими. Так делалось в стандартном ASCII. В поток символов вставляли, например SI и SO, которые трактовались как РУС и ЛАТ. В тексте, где русские и латинские буквы чередуются, — до двух байтов на символ.
В кодировке IBM для русификации были использованы коды из второй половины 256-байтовой кодовой таблицы. При использовании любой конкретной схемы замены часть программ будет работать (отображать на экране) неверно. Существовало и использовалось несколько способов расположения русских символов.
Кодирование символов кириллицы
- КОИ-8 — Кириллица перекрывает псевдографику, символы расположены не в алфавитном порядке (c 192 кириллица заменяет латинские буквы: ю,а,б,с,д…). Используется а электронной почте.
- СР1251 — стандарт для Microsoft Windows (с 192 по 256 — прописные и строчные буквы кириллицы).
- СР866 DOS (Альтернативная кодировка)- А-Я: 128-159; а-п: 160-175; р-я: 224-239.
Кодовые страницы
Этот подход — расширение идеи с переключением регистров или кодировок. Могут быть выбраны управляющие последовательности для смены кодовых страниц. Кодовые страницы — стандартизованы международно.
Посмотрите в каталоге DOS файл country.txt.
x-cp866 (DOS)
koi8-r (UNIX)
x-cp1251 (Windows)
iso-8859-5
x-koi8-u (UNIX)
x-cp866-u(DOS)
Разметка текста
Для разметки текста могут использоваться два способа. Первый состоит в использовании специальных "не символьных" кодировок, в пределе приводящих к кодированию образа документа как растрового или векторного изображения. Другой способ состоит в добавлении внутрь текста специальных последовательностей символов для разметки, которые должны интерпретироваться не как символы.
Примеры языков/систем кодирования: SGML (Standard Generic Markup Language); HTML (HyperText Markup Language); ; TROFF (Unix); PostScript; PDF.
Postscript
Postscript был разработан Джоном Уорноком и Чаком Гешке из Adobe Systems в начале 80-х гг. Исходно Postscript использовался как ядро механизма печати компьютеров Apple, но вскоре стал широко распространенным стандартом для большинства компьютерных систем. Интерпретаторы Postscript (в виде программных или аппаратных компонентов) для печати документов присутствуют практически во всех современных компьютерных системах.
В Postscript используется модель изображения текста (или рисунков) на чистой странице. Когда страница готова, она выводится на печать и начинается "прорисовка" изображения очередной страницы. Это есть не что иное, как метод компиляции. Каждый документ Postscript включает в себя программу, которая печатает на принтере (или отображает на экране монитора) следующие друг за другом страницы.
Программа Postscript состоит из четырех компонентов:
- Интерпретатор для выполнения вычислений. Основной моделью такого интерпретатора является простой стек постфиксного выполнения.
- Синтаксис языка. Он основан на синтаксисе языка Forth.
- Расширения для раскрашивания. Расширение языка Forth командами закрашивания для управления процессом отображения текста и рисунков на листе бумаги.
- Соглашения. Набор соглашений, не входящих в официальный язык Postscript; которые используют различные принтеры для согласования представления документов. Использование этих соглашений упрощает передачу документов Postscript из одной системы в другую.
Postscript был разработан как архитектура виртуальной машины, предназначенной для создания печатных документов. В большинстве приложений не предполагается, что программист будет читать текст документа Postscript. Тем не менее, синтаксис Postscript достаточно прост и легок для восприятия. Существуют образовательные программы для обучения этому языку программирования. Его синтаксис и семантика отличаются простотой, а доступность программ для отображения на экране документов Postscript означает, что у любого пользователя имеется возможность доступа к интерпретатору виртуальной машины, на которой можно тестировать свои Postscript-программы. Следующим этапом развития Postscript стало создание фирмой Adobe формата PDF (Portable Document Format — формат переносимых документов). PDF -это форма сжатия файлов Postscript. Программы чтения PDF-файлов свободно распространяются по Интернету, а большинство web-браузеров могут отображать PDF-файлы.
Напишем программу, рисующую квадрат со стороной один дюйм, расположенный в центре страницы:
newpath 200 300 moveto 0 72 rlineto 0 -72 rlineto -72 0 rlineto 5 setlinewidth stroke showpage
HTML
HTML вовсе не является языком программирования. HTML — это язык разметки. Вы используете HTML для разметки текстового документа, точно так же, как это делает редактор при помощи жирного красного карандаша. Эти пометки служат для определения формата (или стиля), который будет использован при выводе текста на экран монитора.
Если у вас есть желание выделить часть текста на Web-странице жирным шрифтом, вы отметите ее следующим образом:
<B>this text appears bold</B>
Символы <В> "включают" жирный шрифт, а </В> "выключают" его. Они называются тэгами (от англ. tag — ярлык, признак.) и не отображаются на экране. Они лишь предписывают выводить заключенный между ними текст жирным шрифтом.
Стандарт Unicode
Стандарт Unicode использует два байта для изображения символа. Количество кодов — 65536. Текстовые файлы становятся вдвое длиннее. Однако многие текстовые редакторы сочетают текст с графикой и используют свои форматы с большим количеством управляющей информации — реальное увеличение объема — около 25%.
Требуется значительный объем ОЗУ для хранения таблицы фонтов. ArialCyr в Windows занимает немного больше 50 кБайт на 256 символов. Фонт для 50000 символов — в 200 раз больше — 10 МБайт ???
Во многих алфавитах символы составные. Немецкий, французский -
буквы с диакритическими знаками.
Иврит и арабский — тексты справа-налево, а числа слева направо. В
арабском не два набора символов (строчные — прописные), а четыре.
В китайском, японском, корейском — десятки тысяч иероглифов ....
1977 год — стандарт ISO-646 на кодирование символов.
1983 год — начало разработки нового стандарта ISO-10646, в котором предполагалось:
- обеспечить совместимость с существующими системами;
- включить в систему кодирования знаки различных письменностей, в частности, восточных.
В 1987...1991 годах создается некоммерческая организация: консорциум Unicode, в ее техническом комитете ведущие компании, например, Borland, IBM, Lotus, Microsoft, Nowell, Sun и многие другие. Предполагалось, что Unicode к 1995 году станет стандартом "де юре" (см. таблица ниже).
| Коды | Описание |
| 0...127 | Нынешний ASCII |
| ...8191 | Различные алфавиты (лат., кирилица, увропейские, иврит...) |
| 8192...12287 | Знаки пунктуации, математические символы, орнаменты |
| 12288...16383 | Фонетические и др., спец. символы китайского, корейского, японского языков |
| 16384...59391 | Китайские, корейские, японские иероглифы |
| 59392...65024 | Блок для частного использования |
| 65025...65536 | Блок обеспечения совместимости |
Символьное представление чисел — универсальный формат межкомпьютерного общения
Числа представляются кодами символов соответствующих цифр и букв:
-32.655E-3 — 10 байтов с кодами символов.
Такой формат одинаково воспринимается любой вычислительной системой: перед использованием числового значения оно формируется системой путем преобразования из символьной строки во внутреннее представление.
Пример. Формат CSV (comma separated values) — используется многими электронными таблицами для обмена данными.
Классы изображений
- Подробности
- Родительская категория: Кодирование символов
- Категория: Кодирование символов
Бинарные изображения
По уровню имеется только два значения (при преобразовании из полутонового существенным будет выбор порога). В данном случае битовое поле, соответствующее одному пикселу, имеет длину один бит.
Изображения, описываемые кривыми
а описываем только точки, принадлежащие элементам графических объектов (например для задания окружности указываем координаты центра, радиус и атрибуты рисования — цвет линии и т.п.). Выбирается некоторый набор элементарных объектов (примитивов) — отрезок прямой, окружность, прямоугольник и т.п. Изображение "строится" из этих примитивов. Переход от растрового к векторному представлению (векторизация) является нетривиальной задачей.
Изображения, описываемые точками (многоугольниками)
Это частный и достаточно простой случай векторного представления. Используются только угловые точки фигур, в промежутках применяется линейная интерполяция, т.е. изображение строится только из отрезков прямых.
Еще статьи...
Подкатегории
-
Кодирование символов
- Кол-во материалов:
- 13