
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Процессоры
Процессоры
От Pentium до Pentium II
- Подробности
- Родительская категория: Процессоры
- Категория: Развитие процессоров Intel Pentium
Процессор Pentium
Родоначальником обширного семейства под общим названием Pentium (Pentium, Pentium MMX, Pentium II, Pentium III, Pentium 4) стал процессор с индексом Р5, оснащенный интерфейсом Socket 4, чье производство началось в 1993 г. В том же году произошел переход на ядро Р54С с интерфейсом Socket 5, позднее — Socket 7. Линейка процессоров собственно Pentium включала модели с рабочими частотами 75-200 МГц. Процессоры производились с использованием различных технологических норм. Модели с частотами 75-120 МГц выполнены по 0,5-микронной технологии, а процессоры с частотами 120-200 МГц — по 0,35-микронной. Ядро Р54С содержит 3,3 миллиона транзисторов, 16 Кбайт кэш-памяти первого уровня. Кэш-память второго уровня объемом до 1024 Кбайт размещалась на системной плате. Процессоры семейства Pentium имеют следующие основные особенности:
• суперскалярная (два конвейера) архитектура;
• динамическое предсказание ветвлений;
• модуль конвейерной обработки операций с плавающей запятой; меньшее время исполнения инструкций;
• раздельная кэш-память для данных и для инструкций (по 8 Кбайт);
• протокол обратной записи в кэш данных;
• 64-битная шина данных;
• конвейер циклов на шине;
• контроль четности адресов;
• внутренняя проверка четности;
• контроль функциональной избыточности;
• контроль исполнения;
• мониторинг производительности;
• режим управления системой (System Management Mode);
• расширение виртуальных режимов;
• интеллектуальное управление потреблением энергии (SL);
• встроенный API (прикладной программный интерфейс).
Процессор Pentium MMX
Процессоры Pentium (ядро Р55С) с технологией MMX (Multi Media extension) стали существенным шагом вперед в семействе Pentium. В основе технологии ММХ лежит метод SIMD (Single Instruction — Multiple Data), который позволяет увеличить производительность широкого набора мультимедийных приложений. Pentium MMX поддерживал 57 новых инструкций и четыре новых 64-разрядных типа данных. Производство Pentium MMX по технормам 280 нм развернулось в 1997 г.
Кэш данных и кэш команд в Pentium MMX имеют объем по 16 Кбайт каждый. Разделение кэша увеличивает производительность, сокращая среднее время доступа к памяти и обеспечивая быстрый доступ к часто используемым инструкциям и данным. Кэш данных поддерживает два обращения одновременно, метод обратной записи (Write—back) или построчной сквозной записи (Writethrough). Динамическое предсказание ветвления использует буфер адреса перехода Branch Target Buffer (BTB), который предсказывает наиболее вероятный набор инструкций для исполнения. Для повышения производительности была добавлена дополнительная стадия конвейерной обработки. Запись в память происходит через область, состоящую из четырех буферов, которые используются совместно двумя конвейерами. Основные характеристики процессора:
• 4,5 миллиона транзисторов;
• кэш-память L2 объемом до 1024 Кбайт на системной плате;
• 64-разрядная шина данных;
• контроль целостности данных;
• встроенный контроллер прерываний микропроцессора;
• контроль производительности и отслеживание исполнения;
• улучшение страничного обмена;
• управление мощностью с помощью SL-технологии;
• суперскалярная архитектура с возможностью параллельного исполнения двух целочисленных инструкций за один такт.
Конвейерный блок вычислений с плавающей запятой (FPU) поддерживает 32- и 64-битные форматы. Это дает возможность исполнения в одном такте двух инструкций с плавающей запятой. Многие инструкции, требовавшие микрокода в процессорах х86, теперь аппаратно встроены в процессор для обеспечения высокой производительности. Контрольные сигналы шины управляют согласованием кэш-памяти в мультипроцессорных системах.
Встроенный контроллер прерываний микропроцессора обеспечивает симметричную многопроцессорную обработку с минимальными затратами. Впервые встроена аппаратная поддержка виртуальных прерываний. Проводится идентификация ядра процессора для получения информации о семействе, модели и характеристиках процессора с помощью команды CPUID. Определение ошибок внутренних устройств и интерфейса шины обеспечивает система защиты контроля четности и Machine Check Exception (MCE). Также обеспечивается аппаратная поддержка для проверки завершения цикла шины.
Процессор Pentium II
Процессор Pentium II на ядре Klamath начали выпускать в 1997 г. по технологическим нормам 350 нм. Ядро размещалось в новом конструктиве — картридже с односторонним контактом (Single Edge Contact — SEC), насчитывающим 242 контакта. Высокая интеграция данных и надежность обеспечивались шиной памяти и системной шиной с поддержкой ЕСС, механизмом анализа отказов, функцией восстановления и проверкой функциональной избыточности. Кэш-память второго уровня объемом 512 Кбайт располагалась на плате процессора и работала на половинной частоте.
В 1998 г. начался выпуск Pentium II на ядре Deschutes по технормам 250 нм. Семейство процессоров Intel Pentium II включало модели с тактовыми частотами 233-450 МГц. Существенное увеличение производительности процессоров Pentium II по сравнению с предыдущими процессорами архитектуры Intel основано на сочетании технологии Pentium Pro с поддержкой новых инструкций ММХ. Укажем некоторые особенности архитектуры Pentium II:
• число транзисторов 7,5 миллионов;
• множественное предсказание ветвлений, предугадываются несколько направлений ветвлений программы;
• анализ потока данных. В результате анализа зависимости инструкций друг от друга процессор разрабатывает оптимизированный график их выполнения;
• спекулятивное исполнение. Процессор исполняет инструкции в соответствии с оптимизированным графиком загрузки блоков АЛУ;
• полная поддержка технологии ММХ.

Архитектура двойной независимой шины (системная шина и шина кэша) обеспечивает повышение пропускной способности и производительности, а также масштабируемость при использовании более одного процессора. Системная шина поддерживает множественные транзакции, что повышает пропускную способность. Производительность повышается и за счет использования выделенной 64-разрядной шины кэш-памяти. Процессор имеет раздельный кэш первого уровня (16 + 16 Кбайт). Конвейерный блок вычислений с плавающей запятой (FPU) поддерживает 32- и 64-разрядные форматы данных, а также формат 80 бит. Контроль четности сигналов адресации запроса и ответа системной шиныс возможностью повторения обеспечивает высокую надежность и интеграцию данных.
Технология ЕСС (Error Correction Code) позволяет корректировать однобитные и выявлять двухбитные ошибки системной шины. Встроенный Self Test (BIST) обеспечивает те же функции, что и в Pentium ММХ. Встроенные счетчики производительности обеспечивают управление производительностью и подсчет событий.
В результате целенаправленной политики Intel по разделению секторов рынка персональных компьютеров в 1998 г. появились процессоры Celeron, основанные на архитектуре Pentium II. Первые модификации (с ядром Covington) не имели кэш-памяти второго уровня, поэтому отставали в производительности от Pentium II, но отличались прекрасной разгоняемостью. Процессоры Celeron с ядром Mendocino получили кэшпамять второго уровня объемом 128 Кбайт. В 1999 г. на смену процессору Pentium II (Deschutes) пришел Pentium III на новом ядре Katmai, которое получило блок SSE (Streaming SIMD Extensions), расширенный набор команд ММХ и усовершенствованный механизм потокового доступа к памяти. Процессор насчитывал 9,5 миллионов транзисторов и выпускался по технормам 250 нм с интерфейсом Slot 1. Кэш второго уровня, размещенный в ядре, имел объем 512 Кбайт.
От Willamette до Prescott
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура процессоров Pentium 4
Не секрет, что производительность любого процессора можно определить как произведение рабочей частоты ядра на число операций за такт. Очевидно, что чем больше каждый из множителей, тем больше произведение. Чисто теоретически наращивать производительность можно как за счет роста частоты, так и количества исполняемых за такт команд. Однако на практике эти два параметра связаны сложной обратно пропорциональной зависимостью.
Увеличение числа исполняемых за такт команд требует специального дизайна ядра, сложного анализа взаимозависимостей команд, что ведет к резкому повышению числа логических элементов в ядре. Серьезным препятствием служит сам код программ, ограничивающий распараллеливание используемых алгоритмов.
Для повышения рабочей частоты ядра требуется оптимизировать дизайн таким образом, чтобы на каждой стадии работы процессора выполнялось примерно одинаковое количество операций. В противном случае наиболее нагруженный элемент становится тормозом, не давая наращивать частоту. Рост частот всегда ведет к повышению тепловыделения. Поэтому архитектура процессора, реализованная согласно текущим технологическим нормам, имеет верхний предел рабочих частот. Например, для процессора Pentium 4 на ядре Northwood (технорма 130 нм) верхним пределом стала частота 3,4 ГГц. Дальнейший «разгон» стал возможен с переходом на более жесткие технологические нормы 90 нм в ядре Prescott. Но этот источник увеличения производительности не бесконечен. Например, ядро Prescott позволило поднять частоту всего до 3,8 ГГц.
Вообще при развитии архитектуры процессоров х86 корпорация Intel стремилась увеличить как количество команд, исполняемых за такт, так и рабочую частоту ядра. Каждое новое поколение процессоров (80286, 80386, 80486, Pentium, Pentium Pro) могло исполнять больше команд за такт, чем предыдущее. При этом с улучшением технологического процесса обычно росла и частота процессоров. Другими словами, постепенно увеличивались оба множителя, что приводило к быстрому росту производительности. Так продолжалось до тех пор, пока частотный потенциал микроархитектуры Р6 не был практически исчерпан, то есть до частоты 1400 МГц. Вершиной развития этой микроархитектуры стал процессор Pentium III-S. Хотя его уровень производительности был весьма достойным, по многим параметрам он уступал процессорам Athlon компании AMD.
На смену Р6 пришла архитектура NetBurst процессора Pentium 4, ознаменовавшая изменение приоритетов в разработке ядра. Усилия были сосредоточены на том, чтобы при одинаковом с Р6 технологическом процессе получить более высокие рабочие частоты. С маркетинговой точки зрения это был правильный выбор. Пользователи, убежденные в том, что «больше» означает «лучше», проголосовали кошельком за новые приоритеты. Началась гонка за мега- и гигагерцы, в которой Pentium 4 однозначно положил на обе лопатки сначала Athlon, а затем Athlon ХР. Развитие идеологии NetBurst можно проследить по микроархитектуре сменявших друг друга ядер Willamette, Northwood и Prescott.
На блок-схеме ядра Willamette представлены основные функциональные блоки процессора.
(1) Исполнительный участок (Back End) с исполнительными устройствами и обслуживающими их элементами.
(2) Подготовительный участок (Front End) с устройствами, отвечающими за декодирование инструкций и своевременную их подачу на исполнительный участок. Сюда же входит группа устройств, обеспечивающих некоторые специфические возможности: блок предварительной выборки (Prefetch), блок предсказания переходов (Branch Prediction Unit).
(3) Подсистема памяти (Memory Subsystem), управляющая загрузкой и подачей данных на участки.
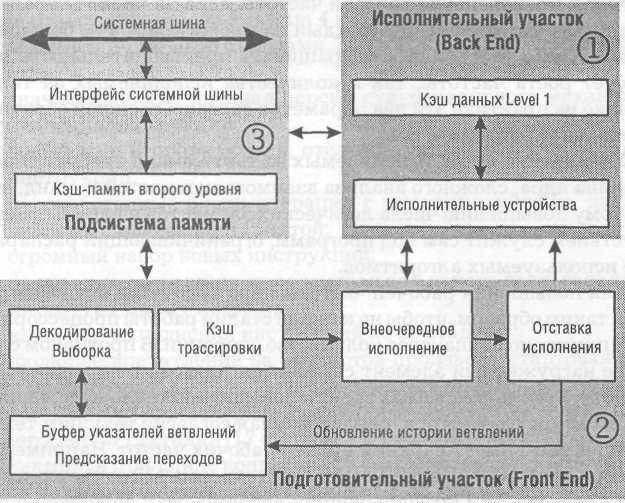
Блок-схема ядра Willamette
Интерфейс Socket A (Socket 462)
- Подробности
- Родительская категория: Процессоры
- Категория: Развитие процессоров AMD
Athlon 650 — 1400 МГц (июнь 2000 — июнь 2001)
Duron 600 — 950 МГц (июнь 2000 — июнь 2001)
Duron 900 — 1300 МГц (май 2001 — январь 2002)
Athlon XP 1500+ — 2100+ (октябрь 2001 — март 2002)
Athlon XP 1700+ — 2100+ (апрель 2002 — июнь 2002)
Athlon XP 1700+ — 2800+ (июнь 2002 — октябрь 2002)
Athlon XP 2500+ — 3200+ (январь 2003 — май 2003)
Sempron 2200+ — 3000+ (с июня 2004)
В рассматриваемый период ни один другой интерфейс процессора не продержался в производстве так долго, как Socket А. Появление этого интерфейса стало возможным благодаря переводу производства на технормы 180 нм, что, в свою очередь, позволило применить компактную упаковку ядра в керамическом корпусе.
Модель Athlon XP с ядром Palomino, помимо технологических новшеств, обеспечила поддержку расширенного набора инструкций SSE фирмы Intel. С переходом на технологические нормы 130 нм появилось ядро Thoroughbred, а с внедрением системной шины 333 МГц — ядро Thoroughbred В.
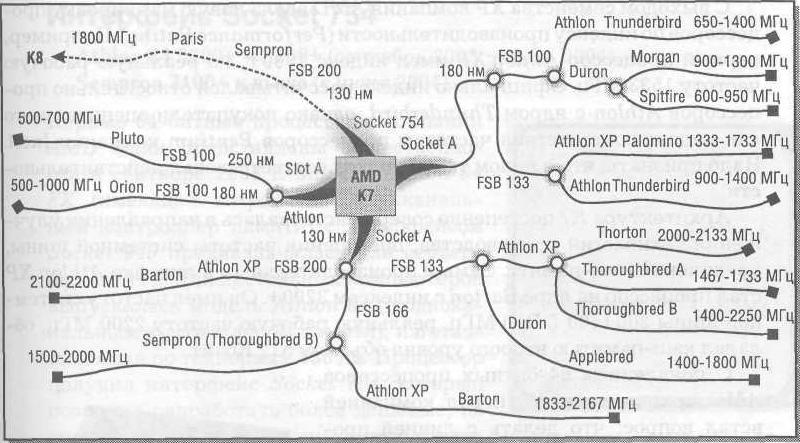
Генеалогия процессоров архитектуры AMD K7
В 2000 г. на рынке появились дешевые варианты Athlon, выполнен- ные в плоском пластиковом корпусе, под штырьково-контактный разъем Socket А. Новинка получила название Duron и была призвана стать альтернативой процессорам Celeron фирмы Intel. Хотя Duron имеет тот же объем кэш-памяти второго уровня, что и Celeron (128 Кбайт), его преимущество заключается в способности работать на системной шине 100 МГц (Celeron Socket 370 работал только на шине 66 МГц). Причем передача данных по шине памяти по обоим фронтам сигнала эмулирует результирующую частоту 200 МГц. Ядро Thunderbird обеспечило рабочие частоты процессора Athlon до 1400 МГц при тепловой мощности до 72 Вт.
ные в плоском пластиковом корпусе, под штырьково-контактный разъем Socket А. Новинка получила название Duron и была призвана стать альтернативой процессорам Celeron фирмы Intel. Хотя Duron имеет тот же объем кэш-памяти второго уровня, что и Celeron (128 Кбайт), его преимущество заключается в способности работать на системной шине 100 МГц (Celeron Socket 370 работал только на шине 66 МГц). Причем передача данных по шине памяти по обоим фронтам сигнала эмулирует результирующую частоту 200 МГц. Ядро Thunderbird обеспечило рабочие частоты процессора Athlon до 1400 МГц при тепловой мощности до 72 Вт.
Новый интерфейс дружно поддержали производители системных плат (VIA, SiS, АН, nVIDIA, ATI), представившие множество моделей чипсетов для Socket А. Одним из выдающихся представителей стал чипсет VIA КТ133, В связке С которым процессор Athlon достигал наилучшей производительности.
На рисунке: Процессор Athlon XP 2100 -->
С выходом семейства ХР компания AMD ввела новую маркировку процессоров по индексу производительности (Performance Rating). Например, первый процессор Athlon ХР имел индекс 1800+, но реальную рабочую частоту 1533 МГц. Официально индекс рассчитывался относительно процессоров Athlon с ядром Thunderbird, однако покупатели оценивали его как индекс соответствия частотам процессоров Pentium компании Intel. Надо признать, что в целом такой подход соответствовал действительности.
Архитектура К7 постепенно совершенствовалась в направлении улучшения технологий производства, повышения частоты системной шины, увеличения кэш-памяти. Самым производительным в линейке Athlon ХР стал процессор на ядре Barton с индексом 3200+. Он имел частоту системной шины 200 (400 DDR) МГц, реальную рабочую частоту 2200 МГц, обладал кэш-памятью второго уровня объемом 512 Кбайт.
С появлением 64-битных процессоров AMD архитектуры К8 перед компанией встал вопрос: что делать с линией процессоров Athlon ХР для Socket А. Их производительность практически не уступает соответствующим процессорам Pentium 4 и однозначно превосходит Celeron D. Но интерфейс Socket А уже не отвечает современным задачам.
AMD архитектуры К8 перед компанией встал вопрос: что делать с линией процессоров Athlon ХР для Socket А. Их производительность практически не уступает соответствующим процессорам Pentium 4 и однозначно превосходит Celeron D. Но интерфейс Socket А уже не отвечает современным задачам.
На рисунке: Процессор AMD Sempron Socket A -->
После недолгих размышлений компания объявила следующее решение: процессоры Athlon ХР последних модификаций (на ядрах Thoroughbred-В, Thorton и Barton) переименовываются в Sempron, процессоры Duron снимаются с производства, разработка новых моделей процессоров для Socket А прекращается. Таким образом, пользователям предоставляется достаточно времени для постепенного сворачивания эксплуатации платформы Socket А и принятия решения о переходе на 64-битную платформу.
Процессоры архитектуры К8 превосходят Athlon XP (Sempron) в работе с 32-битными приложениями, но не настолько, чтобы немедленно бежать в магазин. Важную роль в принятие решения о смене платформы будут играть новые интерфейсы, которые не поддерживаются платформой Socket А. Производителям невыгодно разрабатывать чипсеты для устаревшей платформы Socket А с поддержкой современных технологий PCI Express, DDR2 SDRAM, Wi-Fi и прочих. Поэтому новых наборов системной логики для Socket А не появится.
Кэш-память
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура AMD K7
Важнейшим компонентом, определяющим производительность микропроцессора, являются характеристики внешнего кэша второго уровня и внешней системной шины процессора. Выделенная шина между К7 и кэшем второго уровня имеет ширину 64 разряда плюс 8 разрядов на под- держку кодов ЕСС. Теоретически максимальная емкость кэша второго уровня в К7 составляет 8 Мбайт. Использование в реальных процессорах Athlon кэша второго уровня емкостью 512 Кбайт в определенном смысле наиболее эффективно, поскольку интегрированный в К7 контроллер кэша второго уровня содержит полные теги для кэша емкостью 512 Кбайт, а при большей ёмкости кэша контроллер будет содержать только часть тега.
Декодеры и конвейеры
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура AMD64
Процессор архитектуры К8 получил совершенно новый декодер х86-команд, что обусловлено необходимостью обработки инструкций AMD64, поддерживающих 64-битные приложения. Не секрет, что внутренняя система команд современных процессоров х86 разительно отличается от внешней. Внешние команды для любого х86-процессора одинаковы. Но практически одинаковый программный код внутри процессоров раскладывается на совершенно разные простые инструкции, что хорошо заметно при сравнении архитектуры К8 и Pentium 4.
Инженеры AMD и Intel выбрали различные пути достижения максимальной производительности. В концепции Intel преимущество отдано решениям, облегчающим повышение рабочей частоты процессора. В концепции AMD выражена приверженность к увеличению числа исполняемых за такт инструкций. Понятно, что различия между микропроцессорными архитектурами этих фирм напрямую следуют из концепции, закладываемой в архитектуру.
В архитектуре Pentium 4 базовая концепция основана на переводе х86-инструкций в более регулярные, «RISC-подобные» микрооперации фиксированной длины. Процессор старается держать как можно больше «переведенных» команд в Trace Cache, который хранит до 12 000 микроопераций. Декодеры работают асинхронно с исполнительными конвейерами. Естественно, что подготовленные микроинструкции исполняются более эффективно и с большим темпом, нежели нерегулярные и весьма разнообразные по форме х86 -инструкции.
В архитектуре К8 информация о границах очередной инструкции записывается в специальный массив Decode Array. Сама инструкция под вергается дальнейшим преобразованиям во внутренний формат. Каждому байту х86-инструкции, находящейся в кэше команд, соответствуют три бита, хранящиеся в Decode Array. Эта запись содержит информацию о том, является ли данный байт первым (последним) байтом инструкции, является ли он префиксом, следует ли направлять инструкцию по особому пути декодирования.
Таким образом, Pentium 4 сохраняет результат работы декодера (микрооперацию), а К8 — полезную информацию, существенно облегчающую повторное декодирование. Отсюда следует, что для того чтобы система К8 могла использовать все преимущества большого кэша команд, она должна обладать совершенным механизмом повторного декодирования. Такой механизм реализован в декодере следующим образом.
Внешние инструкции на завершающих этапах работы декодера «переводятся» в специальные внутренние команды — макрооперации (тОР). Большинству х86-инструкций соответствует одна макрооперация, некоторые инструкции преобразуются в две или три тОР, а наиболее сложные, например деление или тригонометрические функции, — в последовательность из нескольких десятков тОР. Макрооперации имеют фиксированную длину и регулярную структуру.
Макрооперация в определенный момент раскладывается на две простейшие микрооперации (ROP), одновременно посылаемые на исполнение функциональным элементам процессора (ALU или FPU). Для этого тОР содержит всю необходимую для запуска двух команд информацию, включая служебную. Объединение ROP в макрооперации позволяет сократить количество перемещаемых блоков данных и число промежуточных операций записи/считывания результата. При этом ROP направляются на исполнение в том порядке, который окажется наиболее удобным, а не в том, какой задан в выполняемой программе. Поэтому нередки ситуации, когда ROP выполняются вперемешку, безотносительно к их принадлежности одному тОР.
Если добавить параллельные каналы, то на каждый можно направить по макрооперации. В процессорах архитектуры К8 используется три симметричных канала, каждый из которых имеет пару функциональных устройств. В результате одновременно работают сразу шесть функциональных устройств. Каждый канал разветвляется: в зависимости от того, какие значения обрабатывает инструкция, тОР пойдет либо по направлению к целочисленным блокам, либо — к блокам обработки действительных чисел, либо на блок вычисления адреса (AGU). То есть в архитектуре К8 имеется десять функциональных устройств: три ALU, три FPU, три AGU (вычисления адреса) и отдельный блок умножения.
Группировка операций продолжается и на более высоком уровне.
Группу образуют три тОР, которые одновременно запускаются на параллельных каналах. Вся дальнейшая работа идет с «тройками» тОР, образующих «линию» (Line). Такая «линия» воспринимается центральным управляющим блоком процессора как единое целое: все основные действия выполняются именно над группой «Line». Так, под «линию» одним приемом выделяется группа из трех позиций в очередях (как мы помним, у каждого канала своя очередь). Точно так же одновременно происходит освобождение ресурсов после исполнения, сопровождающееся окончательной записью результатов в регистры. Эту архитектуру компания AMD характеризует как «line-oriented», она является предметом законной гордости корпорации и принципиально отличается от архитектуры Pentium 4.
Подкатегории
-
Разъемы процессоров
- Кол-во материалов:
- 1
-
Развитие процессоров Intel Pentium
- Кол-во материалов:
- 5
-
Архитектура процессоров Pentium 4
- Кол-во материалов:
- 8
-
Развитие процессоров AMD
- Кол-во материалов:
- 6
-
Архитектура AMD K7
- Кол-во материалов:
- 6
-
Архитектура AMD64
- Кол-во материалов:
- 3
-
Семейство процессоров VIA
- Кол-во материалов:
- 2
-
Семейство процессоров Transmeta
- Кол-во материалов:
- 2
-
Производство процессоров
- Кол-во материалов:
- 5
-
Принципиальное устройство процессора
- Кол-во материалов:
- 4