Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Память. Верхний уровень
Дисковые массивы и уровни RAID(RAID массивы)
Дисковые массивы и уровни RAID(RAID массивы)
- Подробности
- Родительская категория: Память. Верхний уровень
- Категория: Дисковые массивы и уровни RAID(RAID массивы)
В 1987 г. Паттерсон, Гибсон и Катц, американские исследователи из Калифорнийского университета в Беркли, описали в своей статье “A Case for Redundant Arrays of Inexpensive Disks (RAID)” несколько типов дисковых массивов, обозначив их аббревиатурой RAID. Основная идея RAID состояла в объединении нескольких небольших и недорогих дисков в массив, который по производительности не уступал бы одному большому диску (Single Large Expensive Drive, SLED), использовавшемуся обычно с компьютерами типа мэйнфрейм. Заметим, что для компьютера этот массив дисков должен был выглядеть как одно логическое устройство. Увеличение количества дисков в массиве, как правило, означало повышение производительности, по крайней мере при чтении информации. Слово "недорогой" (inexpensive) в названии RAID характеризует стоимость одного диска в массиве по сравнению с большими дисками мэйнфреймов. Кстати, некоторое время спустя после выхода вышеупомянутой статьи из Беркли пришла новая расшифровка аббревиатуры RAID — Redundant Arrays of Independent Disks. Дело в том, что из-за низкой надежности недорогих дисков в массивах первоначально пришлось использовать достаточно дорогие дисковые устройства мэйнфреймов.
Одним из способов повышения производительности ввода/вывода является использование параллелизма путем объединения нескольких физических дисков в матрицу (группу) с организацией их работы аналогично одному логическому диску. К сожалению, надежность матрицы любых устройств падает при увеличении числа устройств. Полагая интенсивность отказов постоянной, т.е. при экспоненциальном законе распределения наработки на отказ, а также при условии, что отказы независимы, получим, что среднее время безотказной работы (mean time to failure — MTTF) матрицы дисков будет равно:
MTTF одного диска / Число дисков в матрице
Для достижения повышенного уровня отказоустойчивости приходится жертвовать пропускной способностью ввода/вывода или емкостью памяти. Необходимо использовать дополнительные диски, содержащие избыточную информацию, позволяющую восстановить исходные данные при отказе диска. Отсюда получают акроним для избыточных матриц недорогих дисков RAID (redundant array of inexpensive disks). Существует несколько способов объединения дисков RAID. Каждый уровень представляет свой компромисс между пропускной способностью ввода/вывода и емкостью диска, предназначенной для хранения избыточной информации.
Когда какой-либо диск отказывает, предполагается, что в течение короткого интервала времени он будет заменен и информация будет восстановлена на новом диске с использованием избыточной информации. Это время называется средним временем восстановления (mean time to repair — MTTR). Этот показатель можно уменьшить, если в систему входят дополнительные диски в качестве "горячего резерва":
При отказе диска резервный диск подключается аппаратно-программными средствами. Периодически оператор вручную заменяет все отказавшие диски.
Четыре основных этапа этого процесса состоят в следующем:
- Определение отказавшего диска.
- Устранение отказа без останова обработки.
- Восстановление потерянных данных на резервном диске.
- Периодическая замена отказавших дисков на новые.
RAID 0. RAID 1: Зеркальные диски
- Подробности
- Родительская категория: Память. Верхний уровень
- Категория: Дисковые массивы и уровни RAID(RAID массивы)
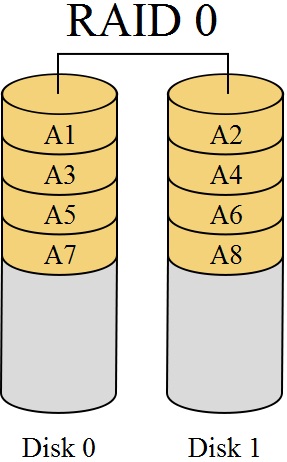
RAID 0
RAID 0 (striping — «чередование») — дисковый массив из двух или более жёстких дисков с отсутствием резервирования. Информация разбивается на блоки данных (Ai) и записывается на оба/несколько дисков одновременно.
(+): За счёт этого существенно повышается производительность (от количества дисков зависит кратность увеличения производительности).
(-): Надёжность RAID 0 заведомо ниже надёжности любого из дисков в отдельности и падает с увеличением количества входящих в RAID 0 дисков, т. к. отказ любого из дисков приводит к неработоспособности всего массива.
RAID 1
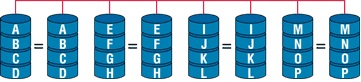
Зеркальные диски представляют традиционный способ повышения надежности магнитных дисков. Это наиболее дорогостоящий из рассматриваемых способов, так как все диски дублируются и при каждой записи информация записывается также и на проверочный диск. Таким образом, приходится идти на некоторые жертвы в пропускной способности ввода/вывода и емкости памяти ради получения более высокой надежности. Зеркальные диски широко применяются многими фирмами. В частности компания “Tandem Computers” применяет зеркальные диски, а также дублирует контроллеры и магистрали ввода/ вывода с целью повышения отказоустойчивости. Эта версия зеркальных дисков поддерживает параллельное считывание.
Дублирование всех дисков может означать удвоение стоимости всей системы или, иначе, использование лишь 50% емкости диска для хранения данных. Повышение емкости, на которое приходится идти, составляет 100%. Такая низкая экономичность привела к появлению следующего уровня RAID.
(+): Обеспечивает приемлемую скорость записи и выигрыш по скорости чтения при распараллеливании запросов.
(+): Имеет высокую надёжность — работает до тех пор, пока функционирует хотя бы один диск в массиве. Вероятность выхода из строя сразу двух дисков равна произведению вероятностей отказа каждого диска. На практике при выходе из строя одного из дисков следует срочно принимать меры — вновь восстанавливать избыточность. Для этого с любым уровнем RAID (кроме нулевого) рекомендуют использовать диски горячего резерва. Достоинство такого подхода — поддержание постоянной доступности.
(-): Недостаток заключается в том, что приходится выплачивать стоимость двух жёстких дисков, получая полезный объём одного жёсткого диска (классический случай, когда массив состоит из двух дисков).
RAID 2: Матрица с поразрядным расслоением
- Подробности
- Родительская категория: Память. Верхний уровень
- Категория: Дисковые массивы и уровни RAID(RAID массивы)
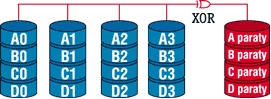
Один из путей достижения надежности при снижении потерь емкости памяти может быть подсказан организацией основной памяти, в которой для исправления одиночных и обнаружения двойных ошибок используются избыточные контрольные разряды. Такое решение можно повторить путем поразрядного расслоения данных и записи их на диски группы, дополненной достаточным количеством контрольных дисков для обнаружения и исправления одиночных ошибок. Один диск контроля четности позволяет обнаружить одиночную ошибку, но для ее исправления требуется больше дисков.
Такая организация обеспечивает лишь один поток ввода/вывода для каждой группы, независимо от ее размера. Группы большого размера приводят к снижению избыточной емкости, идущей на обеспечение отказоустойчивости, тогда как при организации меньшего числа групп наблюдается снижение операций ввода/вывода, которые могут выполняться матрицей параллельно.
При записи больших массивов данных системы уровня 2 имеют такую же производительность, что и системы уровня 1, хотя в них используется меньше контрольных дисков и, таким образом, по этому показателю они превосходят системы уровня 1. При передаче небольших порций данных производительность теряется, так как требуется записать или считать группу целиком, независимо от конкретных потребностей. Таким образом, RAID уровня 2 предпочтительны для суперкомпьютеров, но не подходят для обработки транзакций. Компания “Thinking Machine” использовала RAID уровня 2 в ЭВМ Connection Machine при 32 дисках данных и 10 контрольных дисках, включая 3 диска горячего резерва.
Недостаток массива RAID 2 в том, что для его функционирования нужна структура из почти двойного количества дисков, поэтому такой вид массива не получил распространения.
RAID 3: Аппаратное обнаружение ошибок и четность
- Подробности
- Родительская категория: Память. Верхний уровень
- Категория: Дисковые массивы и уровни RAID(RAID массивы)
Большинство контрольных дисков, используемых в RAID уровня 2, нужны для определения положения неисправного разряда. Эти диски становятся полностью избыточными, так как большинство контроллеров в состоянии определить, когда диск отказал, при помощи специальных сигналов, поддерживаемых дисковым интерфейсом, либо при помощи дополнительного кодирования информации, записанной на диск и используемой для исправления случайных сбоев. По существу, если контроллер может определить положение ошибочного разряда, то для восстановления данных требуется лишь один бит четности. Уменьшение числа контрольных дисков до одного на группу снижает избыточность емкости до вполне разумных размеров. Часто количество дисков в группе равно 5 (4 диска данных плюс 1 контрольный). Подобные устройства выпускаются, например, фирмами “Maxtor” и “Micropolis”. Каждое из таких устройств воспринимается машиной как отдельный логический диск с учетверенной пропускной способностью, учетверенной емкостью и значительно более высокой надежностью.
Достоинства:
- высокая скорость чтения и записи данных;
- минимальное количество дисков для создания массива равно трём.
Недостатки:
- массив этого типа хорош только для однозадачной работы с большими файлами, так как время доступа к отдельному сектору, разбитому по дискам, равно максимальному из интервалов доступа к секторам каждого из дисков. Для блоков малого размера время доступа намного больше времени чтения.
- большая нагрузка на контрольный диск, и, как следствие, его надёжность сильно падает по сравнению с дисками, хранящими данные.
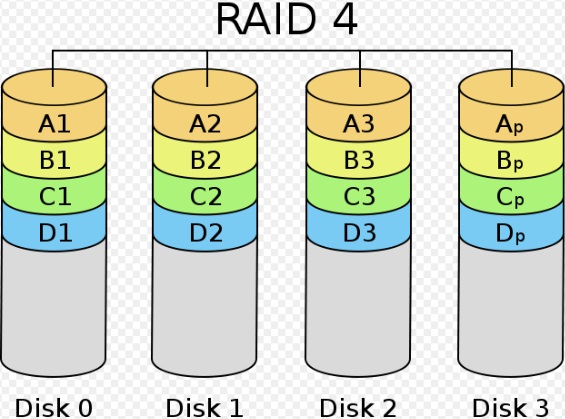
RAID 4: Внутригрупповой параллелизм
- Подробности
- Родительская категория: Память. Верхний уровень
- Категория: Дисковые массивы и уровни RAID(RAID массивы)
RAID уровня 4 повышает производительность передачи небольших объемов данных за счет параллелизма, давая возможность выполнять более одного обращения по вводу/выводу к группе в единицу времени. Логические блоки передачи в данном случае не распределяются между отдельными дисками, вместо этого каждый индивидуальный блок попадает на отдельный диск.
Достоинство поразрядного расслоения состоит в простоте вычисления кода Хэмминга, что необходимо для обнаружения и исправления ошибок в системах уровня 2. В RAID уровня 3 обнаружение ошибок диска с точностью до сектора осуществляется дисковым контроллером. Следовательно, если записывать отдельный блок передачи в отдельный сектор, то можно обнаружить ошибки отдельного считывания без доступа к дополнительным дискам. Главное отличие между системами уровня 3 и 4 состоит в том, что в последних расслоение выполняется на уровне сектора, а не на уровне битов или байтов.
В системах уровня 4 обновление контрольной информации реализовано достаточно просто. Для вычисления нового значения четности требуются лишь старый блок данных, старый блок четности и новый блок данных:
новая четность = (старые данные xor новые данные) xor старая четность
В системах уровня 4 для записи небольших массивов данных используются два диска, которые выполняют четыре выборки (чтение данных плюс четности, запись данных плюс четности). Производительность групповых операций записи и считывания остается прежней, но при небольших (на один диск) записях и считываниях производительность существенно улучшается. К сожалению, улучшение производительности оказывается недостаточной для того, чтобы этот метод мог занять место системы уровня 1.