
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Процессоры
Архитектура процессоров Pentium 4
Архитектура процессоров Pentium 4
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура процессоров Pentium 4
В ноябре 2000 г. компания Intel приступила к производству 32-разрядного процессора Pentium 4 на ядре Willamette, работающего на частоте 1,5 ГГц. Знаменательность этого события в том, что с момента выхода Pentium Pro в области архитектуры процессоров Intel не происходило ничего более значительного. С выходом Pentium 4 на свет появился процессор седьмого поколения (Pentium Pro, Pentium II/III относятся к шестому поколению — Р6).
Необходимо перечислить новшества архитектуры Willamette, позволяющие отнести процессор Pentium 4 к новому поколению:
• асимметричное ядро с блоками, работающими на различных скоростях;
• значительно улучшенная версия суперскалярного механизма исполнения инструкций;
• новый кэш второго уровня, отслеживающий порядок выполнения инструкций;
• переработанные блоки операций с мультимедийными данными и числами с плавающей запятой;
• огромный набор новых инструкций;
• новая системная шина, передающая по 4 пакета данных за такт (ар-хитектура Quad Pumped);
• конвейер выполнения инструкций из 20 стадий.
Наибольшее впечатление на экспертов произвела стартовая рабочая частота процессора в 1,5 ГГц. Такого результата удалось добиться за счет новой архитектуры конвейера выполнения инструкций. Pentium III имеет конвейер длиной 12 стадий (17 стадий FPU), Athlon — 10 стадий (15 стадий FPU). Pentium 4 при длине конвейера 20 стадий позволяет достичь максимальной тактовой частоты, но и получает самые большие задержки для связанных друг с другом операций (второй операции придется ожидать 20 тактов, пока не завершится первая операция).
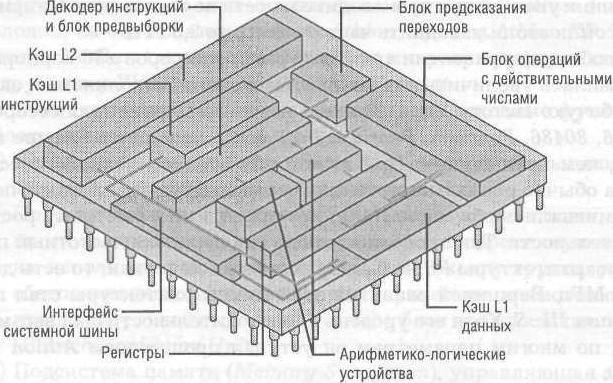
Модель архитектуры процессора Pentium 4
От Willamette до Prescott
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура процессоров Pentium 4
Не секрет, что производительность любого процессора можно определить как произведение рабочей частоты ядра на число операций за такт. Очевидно, что чем больше каждый из множителей, тем больше произведение. Чисто теоретически наращивать производительность можно как за счет роста частоты, так и количества исполняемых за такт команд. Однако на практике эти два параметра связаны сложной обратно пропорциональной зависимостью.
Увеличение числа исполняемых за такт команд требует специального дизайна ядра, сложного анализа взаимозависимостей команд, что ведет к резкому повышению числа логических элементов в ядре. Серьезным препятствием служит сам код программ, ограничивающий распараллеливание используемых алгоритмов.
Для повышения рабочей частоты ядра требуется оптимизировать дизайн таким образом, чтобы на каждой стадии работы процессора выполнялось примерно одинаковое количество операций. В противном случае наиболее нагруженный элемент становится тормозом, не давая наращивать частоту. Рост частот всегда ведет к повышению тепловыделения. Поэтому архитектура процессора, реализованная согласно текущим технологическим нормам, имеет верхний предел рабочих частот. Например, для процессора Pentium 4 на ядре Northwood (технорма 130 нм) верхним пределом стала частота 3,4 ГГц. Дальнейший «разгон» стал возможен с переходом на более жесткие технологические нормы 90 нм в ядре Prescott. Но этот источник увеличения производительности не бесконечен. Например, ядро Prescott позволило поднять частоту всего до 3,8 ГГц.
Вообще при развитии архитектуры процессоров х86 корпорация Intel стремилась увеличить как количество команд, исполняемых за такт, так и рабочую частоту ядра. Каждое новое поколение процессоров (80286, 80386, 80486, Pentium, Pentium Pro) могло исполнять больше команд за такт, чем предыдущее. При этом с улучшением технологического процесса обычно росла и частота процессоров. Другими словами, постепенно увеличивались оба множителя, что приводило к быстрому росту производительности. Так продолжалось до тех пор, пока частотный потенциал микроархитектуры Р6 не был практически исчерпан, то есть до частоты 1400 МГц. Вершиной развития этой микроархитектуры стал процессор Pentium III-S. Хотя его уровень производительности был весьма достойным, по многим параметрам он уступал процессорам Athlon компании AMD.
На смену Р6 пришла архитектура NetBurst процессора Pentium 4, ознаменовавшая изменение приоритетов в разработке ядра. Усилия были сосредоточены на том, чтобы при одинаковом с Р6 технологическом процессе получить более высокие рабочие частоты. С маркетинговой точки зрения это был правильный выбор. Пользователи, убежденные в том, что «больше» означает «лучше», проголосовали кошельком за новые приоритеты. Началась гонка за мега- и гигагерцы, в которой Pentium 4 однозначно положил на обе лопатки сначала Athlon, а затем Athlon ХР. Развитие идеологии NetBurst можно проследить по микроархитектуре сменявших друг друга ядер Willamette, Northwood и Prescott.
На блок-схеме ядра Willamette представлены основные функциональные блоки процессора.
(1) Исполнительный участок (Back End) с исполнительными устройствами и обслуживающими их элементами.
(2) Подготовительный участок (Front End) с устройствами, отвечающими за декодирование инструкций и своевременную их подачу на исполнительный участок. Сюда же входит группа устройств, обеспечивающих некоторые специфические возможности: блок предварительной выборки (Prefetch), блок предсказания переходов (Branch Prediction Unit).
(3) Подсистема памяти (Memory Subsystem), управляющая загрузкой и подачей данных на участки.
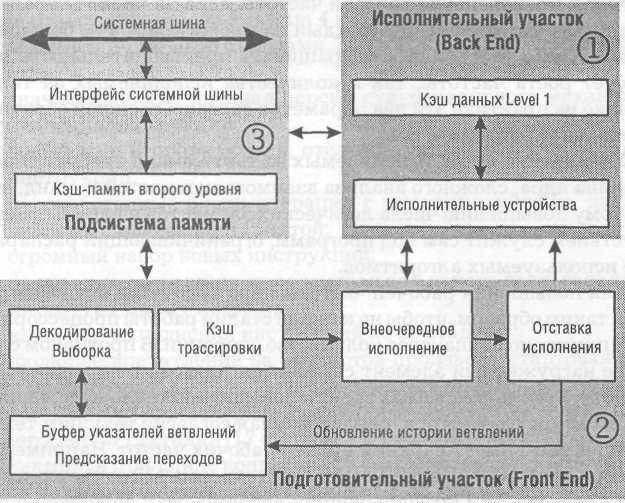
Блок-схема ядра Willamette
Принцип работы архитектуры NetBurst
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура процессоров Pentium 4
В самом упрощенном представлении процессор состоит из ядра и подсистемы памяти. Собственно ядро можно представить в виде комбинации двух участков: подготовительного Front End и исполнительного Back End. При этом первый участок отвечает за снабжение второго материалом для работы. Модуль Back End содержит исполнительные устройства процессора. Это именно та часть процессора, которая «считает», плюс обслуживающая ее логика.
Алгоритм работы процессора в грубом приближении выглядит так: подсистема памяти снабжает ядро данными из оперативной памяти, подготовительный участок приводит их к удобоваримому виду и передает на исполнительный участок для обработки. Участок Back End ведает непосредственной обработкой этого материала. Специальная группа устройств отвечает за своевременную подачу данных и предсказание следующих переходов, то есть создает комфортные условия для функционирования остальных компонентов ядра.
На участке Back End имеется пять функциональных исполнительных устройств, каждое из которых выполняет свой перечень операций. Три устройства (два «быстрых» и одно «нормальное» АЛУ) занимаются операциями с целыми числами, два — операциями с действительными числами. Все они связаны с блоками логики, которые подготавливают данные, передают операнды, считывают данные из регистров — в общем, выполняют ту работу, без которой нельзя произвести вычисления. Несколько обособленны два устройства вычисления и загрузки адресов.
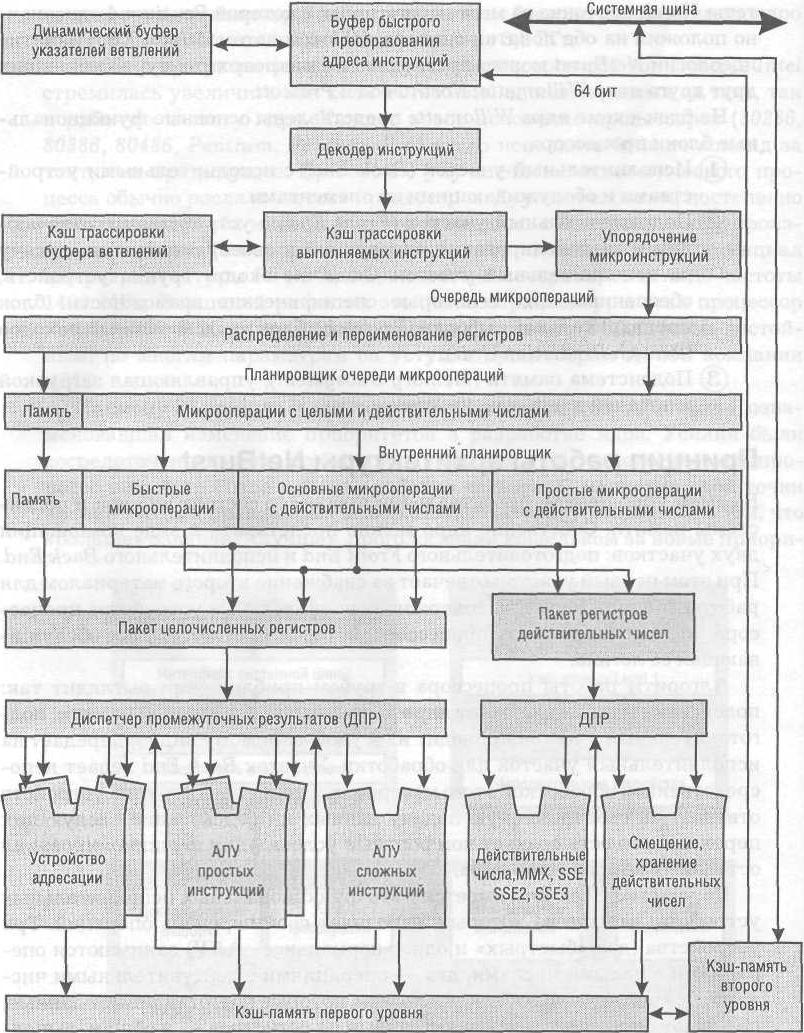
Микроархитектура ядра Prescott процессора Pentium 4
Рассмотрим алгоритм выполнения простейшей операции: увеличения значения регистра на пять. Для этого необходимо выполнить ряд действий:
1. Взять содержимое регистра «X».
2. Взять число 5.
3. Отправить два числа и код операции «сложение» на исполнительное устройство.
4. Выполнить сложение.
5. Записать результат в регистр «X».
Из пяти перечисленных действий исполнительные устройства заняты только в одном (четвертым по порядку). Все подготовительные работы выполняет обслуживающая логика. Исполнительные же блоки принимают числа и код операции, производят саму операцию и выдают числовой результат. Их задача важна, но без обслуживающей логики они бессильны. Рассмотрим более сложную операцию: надо сложить содержимое регистров «X» и «Y», а также увеличить содержимое регистра «Z» на пять. Безусловно, можно выполнить операции по очереди, что займет довольно много времени. Но если поставить параллельно первому второе исполнительное устройство, то работу можно сделать вдвое быстрее.
Такая архитектура называется суперскалярной, что означает возможность исполнять более чем одну операцию за такт. Предположим, что второе задание предусматривает увеличение на единицу регистра «Y». Тогда процессор вынужден ждать, пока завершится первая операция, несмотря на то, что второе исполнительное устройство совершенно свободно. Таким образом, логика, обслуживающая исполнительные устройства, должна определять, есть ли взаимозависимости в заданиях или же их можно выполнять параллельно. Данная задача также возложена на участок Back End.
Для повышения производительности выгоднее как можно больше операций исполнять параллельно. Если подходящих операций не найдено в данном участке кода, можно пропустить несколько микроопераций с еще не готовыми операндами и далее выполнять только такие инструкции, изменение порядка которых не приведет к изменению результата. Такая технология называется Out-of-Order Execute (внеочередное исполнение).
Представим, что код программы содержит некоторое количество заданий. Причем выполняться они должны в определенной последовательности, потому что часть из них зависит от результатов предыдущих операций. А часть — не зависит. Некоторые задания ожидают поступления данных из памяти. Есть два варианта решения проблемы: либо ждать, пока все задания не будут выполнены поочередно, согласно последовательному коду программы, либо попытаться выполнить ту часть работы, для которой есть все необходимое. Разумеется, все задания выполнить «вне очереди» не удастся, но выполнение хотя бы части из них сэкономит некоторое количество времени.
Для решения такой задачи принципиально необходимы некоторые устройства. В первую очередь нужен буфер, в котором накапливаются задания. Из буфера устройство под названием планировщик (Sheduler) выбирает те задания, которые уже снабжены операндами и могут быть выполнены немедленно. Предварительно планировщик сортирует задания на те, которые можно исполнять вне очереди, и те, которые требуютп редыдущих результатов.
Полученные промежуточные данные необходимо куда-то записывать. Для этого предназначены служебные регистры. В частности, процессор Pentium 4 имеет 128 служебных регистров. Поскольку любая программа для платформы х86 не подозревает о существовании более чем 8 регистров общего назначения (РОН), надо, чтобы служебные регистры могли «притворяться» РОН. Этим занимается блок переименования регистров. Он берет первый попавшийся свободный служебный регистр и представляет его программе как «дозволенный» регистр общего назначения. Так результаты внеочередных операций записываются в «черновик» — служебные регистры. После выполнения очередных операций поступают «внеочередные» результаты из «черновика» и размещаются в РОН согласно порядку, указанному в программе.
Раскладка операций на составляющие позволяет упростить каждую стадию конвейера, уменьшить число логических элементов и тем самым повысить рабочую частоту ядра. Но инструкции CISC платформы х86 имеют нерегулярную структуру: разную длину, разное количество операндов и даже разный синтаксис. Две инструкции одинаковой длины могут содержать команды, отличающиеся по трудоемкости на порядок. В конвейер же надо подавать простые микрооперации, имеющие регулярную структуру: одинаковую длину, стандартное расположение операндов и служебных меток, примерно равную сложность исполнения. Упрощением и выравниваем инструкций занимается декодер, преобразующий инструкции CISC в микрооперации RISC.
Технология Trace Cache
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура процессоров Pentium 4
Если команду х86 нельзя представить в виде одной простой инструкции, декодер создает некую последовательность простых инструкций (микроопераций) RISC. В процессоре Pentium 4 вместо традиционного кэша команд, в котором хранится код х86, имеется кэш трассировки (Trace Cache). Он расположен после декодера, но перед остальными блоками процессора. В нем хранятся не инструкции CISC, а результаты их декодирования — микрооперации. При такой архитектуре декодер работает независимо от остальных блоков, наполняя Trace Cache микрооперациями.

Конвейер операций процессора Pentium 4
Если в Trace Cache нет инструкций затребованного процессором участка кода, они сравнительно медленно загружаются из кэша L2, декодируясь на лету. Естественно, что декодирование и выборка данных на этом участке происходят в очередности, определяемой исполняемой программой. Микрооперации «снимаются» прямо с декодера, по мере их готовности, и результирующая скорость будет не более одной инструкции за такт. При повторном обращении к тому же участку кода процессор избавляется от необходимости производить декодирование еще раз.
В ряде случаев экономия получается весьма значительной: «длина» участка декодера в тактах составляет от 10 до 30 тактов. Емкость Trace Cache составляет 12 000 микроопераций. В среднем вероятность нахождения запрашиваемого участка кода в Trace Cache лежит в пределах 75-95%.
Предсказание переходов
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура процессоров Pentium 4
Кроме представления команд CISC в удобной для процессора форме микроархитектура ядра должна решать проблему предсказания ветвлений программы. Суть проблемы в том, что, встретив инструкцию перехода, процессор останавливает конвейер. Задержка будет тем дольше, чем больше длина конвейера.
Поэтому инструкции перехода надо выявлять заранее и реагировать соответствующим образом. Для этого предназначен специальный блок предсказания переходов (Branch Prediction Unit). Его задача — предвидеть направление перехода и, в случае удачного предсказания, сэкономить время. Соответственно, если результат предсказания будет неудачным, происходит полная остановка конвейера и очистка буферов.
Если в программе есть условные переходы (то есть такие, которые зависят от результата выполнения какой-либо операции), надо постараться «угадать», произойдет этот переход, или нет. Метод гадания на кофейной гуще здесь не подходит. Поэтому блок предсказаний хранит специальную таблицу истории переходов (Branch History Table), в которой записана результативность предыдущих примерно 4000 предсказаний. Кроме того, отслеживается точность последнего предсказания, чтобы при необходимости откорректировать алгоритм работы. Благодаря этому декодер выполняет по подсказке блока предсказания условный переход, а затем блок предсказаний проверяет, правильно ли было предсказано это условие. Микроархитектура Prefetch (предзагрузки или предвыборки) позволяет заранее знать, какие данные понадобятся процессору в будущем.
Специальные механизмы анализируют последовательности адресов, по которым происходила загрузка данных, и пытаются предугадать следующий адрес. Работает механизм предвыборки в тесном содружестве с Branch Prediction Unit и с подсистемой памяти.