
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
PCI и PCI-X
Протокол, команды и транзакции шин PCI и PCI-X
Модификация протокола в PCI-X
Протокол шины PCI-X во многом совпадает с вышеописанным: то же тактирование по перепаду CLK, то же назначение управляющих сигналов. Изменение протокола нацелено на повышение эффективности использования тактов шины. Для этого в протокол ввели дополнения, позволяющие устройствам «предвидеть» грядущие события и выбирать адекватное поведение.
В обычной PCI все транзакции начинаются одинаково (с фазы адреса) как пакетные с заранее не известной длиной. При этом реально транзакции ввода/вывода всегда имеют лишь одну фазу данных; длинные пакеты эффективны (и используются) только для обращений к памяти. В PCI-X транзакции по длине разделены на два типа:
- пакетные (Burst) — все команды, обращенные к памяти, кроме Memory Read DWORD;
- одиночные размером в двойное слово (DWORD) — остальные команды.
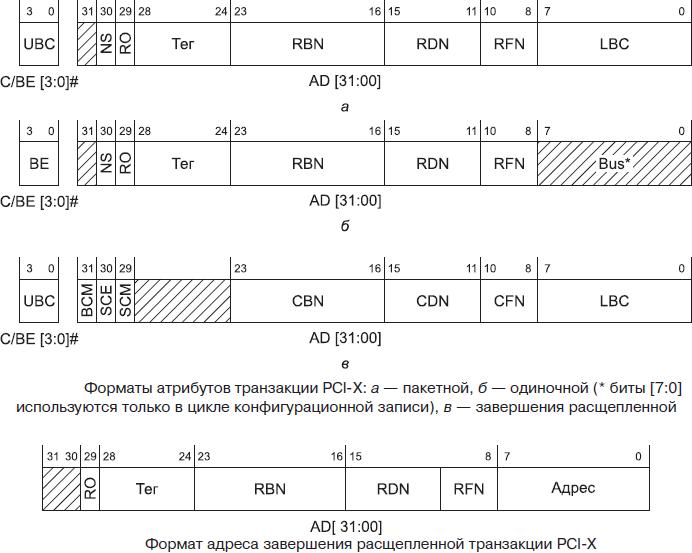
В каждой транзакции после фазы адреса присутствует новая фаза передачи атрибутов транзакции, в которой инициатор сообщает свой идентификатор (RBN — номер шины, RDN — номер устройства и RFN — номер функции), 5-битный тег, 12-битный счетчик байтов (только для пакетных транзакций, UBC — старшие биты, LBC — младшие биты) и дополнительные характеристики (биты RO и NS) области памяти, к которой относится транзакция. Атрибуты передаются по линиям шины AD[31:0] и BE[3:0]#. Идентификатор инициатора вместе с тегом определяют последовательность (Sequence) — одну или несколько транзакций, обеспечивающих одну логическую передачу данных, запланированную инициатором. Благодаря 5-битному тегу каждый инициатор может одновременно выполнять до 32 логических передач (повторное назначение тега другой логической передаче возможно только после завершения предшествующей, использовавшей то же значение тега). Логическая передача (последовательность) может иметь длину до 4096 байт (значение счетчика байтов 00…01 соответствует числу 1, 11…11 — 4095, 00…00 — 4096); в атрибутах каждой транзакции указывается число байт, которые должны быть переданы до конца данной последовательности. Количество байт, которые будут переданы в каждой транзакции, заранее не определено (транзакцию может остановить как инициатор, так и целевое устройство). Однако для повышения эффективности работы к пакетным транзакциям предъявляются жесткие требования. Если в транзакции оказывается более одной фазы данных, то она может завершаться либо по передаче всех заявленных байтов (по счетчику в атрибутах), либо только на границах строк кэша (по 128-байтным границам адресов памяти). Если участники транзакции не готовы принять такие условия, кто-то из них должен остановить транзакцию после первой фазы данных. Только у целевого устройства есть еще право аварийного завершения транзакции в любой момент; инициатор жестко обязан отвечать за свои начинания.
Байты шины AD, участвующие в транзакциях, определяются сигналами BEx#, но иначе, чем в PCI. Для одиночных транзакций эти сигналы действуют в фазе атрибутов. Для пакетных транзакций эти сигналы действуют только в команде Memory Write (в каждой фазе данных), для остальных пакетных обращений предполагается, что все байты, от начального адреса до конечного, разрешены.
Характеристики памяти, к которой относится транзакция, позволяют выбирать оптимальный способ обращения к ней при отработке транзакции. Характеристики устанавливает устройство, запрашивающее данную последовательность. Каким образом оно узнает о свойствах памяти — забота его драйвера. Атрибуты характеристики памяти относятся только к транзакциям пакетных обращений к памяти (но не к сообщениям MSI):
- флаг RO (Relaxed Ordering) означает, что возможно изменение порядка выполнения отдельных операций записи и чтения;
- флаг NS (No Snoop) означает, что область памяти, к которой относится данная транзакция, нигде не кэшируется.
В PCI-X отложенные транзакции (Delayed Transaction) заменены на расщепленные транзакции (Split Transaction). Любую транзакцию, кроме всех транзакций записи в память, целевое устройство может завершать либо немедленно (обычным для PCI способом), либо с использованием протокола расщепленных транзакций. В последнем случае целевое устройство подает сигнал Split Response (расщепление), внутренне исполняет команду, а потом инициирует собственную транзакцию (команда Split Completion) для пересылки данных или сообщения о завершении инициатору исходной (расщепленной) транзакции. Целевое устройство обязано расщеплять транзакцию, если не может ответить на нее до истечения начальной задержки (initial latency). Устройство, вызвавшее расщепляемую транзакцию, называется запросчиком (Requester). Устройство, завершающее расщепленную транзакцию (Completer), будем называть исполнителем. Для завершения транзакции исполнитель должен будет запросить управление шиной у арбитра; запросчик на этапе завершения будет выступать в роли целевого устройства. Завершать транзакцию расщепленным способом может устройство, даже и не являющееся формально мастером шины (по признакам в его конфигурационных регистрах). Транзакция завершения Split Completion во многом напоминает пакетную транзакцию записи, но отличается в фазе адресации: вместо полного адреса пространства памяти или ввода/вывода по шине AD передается идентификатор последовательности (с номером шины, устройства и функции запросчика), к которой относится это завершение, и только младшие 6 бит адреса. Исполнитель берет этот идентификатор из атрибутов расщепленной им транзакции. По этому идентификатору (номеру шины запросчика) мосты доводят транзакцию завершения до устройствазапросчика. В фазе атрибутов передается идентификатор исполнителя (CBN — номер шины, CDN — номер устройства и CFN — номер функции). Запросчик должен распознать свой идентификатор последовательности и ответить на транзакцию обычным способом (немедленно). Последовательность может отрабатываться и не одной транзакцией завершения, а их серией, до исчерпания счетчика байтов (или прекращаться по ошибке). К какому стартовому адресу относится каждая из транзакций завершения, запросчик вычисляет сам (он знает, что запрашивал и сколько байтов уже пришло). Транзакция завершения может нести либо запрошенные данные чтения, либо сообщение о результатах транзакции — Split Complete Message.
Запросчик должен быть всегда готов к получению данных начатых им последовательностей, причем данные разных последовательностей могут приходить в произвольном порядке. Исполнитель может выдавать транзакции завершения на несколько последовательностей также в произвольном порядке. В пределах каждой последовательности завершения, естественно, должны быть упорядочены по адресам (которые не передаются). Атрибуты в транзакции завершения содержат номер шины, устройства и функции исполнителя и счетчик байтов. Кроме того, здесь присутствуют три специфических флага:
- BCM (Byte Count Modified) — признак того, что будет передано меньше байтов данных, чем просил запросчик (передается с данными завершения);
- SCE (Split Completion Error) — признак ошибки завершения, устанавливается при передаче сообщения завершения как ранний признак ошибки (до декодирования самого сообщения);
- SCM (Split Completion Message) — признак сообщения (отличает сообщение от данных).
Особенности передачи данных в PCI-X 2.0
В PCI-X 2.0 вдобавок к вышеописанным изменениям протокола появился новый режим Mode 2, отличающийся ускорением блочной записи в память и применением ECC-контроля. Этот режим возможен только при низком (1,5 В) напряжении питания интерфейсных схем. Режим Mode 2 имеет следующие особенности:
- во всех транзакциях на 1 такт увеличено время декодирования адреса целевым устройством — задержки его ответа сигналом DEVSEL# на обращенную к нему команду. Этого лишнего такта требует ECC-контроль (устройство проверяет достоверность адреса и команды). По той же причине минимальное время покоя шины между транзакциями увеличено с 1 до 2 тактов;
- в транзакциях пакетной записи в память (команда Memory Write Block) используется удвоенная или учетверенная скорость передачи данных по отношению к тактовой частоте. В этих транзакциях сигналы BEx# используются для синхронизации от источника данных (по прямому назначению они не используются, поскольку подразумевается обязательное разрешение всех байтов). Каждая передача данных (32, 64 или 16 бит) сопровождается стробами, в качестве которых используются сигналы BEx#. Пары линий BE[1:0]# и BE[3:2]# передают дифференциальные стробирующие сигналы для линий данных AD[15:0] и AD[31:16] соответственно. В одном такте шины может быть две или четыре подфазы данных (data subphase), этим и обеспечиваются режимы PCI-X266 и PCI-X533 при частоте шины 133 МГц. Поскольку все управляющие сигналы синхронизируются по сигналу общей синхронизации (CLK), гранулярность передач становится равной двум или четырем подфазам данных. Для 32-разрядной шины это означает, что в транзакциях можно передавать (а также останавливать и приостанавливать передачи) данные порциями, кратными 8 или 16 байтам.
В 64-битном варианте шины линии AD[63:32] используются только в фазах данных; для адреса (даже 64-битного) и атрибутов используется только 32-битная шина.
Для устройств, работающих в Mode 2, вводится возможность использования 16-битной шины. При этом фазы адреса и атрибутов занимают по два такта, а фазы данных идут всегда парами (обеспечивая обычную гранулярность). В шине AD используются линии AD[16:31], по которым в первой фазе пары передаются биты [0:15], а во второй — [16:31]. По линиям C/BE[2:3]# в первой фазе передаются биты C/BE[0:1]#, а во второй — C/BE[2:3]#. Для ECC-контроля используются линии ECC[2:5], по которым в первой фазе передаются биты ECC[0, 1, 6] и специальный бит контроля E16, а во второй — ECC[2, 3, 4, 5]. 16-битная шина предназначена только для встроенных применений (слоты и карты расширения не предусматриваются).
Обмен сообщениями между устройствами (команда DIM)
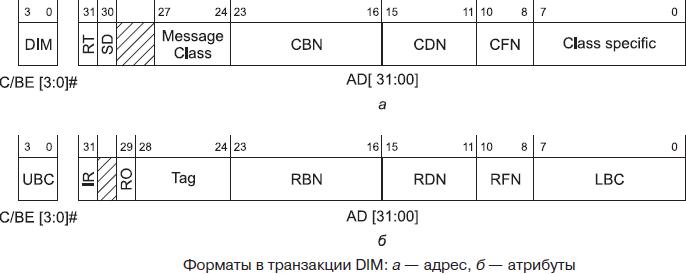
В PCI-X 2.0 введена возможность передачи информации (сообщений) устройству, адресуясь с помощью идентификатора (номера шины, устройства и функции). Для адресации и маршрутизации этих сообщений, которыми могут обмениваться любые устройства шины (включая и главный мост), не используется адресное пространство памяти или ввода/вывода. Сообщения передаются последовательностями, в которых используются команды DIM (Device ID Message), отличающиеся специфичностью адреса и атрибутов. В фазе адреса (рисунок ниже, а) передается идентификатор получателя сообщений (Completer ID) — номер его шины (CBN), устройства (CDN) и функции (CFN). Бит RT (Route Type) указывает тип маршрутизации сообщения: 0 — явная адресация с использованием вышеуказанного идентификатора, 1 — неявная адресация к главному мосту (при этом идентификатор не используется). Бит SD (Silent Drop) задает способ отработки ошибок при выполнении данной транзакции: 0 — обычный (как для записи в память), 1 — игнорирование некоторых типов ошибок (но не контроля четности или ECC). Поле Message Class задает класс сообщения, в соответствии с которым трактуется младший байт адреса. Транзакция может использовать и двухадресный цикл, при этом в первой фазе адреса по линиям C/BE[3:0]# передается код команды DAC, содержимое бит AD[31:00] соответствует рисунку, а. Во второй фазе адреса по линиям C/BE[3:0]# передается код команды DIM, а все биты AD[31:00] трактуются в зависимости от класса сообщения. Устройство, поддерживающее обмен сообщениями, декодировав команду DIM, проверяет поля идентификаторов получателя на соответствие своему собственному.
В фазе атрибутов (рисунок, б) передается идентификатор источника сообщения (RBN, RDN и RFN), тег сообщения (Tag), 12-битный счетчик байтов (UBC и LBC) идополнительные биты-признаки. Бит IR (Initial Request) является признаком начала сообщения, которое может быть разорвано на несколько частей инициатором, получателем или промежуточными мостами (во всех последующих частях бит обнулен). Бит RO (Relaxed Ordering) указывает на возможность неупорядоченной доставки данного сообщения по отношению к другим сообщениям и записям в память, распространяемым в том же направлении (порядок доставки фрагментов данного сообщения сохраняется всегда).
Тело сообщения, передаваемое в фазах данных, может иметь длину до 4096 байт (предел обусловлен 12-битным счетчиком длины). Содержимое тела определяется классом сообщения; класс 0 отдается на использование по воле производителя.
Сообщения с явной маршрутизацией маршрутизируются мостами на основе номера шины получателя. Проблемы передачи могут возникать только на главных мостах: если в системе имеется несколько главных мостов, то архитектурная связь между ними может быть очень сложной (например, через магистрали контроллера памяти). Передача сообщений с шины на шину через главные мосты желательна (это проще, чем передача транзакций всех типов), но не строго обязательна. Поддержка этой передачи дает больше свободы пользователю (не приходится при расстановке устройств принимать во внимание всю топологию шин). Сообщения с неявной маршрутизацией передаются только по направлению к хосту.
Поддержка DIM для устройств PCI-X необязательна; мосты PCI-X Mode 2 обязаны поддерживать DIM. Если сообщение DIM адресуется к устройству, находящемуся на шине, работающей в стандартном режиме PCI (или путь к нему ведет через PCI), мост либо просто аннулирует это сообщение (если SD = 1), либо отвергает транзакцию (Target Abort, если SD = 0).
Границы диапазонов адресов и транзакций
Области пространств памяти и ввода/вывода, занимаемые устройством (точнее, функцией), описываются регистрами BAR (Base Address Register) в заголовке конфигурационного пространства. При этом подразумевается, что длина области выражается числом 2n (n = 0, 1, 2…) и область выровнена естественным образом. В PCI области памяти выделяются по 2n параграфов (16 байт), то есть минимальный размер области — 16 байт. Области ввода/вывода выделяются по 2n двойных слов. Мосты PCI-PCI имеют карты адресов памяти с гранулярностью 1 Мбайт и карты ввода/вывода с гранулярностью 4 кбайт.
В PCI пакетная транзакция может быть прервана на границе любого двойного слова (в 64-битных операциях — учетверенного слова). В PCI-X ради оптимизации обращений к памяти пакетные транзакции разрешается прерывать только в разрешенных точках, называемых ADB (Allowable Disconnect Boundary — разрешенные границы отключения). Точки ADB располагаются с интервалом 128 байт — это целое число (1, 2, 4 или 8) строк кэша современных процессоров. Конечно, это ограничение относится только к границам транзакций внутри последовательности. Если последовательность должна по плану заканчиваться не на границе ADB, то и ее последняя транзакция будет завершена не на границе. Однако этой ситуации стараются избегать, разрабатывая такие структуры данных, которые могут быть выровнены подходящим образом (иногда даже ценой избыточности).
С границами адресов связан термин ADQ (ADB Delimited Quantum) — часть транзакции или буферной памяти (в мостах и устройствах), лежащая между границами соседних ADB. Например, транзакция, пересекающая одну границу ADB, состоит из двух ADQ (квантов) данных и занимает в мосте два буфера ADQ.
В соответствии с разрешенными границами транзакций области памяти, занимаемые устройствами PCI-X, также должны начинаться и заканчиваться на ADB — память выделяется квантами ADQ. Таким образом, минимальная область памяти, выделяемая устройству PCI-X, не может быть меньше 128 байт, а с учетом правил описания области ее размер может составлять 128 × 2n байт.
Время выполнения транзакций, таймеры и буферы
Протокол PCI регламентирует время (число тактов), допустимое для различных фаз транзакций. Работа шины контролируется несколькими таймерами, не позволяющими попусту расходовать такты шины и помогающими планировать распределение полосы пропускания.
Каждое целевое устройство должно достаточно быстро отвечать на адресованную ему транзакцию. Ответ адресованного целевого устройства (сигнал DEVSEL#) должен появиться в 1–3 такте после фазы адреса, в зависимости от «проворности» устройства: 1 такт — быстрое (Fast), 2 — среднее (Medium), 3 — медленное (Slow) декодирование. Следующий такт при отсутствии ответа отводится на перехват транзакции мостом с субтрактивным декодированием адреса. Задержка первой фазы данных (target initial latency), то есть задержка появления сигнала TRDY# относительно FRAME#, не должна превышать 16 тактов шины. Если устройство по своей природе иногда может не успевать уложиться в этот интервал, оно должно формировать сигнал STOP#, прекращая транзакцию. Это заставит ведущее устройство повторить транзакцию, и с большой вероятностью эта попытка окажется успешной. Если устройство медленное и часто не укладывается в 16 тактов, то оно должно выполнять отложенную транзакцию (Delayed Transaction, см. выше). Целевое устройство имеет инкрементный механизм слежения за длительностью циклов (Incremental Latency Mechanism), который не позволяет интервалу между соседними фазами данных в пакете (target subsequent latency) превышать 8 тактов шины. Если целевое устройство не успевает работать в таком темпе, оно обязано остановить транзакцию. Желательно, чтобы устройство сообщало о своем «неуспевании» как можно раньше, не выжидая предельных 16 или 8 тактов, — это экономит полосу пропускания шины.
Инициатор также не должен задерживать поток — допустимая задержка от начала FRAME# до сигнала IRDY# (master data latency) и между фазами данных не должна превышать 8 тактов. Целевое устройство время от времени может отвергать операцию записи в память с запросом повтора (это, к примеру, может происходить при записи в видеопамять). У инициатора есть «предел терпения» для завершения операции — таймер максимального времени исполнения (maximum complete time). Таймер имеет порог 10 мкс — 334 такта при 33 МГц или 668 тактов на 66 МГц. За это время инициатор должен иметь возможность «протолкнуть» хоть одну фазу данных. Таймер начинает отсчет с момента запроса повтора операции записи в память и сбрасывается при последующем завершении транзакции записи в память, отличном от запроса повтора. Устройства, не способные выдерживать ограничение на максимальное время исполнения записи в память, должны предоставлять драйверу возможность определять их состояние, в котором достаточно быстрая запись в память невозможна. Драйвер, естественно, должен учитывать это состояние и не «напрягать» шину и устройство бесплодными попытками записи.
Право на управление шиной (сигнал GNT#) может быть отобрано у инициатора в любой момент времени. В зависимости от исполняемой команды и состояния сигналов ведущее устройство должно либо прервать транзакцию, либо продолжать ее до запланированного завершения. Каждое ведущее устройство, способное сформировать пакет с более чем двумя фазами данных, должно иметь собственный программируемый таймер задержки (master latency timer, или просто latency timer). Этот таймер фактически задает ограничение на длину пакетной транзакции и, следовательно, на пропускную способность шины, предоставляемую этому устройству. Таймер запускается каждый раз по выставлении этим устройством сигнала FRAME# и отсчитывает такты шины до достижения значения, указанного в одноименном конфигурационном регистре. Поведение ведущего устройства после срабатывания таймера зависит от типа команды и состояния сигналов FRAME# и GNT# на момент срабатывания таймера:
- если ведущее устройство снимает сигнал FRAME# до срабатывания таймера, транзакция завершается нормально;
- Если сигнал GNT# снят и исполняемая команда не является записью памяти с инвалидацией, то инициатор обязан сократить транзакцию, сняв сигнал FRAME#. При этом ему позволяется завершить текущую и выполнить еще одну фазу данных;
- если сигнал GNT# снят и исполняется запись в память с инвалидацией, то инициатор должен завершить транзакцию по концу текущей (если передается не последнее двойное слово строки) или следующей (если двойное слово — последнее) строки кэша.
Задержка арбитража (arbitration latency) определяется как число тактов от подачи инициатором запроса REQ# до получения права управления шиной GNT#. Эта задержка зависит от активности других инициаторов, быстродействия устройств (чем меньше они вводят тактов ожидания, тем лучше) и «проворности» собственно арбитра.
При конфигурировании ведущие устройства сообщают свои потребности, указывая максимально допустимую задержку предоставления доступа к шине (Max_Lat) и минимальное время, на которое им должно предоставляться управление шиной (Min_GNT). Эти потребности определяются присущим устройству темпом передачи данных и его организацией. Однако будут ли эти потребности реально удовлетворены (по ним должна определяться стратегия арбитража) — неясно. Задержка предоставления доступа определяется как время от подачи запроса REQ# до получения GNT# и перехода шины в состояние покоя (только с этого момента данное устройство может начать транзакцию). Она зависит от числа ведущих устройств на шине, их активности и назначенных им значений таймеров задержки (в их регистрах Latency Timer, где время задается в тактах шины). Чем больше значения у этих таймеров, тем большее время придется другим устройствам ожидать предоставления управления шиной при ее значительной загрузке. Одно из слагаемых задержки предоставления доступа — задержка арбитража.
Шина позволяет уменьшить мощность (ток), потребляемую устройствами, ценой увеличения числа тактов в транзакциях, применяя пошаговое переключение линий AD[31:0] и PAR, — так называемый степпинг (address/data stepping). Здесь возможны два варианта:
- плавный шаг (continuous stepping) — начало формирования сигналов слаботочными формирователями за несколько тактов до выставления сигнала-квалификатора действительной информации (FRAME# в фазе адреса, IRDY# или TRDY# в фазе данных). За эти несколько тактов сигналы «доползут» до требуемого значения при меньшем токе потребления;
- дискретный шаг (diskrete stepping) — нормальные формирователи срабатывают не все сразу, а группами (например, побайтно), в каждом такте по группе. При этом снижаются броски тока, поскольку одновременно переключается меньше формирователей.
Устройство само может и не пользоваться этими возможностями (см. описание бита 7 регистра команд в прошлых темах), но должно «понимать» такие циклы. Задерживая сигнал FRAME#, устройство рискует потерять право доступа к шине, если арбитр получит запрос от более приоритетного устройства. По этой причине PCI 2.3 степпинг отменен для всех транзакций, кроме обращений к конфигурационному пространству устройств (конфигурационные циклы типа 0). В этих циклах устройство может и не успеть в первом же такте транзакции распознать сигнал выборки IDSEL, который приходит с соответствующей линии ADx через резистор.
В PCI-X требования к количеству тактов ужесточились:
- инициатор не имеет права вводить такты ожидания. В транзакциях записи инициатор выставляет на шину начальные данные (Data0) через 2 такта после фазы атрибутов; если транзакция пакетная, то следующие (Data1) — через 2 такта после ответа устройства сигналом DEVSEL#. Если целевое устройство не дает готовности (сигнала TRDY#), то инициатор должен в каждом такте чередовать данные Data0–Data1, пока целевое устройство не даст готовность (ему позволительно вводить только четное число тактов ожидания);
- целевое устройство имеет право вводить такты ожидания только для начальной фазы данных транзакции; для последующих фаз данных ожидание недопустимо.
Для максимального использования возможностей шины устройства должны иметь буферы, чтобы накапливать в них данные для пакетных транзакций. Рекомендуется для устройств со скоростью передачи данных до 5 Мбайт/с иметь буфер, по крайней мере на 4 двойных слова. Для более высоких скоростей рекомендуется буфер на 32 двойных слова. Для обмена с системной памятью наиболее эффективны транзакции, работающие с целыми строками кэша, что тоже учитывают при определении размера буфера. Однако увеличение размера буфера может вызвать трудности при обработке ошибок, а также вести к увеличению задержек доставки данных (пока устройство не заполнит определенный объем буфера, оно не начнет передачу этих данных по шине, и их потребители будут ожидать).
В спецификации приводится пример организации карты Fast Ethernet (скорость передачи — 10 Мбайт/с), у которой для каждого направления передачи имеется 64-байтный буфер, разделенный на две половины (ping-pong buffer). Когда адаптер заполняет одну половину буфера приходящим кадром, он выводит в память накопленное содержимое другой половины, после чего половины меняются ролями. Каждая половина выводится в память за 8 фаз данных (около 0,25 мкс на частоте 33 МГц), что соответствует установке MIN_GNT = 1. При скорости прихода данных 10 Мбайт/с каждая половина заполняется за 3,2 мкс, что соответствует установке MAX_LAT = 12 (в регистрах MIN_GNT и MAX_LAT время задается в интервалах по 0,25 мкс).