
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Память. Верхний уровень
Память. Верхний уровень
Динамическое распределение памяти
- Подробности
- Родительская категория: Память. Верхний уровень
- Категория: Динамическое распределение памяти
Распределение памяти в вычислительной системе предполагает ее выделение для разных видов команд и данных с целью обеспечить нужный объем и требуемое быстродействие памяти. Такое выделение проводится статически (команды и директивы транслятора) или динамически. Статическое выделение связано с резервированием памяти, например, под массивы. Если эта память не используется, то она все равно занята и недоступна программам. Динамическое выделение памяти предполагает, что память занята только на короткое время, а затем она освобождается. Выделим три уровня динамического распределения памяти: стек, виртуальная память, команды операционной системы.
- Стек. Все переменные и массивы объединяются в заголовке функции. Они хранятся в стеке и освобождают память только при окончании выполнения функции. Во время выполнения функции стек может только увеличиваться, например, при выполнении рекурсивных обращений к другим функциям. Возможно неконтролируемое увеличение стека.
- Виртуальная память — это механизм распределения памяти по страницам и загрузки этих страниц из внешней памяти. Он является основным методом динамического распределения памяти в ЭВМ и будет рассмотрен ниже. Механизм виртуальной памяти требует аппаратной и программной поддержки. В ряде случаев этот механизм неэффективен или им сложно воспользоваться. Например, в ситуации работы с большими кадрами изображений при ограниченной памяти или при отсутствии аппаратной поддержки.
- Команды операционной системы. Вводятся две функции: выделение памяти и освобождения памяти. Функция, выделяющая память, резервирует необходимый объем памяти с заданными свойствами, а функция освобождения памяти освобождает память, и она может быть использована снова при выделении.
При запросе на выделение памяти указывается требуемый размер участка. Для поиска нужного участка необходим список (таблица) свободных участков с указанием их размеров. Обычно на уровне операционной системы поддерживается таблица блоков, на которые разбивается память с указанием занятости блока. Эта таблица упорядочена по возрастанию объемов блоков с целью быстрого поиска нужного объема. Если выделенный объем больше требуемого, то часть памяти не используется. Эта ситуация называется фрагментацией памяти.
Виртуальная память
- Подробности
- Родительская категория: Память. Верхний уровень
- Категория: Виртуальная память
Технология виртуализации касается разных сторон вычислительной системы. Это — разделение сервера на несколько виртуальных машин, каждая из которых способна выполнять собственную операционную систему и прикладную среду. Это — виртуализация внешних устройств. Наконец это — виртуализации памяти.
Виртуализация памяти (виртуальная память) — метод автоматического управления иерархической памятью, при котором программисту кажется, что он имеет дело с единой памятью большой емкости и высокого быстродействия. Нижний слой памяти может включать память на магнитных дисках, сеть и другие элементы.
Идея виртуальной памяти возникла из желания выполнять программы большего размера чем ОЗУ. Вначале стали использовать оверлейную структуру программ, когда большая программа разбивается на отдельные модули перекрытия — оверлеи (overlays). Первый модуль загружается в память и работает. Если ему нужен код или данные, содержащиеся в других модулях, то работающий модуль вызывает функции, загружающие другие модули. При этом программист сам должен отследить:
- вызов функций загрузки,
- передачу управления вновь загруженным модулям,
- контроль суммарного объема загруженных модулей (объем не должен превышать имеющегося объема памяти),
- размещение модулей в памяти, и другие подобные вопросы. Эта работа оказывается весьма трудоемкой.
При этом отметим, что, поскольку вновь загружаемые модули "ложатся" в память на место находившихся там ранее, то
- разные объекты программы, находящиеся в разных модулях, но попадающие в одно и то же место физической памяти получают одни и те же физические адреса;
- расходуется время на перезагрузку модулей;
- фрагментируется память, поскольку модули имеют разные размеры;
- для работы в другой конфигурации памяти требуется перекомпоновка программы.
Как альтернатива оверлейной структуре, возникла концепция виртуальной памяти (1961 г, Манчестер). Фактически используется та же идеология перезагрузки модулей — свопинг (swapping), однако замена осуществляется аппаратурой и операционной системой автоматически, без какого-либо участия программиста и незаметно для него (см. рисунок ниже).
При этом программист оперирует адресами в (линейном) виртуальном адресном пространстве задачи, размер которого не меньше размера программы (включающей как исполняемый код так и данные). Каждый объект программы в пространстве виртуальных адресов имеет уникальный адрес. Программа пишется в виртуальных адресах.
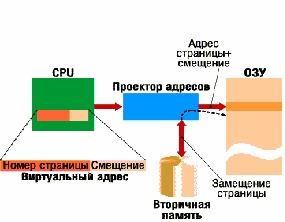
Схема организации виртуальной памяти
Общие принципы защиты памяти
- Подробности
- Родительская категория: Память. Верхний уровень
- Категория: Общие принципы защиты памяти
Механизм защиты позволяет ограничить влияние неправильно работающей программы на другие выполняемые программы и их данные. Защита представляет собой ценное свойство при разработке программных продуктов, поскольку она обеспечивает сохранность в памяти при любых ситуациях средств разработки программного обеспечения (операционной системы, отладчика). При сбое в прикладной программе в полной исправности сохраняется программное обеспечение, позволяющее выдать диагностические сообщения, а отладчик имеет возможность произвести "посмертный" анализ содержимого памяти и регистров сбойной программы. В системах, эксплуатирующих готовое программное обеспечение, защита позволяет повысить его надежность и дает возможность инициировать восстановительные процедуры в системе.
Можно назвать следующие цели защиты:
- Средства защиты могут быть использованы для предотвращения взаимного влияния одновременно выполняемых задач. Например, может выполняться защита от затирания одной задачей команд и данных другой задачи в частности операционной системы.
- При разработке программы механизм защиты поможет получить более четкую картину программных ошибок. Когда программа выполняет неожиданную ссылку к недопустимой в данный момент области памяти, механизм защиты может блокировать данное событие и сообщить о нем.
- В системах, предназначенных для конечных пользователей механизм защиты может предохранять систему от программных сбоев, вызываемых не выявленными ошибками в программах.
Защита в ЭВМ может быть построена на следующих принципах:
- Расщепление адресных пространств при трансляции адресов.
- Проверки разрешено/запрещено при работе с памятью при записи или чтении операндов.
- Защита отдельных ячеек памяти, каждая из которых имеет специальный разряд защиты. Этот разряд проверяется при обращении к памяти.
- Метод граничных регистров. Защищаемая область непрерывна и связана с двумя регистрами: начало и конец защищаемой области и признак защиты (чтение, запись). При обращении адрес сравнивается со значениями регистров. Требуется по 2 регистра на каждую защищаемую область.
- Кольца защиты (см. рисунок ниже). Задачи, выполняемые на ЭВМ, разделяют по уровню привилегий. Минимально используют два уровня привилегий: супервизор, пользователь. Такое разделение используется в процессоре PowerPC 603.
- Метод ключей защиты. Память разбивается на блоки фиксированной длинны (страницы). Каждому блоку ставится в соответствие некий код, называемый ключ защиты памяти. Каждой программе в свою очередь присваивается код защиты программы. Условием доступа программы к блоку памяти служит совпадение ключа и кода защиты или равенство их нулю. Нулевой код защиты имеет операционная система. Память разбита на страницы. Составляется таблица страниц, которая содержит адрес страницы, ключ защиты и признак защиты. При обращении к памяти производится проверка прав доступа. Использован в IBM 360/370.
- Задание точек входов в подпрограммы.
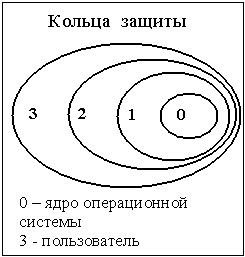
Кольца защиты
В процессорах Pentium, Itanium механизм защиты распознает четыре уровня привилегированности, нумеруемые от 0 до 3. Чем больше номер, тем ниже уровень привилегированности. При удовлетворении всех прочих проверок защиты исключение общей защиты генерируется при попытке программы доступа к сегменту с большим уровнем привилегированности (т.е. с меньшим числом, задающим уровень), чем имеет данный сегмент.
В ЭВМ VAX-11 в системе есть 4 уровня привилегий (кольца защиты):
- 00kernelрежим ядра
- 01executerрежим управления
- 10supervisorконтроль
- 11userпользователь
Что такое многозадачность и зачем она нужна
- Подробности
- Родительская категория: Память. Верхний уровень
- Категория: Многозадачность
Что такое многозадачность и зачем она нужна
Понятие "задача" (task) в первом приближении аналогично понятию "программа". Когда говорят о многозадачном режиме, имеют в виду возможность одновременного (параллельного) выполнения нескольких программ. Истинная параллельность возможна лишь в многопроцессорной системе, когда каждая программа выполняется на своем ресурсе.
В однопроцессорной системе несколько программ могут разделять процессорное время. При переключении с одной задачи на другую требуется сохранять контекст прерываемой задачи, чтобы можно было впоследствии продолжить ее выполнение. Это обычно делает операционная система, причем, для этого совсем не обязательно наличие какой-либо специальной аппаратной поддержки. Например, в DOS 5 есть программная оболочка DosShell, содержащая в своем составе подобный переключатель задач, работающий в реальном режиме процессора 8086 и сохраняющий (достаточно медленно) образ прерываемой задачи на жестком диске.
Чем может быть полезна многозадачность
В большей части случаев достигается повышение производительности труда человека, например, в следующих ситуациях:
- Выполнение длинных рутинных операций (форматирование текста, долгая передача через модем, копирование длинных файлов и т.п.)
- Работа одновременно с несколькими приложениями, когда выходные данные одних служат входными для других. Например, связка FineReader (сканирование и распознавание текста) + PhotoEditor (сканирование и редактирование изображений) + AcrobatReader (чтение документов в формате .pdf) --> MsWord (окончательное оформление документа, содержащего выдержки из документации, из сканированного текста и рисунки).
- Использование процессорного времени фоновой задачей в том случае, когда текущая задача ожидает предоставления ресурса.
Дисковые массивы и уровни RAID(RAID массивы)
- Подробности
- Родительская категория: Память. Верхний уровень
- Категория: Дисковые массивы и уровни RAID(RAID массивы)
В 1987 г. Паттерсон, Гибсон и Катц, американские исследователи из Калифорнийского университета в Беркли, описали в своей статье “A Case for Redundant Arrays of Inexpensive Disks (RAID)” несколько типов дисковых массивов, обозначив их аббревиатурой RAID. Основная идея RAID состояла в объединении нескольких небольших и недорогих дисков в массив, который по производительности не уступал бы одному большому диску (Single Large Expensive Drive, SLED), использовавшемуся обычно с компьютерами типа мэйнфрейм. Заметим, что для компьютера этот массив дисков должен был выглядеть как одно логическое устройство. Увеличение количества дисков в массиве, как правило, означало повышение производительности, по крайней мере при чтении информации. Слово "недорогой" (inexpensive) в названии RAID характеризует стоимость одного диска в массиве по сравнению с большими дисками мэйнфреймов. Кстати, некоторое время спустя после выхода вышеупомянутой статьи из Беркли пришла новая расшифровка аббревиатуры RAID — Redundant Arrays of Independent Disks. Дело в том, что из-за низкой надежности недорогих дисков в массивах первоначально пришлось использовать достаточно дорогие дисковые устройства мэйнфреймов.
Одним из способов повышения производительности ввода/вывода является использование параллелизма путем объединения нескольких физических дисков в матрицу (группу) с организацией их работы аналогично одному логическому диску. К сожалению, надежность матрицы любых устройств падает при увеличении числа устройств. Полагая интенсивность отказов постоянной, т.е. при экспоненциальном законе распределения наработки на отказ, а также при условии, что отказы независимы, получим, что среднее время безотказной работы (mean time to failure — MTTF) матрицы дисков будет равно:
MTTF одного диска / Число дисков в матрице
Для достижения повышенного уровня отказоустойчивости приходится жертвовать пропускной способностью ввода/вывода или емкостью памяти. Необходимо использовать дополнительные диски, содержащие избыточную информацию, позволяющую восстановить исходные данные при отказе диска. Отсюда получают акроним для избыточных матриц недорогих дисков RAID (redundant array of inexpensive disks). Существует несколько способов объединения дисков RAID. Каждый уровень представляет свой компромисс между пропускной способностью ввода/вывода и емкостью диска, предназначенной для хранения избыточной информации.
Когда какой-либо диск отказывает, предполагается, что в течение короткого интервала времени он будет заменен и информация будет восстановлена на новом диске с использованием избыточной информации. Это время называется средним временем восстановления (mean time to repair — MTTR). Этот показатель можно уменьшить, если в систему входят дополнительные диски в качестве "горячего резерва":
При отказе диска резервный диск подключается аппаратно-программными средствами. Периодически оператор вручную заменяет все отказавшие диски.
Четыре основных этапа этого процесса состоят в следующем:
- Определение отказавшего диска.
- Устранение отказа без останова обработки.
- Восстановление потерянных данных на резервном диске.
- Периодическая замена отказавших дисков на новые.
Еще статьи...
Подкатегории
-
Сиситемные регистры процессоров Intel хх86
- Кол-во материалов:
- 3
-
Трансляция адреса в защищенном режиме в проц-х x86
- Кол-во материалов:
- 11
-
Дисковые массивы и уровни RAID(RAID массивы)
- Кол-во материалов:
- 9
-
Многозадачность
- Кол-во материалов:
- 4
-
Общие принципы защиты памяти
- Кол-во материалов:
- 1
-
Виртуальная память
- Кол-во материалов:
- 3
-
Динамическое распределение памяти
- Кол-во материалов:
- 1