
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Процессоры
Процессоры
Принцип работы архитектуры NetBurst
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура процессоров Pentium 4
В самом упрощенном представлении процессор состоит из ядра и подсистемы памяти. Собственно ядро можно представить в виде комбинации двух участков: подготовительного Front End и исполнительного Back End. При этом первый участок отвечает за снабжение второго материалом для работы. Модуль Back End содержит исполнительные устройства процессора. Это именно та часть процессора, которая «считает», плюс обслуживающая ее логика.
Алгоритм работы процессора в грубом приближении выглядит так: подсистема памяти снабжает ядро данными из оперативной памяти, подготовительный участок приводит их к удобоваримому виду и передает на исполнительный участок для обработки. Участок Back End ведает непосредственной обработкой этого материала. Специальная группа устройств отвечает за своевременную подачу данных и предсказание следующих переходов, то есть создает комфортные условия для функционирования остальных компонентов ядра.
На участке Back End имеется пять функциональных исполнительных устройств, каждое из которых выполняет свой перечень операций. Три устройства (два «быстрых» и одно «нормальное» АЛУ) занимаются операциями с целыми числами, два — операциями с действительными числами. Все они связаны с блоками логики, которые подготавливают данные, передают операнды, считывают данные из регистров — в общем, выполняют ту работу, без которой нельзя произвести вычисления. Несколько обособленны два устройства вычисления и загрузки адресов.
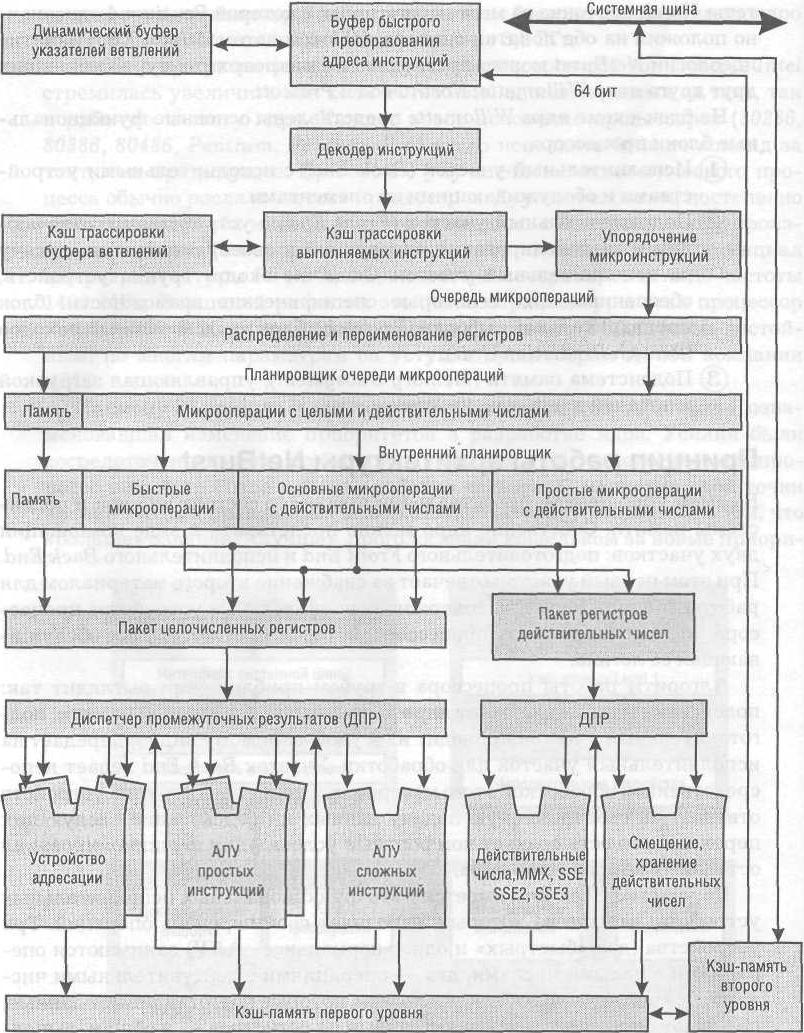
Микроархитектура ядра Prescott процессора Pentium 4
Рассмотрим алгоритм выполнения простейшей операции: увеличения значения регистра на пять. Для этого необходимо выполнить ряд действий:
1. Взять содержимое регистра «X».
2. Взять число 5.
3. Отправить два числа и код операции «сложение» на исполнительное устройство.
4. Выполнить сложение.
5. Записать результат в регистр «X».
Из пяти перечисленных действий исполнительные устройства заняты только в одном (четвертым по порядку). Все подготовительные работы выполняет обслуживающая логика. Исполнительные же блоки принимают числа и код операции, производят саму операцию и выдают числовой результат. Их задача важна, но без обслуживающей логики они бессильны. Рассмотрим более сложную операцию: надо сложить содержимое регистров «X» и «Y», а также увеличить содержимое регистра «Z» на пять. Безусловно, можно выполнить операции по очереди, что займет довольно много времени. Но если поставить параллельно первому второе исполнительное устройство, то работу можно сделать вдвое быстрее.
Такая архитектура называется суперскалярной, что означает возможность исполнять более чем одну операцию за такт. Предположим, что второе задание предусматривает увеличение на единицу регистра «Y». Тогда процессор вынужден ждать, пока завершится первая операция, несмотря на то, что второе исполнительное устройство совершенно свободно. Таким образом, логика, обслуживающая исполнительные устройства, должна определять, есть ли взаимозависимости в заданиях или же их можно выполнять параллельно. Данная задача также возложена на участок Back End.
Для повышения производительности выгоднее как можно больше операций исполнять параллельно. Если подходящих операций не найдено в данном участке кода, можно пропустить несколько микроопераций с еще не готовыми операндами и далее выполнять только такие инструкции, изменение порядка которых не приведет к изменению результата. Такая технология называется Out-of-Order Execute (внеочередное исполнение).
Представим, что код программы содержит некоторое количество заданий. Причем выполняться они должны в определенной последовательности, потому что часть из них зависит от результатов предыдущих операций. А часть — не зависит. Некоторые задания ожидают поступления данных из памяти. Есть два варианта решения проблемы: либо ждать, пока все задания не будут выполнены поочередно, согласно последовательному коду программы, либо попытаться выполнить ту часть работы, для которой есть все необходимое. Разумеется, все задания выполнить «вне очереди» не удастся, но выполнение хотя бы части из них сэкономит некоторое количество времени.
Для решения такой задачи принципиально необходимы некоторые устройства. В первую очередь нужен буфер, в котором накапливаются задания. Из буфера устройство под названием планировщик (Sheduler) выбирает те задания, которые уже снабжены операндами и могут быть выполнены немедленно. Предварительно планировщик сортирует задания на те, которые можно исполнять вне очереди, и те, которые требуютп редыдущих результатов.
Полученные промежуточные данные необходимо куда-то записывать. Для этого предназначены служебные регистры. В частности, процессор Pentium 4 имеет 128 служебных регистров. Поскольку любая программа для платформы х86 не подозревает о существовании более чем 8 регистров общего назначения (РОН), надо, чтобы служебные регистры могли «притворяться» РОН. Этим занимается блок переименования регистров. Он берет первый попавшийся свободный служебный регистр и представляет его программе как «дозволенный» регистр общего назначения. Так результаты внеочередных операций записываются в «черновик» — служебные регистры. После выполнения очередных операций поступают «внеочередные» результаты из «черновика» и размещаются в РОН согласно порядку, указанному в программе.
Раскладка операций на составляющие позволяет упростить каждую стадию конвейера, уменьшить число логических элементов и тем самым повысить рабочую частоту ядра. Но инструкции CISC платформы х86 имеют нерегулярную структуру: разную длину, разное количество операндов и даже разный синтаксис. Две инструкции одинаковой длины могут содержать команды, отличающиеся по трудоемкости на порядок. В конвейер же надо подавать простые микрооперации, имеющие регулярную структуру: одинаковую длину, стандартное расположение операндов и служебных меток, примерно равную сложность исполнения. Упрощением и выравниваем инструкций занимается декодер, преобразующий инструкции CISC в микрооперации RISC.
Интерфейс Socket 754
- Подробности
- Родительская категория: Процессоры
- Категория: Развитие процессоров AMD
Athlon 64 3200+ — 3700+ (сентябрь 2003 — июнь 2004)
Sempron 3100+ и выше (с июня 2004)
Первые 64-битные процессоры компании AMD были представлены общественности в сентябре 2003 г. Модель Athlon 64 FX (имеющая встроенный двухканальный контроллер памяти) с интерфейсом Socket 940 предназначалась для серверных систем. Для настольных компьютеров выпускалась модель Athlon 64 (с одноканальным контроллером памяти), изготавливаемая по технормам 130 нм. Процессор получил интерфейс Socket 754, который позволил разработать более дешевые, по сравнению с Socket 940, системные платы. Первая модификация Athlon 64
AMD были представлены общественности в сентябре 2003 г. Модель Athlon 64 FX (имеющая встроенный двухканальный контроллер памяти) с интерфейсом Socket 940 предназначалась для серверных систем. Для настольных компьютеров выпускалась модель Athlon 64 (с одноканальным контроллером памяти), изготавливаемая по технормам 130 нм. Процессор получил интерфейс Socket 754, который позволил разработать более дешевые, по сравнению с Socket 940, системные платы. Первая модификация Athlon 64
Socket 754 на ядре ClawHammer имела кэш-память второго уровня объемом 1 Мбайт. Вторая модификация на ядре NewCastle получила кэш L2 объемом 512 Кбайт. После прекращения выпуска Athlon 64 Socket 754 для поддержки интерфейса был выпущен процессор Sempron 3100+ Socket 754 на ядре Paris. Он представляет собой значительно урезанное ядро NewCastle: отсутствует поддержка технологии AMD64, объем кэш-памяти второго уровня уменьшен до 256 Кбайт.Тем неменее, сохранена поддержка инструкций SSE и технологии дина мического управления частотой Cool-and-Quiet.
Процессоры с интерфейсом Socket 754 имеют одноканальный контроллер памяти DDR4 00, оснащены шиной HyperTransport с частотой 300 МГц. Существует три чипсета с поддержкой Socket 754: nVIDIA nForce3 150/-250, VIA K8T800, SiS 755FX.
Многопроцессорность
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура AMD K7
В микроархитектуре К7 инженеры AMD впервые ввели поддержку SMP-архитектур. Протокол, с помощью которого поддерживается когерентность кэша в К7, называется MOESI (от первых букв возможных состояний кэша — Modify, Owner, Exclusive, Shared, Invalid). По утверждению AMD, этот протокол был впервые реализован в х8б-совместимых процессорах.
Кэш первого уровня в К7 имеет отдельный порт, через который проходит трафик, обусловленной поддержкой когерентности. Трафик поддержки когерентности кэша также отделен от основного трафика и на системной шине. Естественно, что обособление повышает эффективную пропускную способность шины, и следовательно, эффективность SMP-конфигураций.
Контроллер памяти
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура AMD64
Интегрированный контроллер памяти микроархитектуры К8 — уникальное явление среди процессоров для настольных систем. Во всех остальных вариантах (Pentium 4, Celeron, Pentium M, AthlonXP, Sempron) контроллер памяти размещается в микросхеме набора системной логики. Внедрение контроллера в архитектуру процессора позволило лучше согласовать возможности процессорного ядра и памяти. В оптимальном варианте пропускная способность памяти должна быть больше максимального потока данных, обрабатываемых процессором, а задержки (латентность) памяти должны быть минимальными.
Что касается пропускной способности, то процессор Athlon 64 (Socket 939) с частотой 1400 МГц в 32-битном режиме выдает «на гора» поток данных до 5,6 Гбайт/с. Двухканальная память DDR400 обеспечивает пропускную способность 6,4 Гбайт/с. В этом аспекте проблем не возникает. Но каковы задержки обращения к памяти? Оказывается, всего 65 тактов. То есть время доступа к памяти составляет 33 наносекунды. Это намного меньше показателей, демонстрируемых классическими чипсетами с интегрированным контроллером памяти. Например, платформа Pentium 4 + i925 + dual channel DDR400, самая быстрая среди конкурентов, обеспечивает время доступа к памяти 63 наносекунды.
Благодаря небольшим задержкам контроллер процессора Athlon 64 обеспечивает эффективность памяти до 96% от теоретической пропускной способности, что с лихвой покрывает потребности платформы. В целом эффективность встроенного контроллера можно охарактеризовать как великолепную. Впервые архитектура процессоров AMD обеспечивает равные или лучшие по сравнению с процессорами Intel показатели эффективности памяти.
Процессор Crusoe
- Подробности
- Родительская категория: Процессоры
- Категория: Семейство процессоров Transmeta
Фирма Transmeta длительное время интриговала компьютерное сообщество по поводу своего процессора Crusoe. Детище Transmeta называли «убийцей» бюджетного процессора Intel Celeron. Однако вышедшие в январе 2000 г. модели ТМ3120 и ТМ5400 разочаровали любителей сенсаций. Архитектура этих процессоров действительно необычна: всего пять блоков вычислений, использование сверхдлинных инструкций VLIW, интеграция северного моста системного чипсета на процессоре. «Transmeta делает простое железо, которое опирается на хитрое программное обеспечение, так что элементарный процессор кажется гораздо более сложным — например, стандартным Intel-совместимым х86. А чем меньше и проще становится железо, тем меньше транзисторов содержит процессор, а, следовательно, он потребляет меньше энергии...»— так писал о продукции компании Transmeta небезызвестный Линус Торвальдс, «отец» операционной системы Linux.
Архитектура VLIW получила дальнейшее развитие в 2002 г. в процессорах серии ТМ5700/5800/5900. Инструкции длиной 128 бит обрабатываются в конвейере длиной 7 ступеней с производительностью до 4 операций за такт. Конвейер для чисел с плавающей точкой имеет длину 10 ступеней. Обеспечена поддержка инструкций ММХ. Кэш-память первого уровня занимает 128 Кбайт, кэш-память второго уровня до 512 Кбайт (ТМ5900). Микросхема помимо ядра процессора содержит контроллеры памяти (DDR266) и шины PCI, что позволяет создавать компактные платформы для мобильных и настольных систем.
Рабочая частота процессора до 1000 МГц при тепловой мощности всего 9,5 Вт. Кристалл изготавливается по технормам 130 нм и упаковывается в корпус FC-OBGA с оригинальным интерфейсом Socket 399.
Подкатегории
-
Разъемы процессоров
- Кол-во материалов:
- 1
-
Развитие процессоров Intel Pentium
- Кол-во материалов:
- 5
-
Архитектура процессоров Pentium 4
- Кол-во материалов:
- 8
-
Развитие процессоров AMD
- Кол-во материалов:
- 6
-
Архитектура AMD K7
- Кол-во материалов:
- 6
-
Архитектура AMD64
- Кол-во материалов:
- 3
-
Семейство процессоров VIA
- Кол-во материалов:
- 2
-
Семейство процессоров Transmeta
- Кол-во материалов:
- 2
-
Производство процессоров
- Кол-во материалов:
- 5
-
Принципиальное устройство процессора
- Кол-во материалов:
- 4