
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Акция звездочка skf. Натяжные потолки брянск фокинский район монтаж натяжных потолков в брянске.
Память. Нижний уровень
Память. Нижний уровень
Типы микросхем динамических ОЗУ
- Подробности
- Родительская категория: Память. Нижний уровень
- Категория: Микросхемы памяти
Динамическая память состоит из ядра (массива ЗЭ) и интерфейсной логики (буферных регистров, усилителей чтения данных, схемы регенерации и др.), Хотя количество видов DRAM уже превысило два десятка, ядро у них организовано практически одинаково. Главные различия связаны с интерфейсной логикой, причем различия эти обусловлены также и областью применения микросхем — помимо основной памяти ЭВМ, микросхемы памяти входят, например, в состав видеоадаптеров. Классификация микросхем динамической памяти показана ниже (см. рисунок ниже).
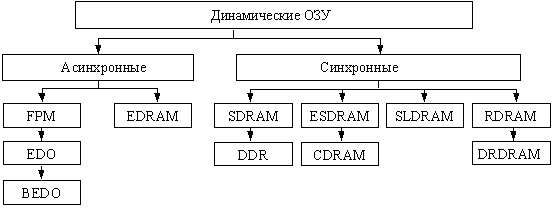
Типы микросхем динамического ОЗУ
Теперь рассмотрим различные типы микросхем динамической памяти DRAM. На начальном этапе это были микросхемы асинхронной памяти, работа которых не привязана жестко к тактовым импульсам системной шины. Асинхронной памяти свойственны дополнительные затраты времени на взаимодействие микросхем памяти и контроллера. Так, в асинхронной схеме сигнал RAS будет сформирован только после поступления в контроллер тактирующего импульса и будет воспринят микросхемой памяти через некоторое время.
Микросхемы DRAM. В первых микросхемах динамической памяти применялся наиболее простой способ обмена данными. Он позволял считывать и записывать строку памяти только на каждый пятый такт (см. рисунок ниже "a"). Этапы такой процедуры были описаны ранее. Традиционной DRAM соответствует формула 5-5-5-5. Микросхемы данного типа могли работать на частотах до 40 МГц и из-за своей медлительности (время доступа составляло около 120 нс) просуществовали недолго.
Микросхемы FРМ DRAM. Микросхемы динамического ОЗУ, реализующие режим FPM (Fast Page Mode), также относятся к ранним типам DRAM. В основе лежит следующая идея. Доступ к ячейкам, лежащим в одной строке матрицы, можно проводить быстрее. Для доступа к очередной ячейке достаточно подавать на микросхему лишь адрес нового столбца, сопровождая его сигналом CAS. Полный же адрес (строки и столбца) передается только при первом обращении к строке. Сигнал RAS остается активным на протяжении всего страничного цикла и позволяет заносить в регистр адреса столбца новую информацию не по спадающему фронту CAS, а как только адрес на входе стабилизируется, то есть практически по переднему фронту сигнала CAS. Схема чтения для FPM DRAM (см. рисунок ниже "b") описывается формулой 5-3-3-3 (всего 14 тактов). Применение схемы быстрого страничного доступа позволило сократить время доступа до 60 нс.
Микросхемы EDO DRAM. Следующим этапом в развитии динамических ОЗУ стали микросхемы с гuперстраничным режимом доступа (НРМ, Нурег Page Mode), более известные как EDO (Extended Data Output — расширенное время удержания данных на выходе). Главная особенность технологии — увеличенное по cpaвнению с FPM DRAM время доступности данных на выходе микросхемы. В микросхемах FPM DRAM выходные данные остаются действительными только при активном сигнале CAS, за счет чего во втором и последующих доступах к строке нужно три такта: такт переключения CAS в активное состояние, такт считывания данных и такт переключения CAS в неактивное состояние. В EDO DRAM по активному (спадающему) фронту сигнала CAS данные запоминаются во внутреннем регистре, где хранятся еще некоторое время после того, как поступит следующий активный фронт сигнала. Это позволяет использовать хранимые данные, когда CAS уже переведен в неактивное состояние. Схема чтения у EDO DRAM уже 5-2- 2-2 (см. рисунок ниже "c"), что на 20% быстрее, чем у FPM. Время доступа составляет порядка 30-40 нс.
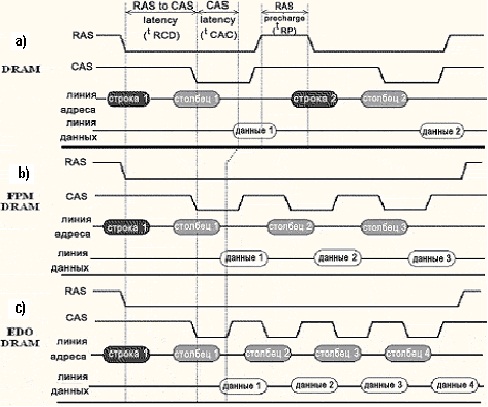
Временные диаграммы DRAM, FPM DRAM, EDO DRAM
Микросхемы BEDO DRAM. Технология EDO была усовершенствована компанией VIА Technologies. Новая модификация EDO известна как BEDO (Burst EDO — пакетная EDO). Новизна метода в том, что при первом обращении считывается вся строка микросхемы, в которую входят последовательные слова пакета. За последовательной пересылкой слов (переключением столбцов) автоматически следит внутренний счетчик микросхемы. Это исключает необходимость выдавать адреса для всех ячеек пакета, но требует поддержки со стороны внешней логики. Способ позволяет сократить время считывания второго и последующих слов еще на один такт (см. рисунок ниже), благодаря чему формула приобретает вид 5-1-1-1.
Микросхемы SDRAM. Аббревиатура SDRAM (Sуnchrоnous DRAM — Синхронная DRAM) используется для обозначения микросхем "обычных" синхронных динамических ОЗУ. Кардинальные отличия SDRAM от рассмотренных выше асинхронных динамических ОЗУ можно свести к четырем положениям:
•синхронный метод передачи данных на шину;
•применение нескольких (двух или четырех) внутренних банков памяти;
•конвейерный механизм пересылки пакета;
•передача части функций контроллера памяти логике самой микросхемы.
Синхронность памяти позволяет контроллеру памяти "знать" моменты готовности данных, за счет чего снижаются издержки циклов ожидания и поиска данных. Так как данные появляются на выходе микросхемы одновременно с тактовыми импульсами, упрощается взаимодействие памяти с другими устройствами ЭВМ.В отличие от ВЕDО конвейер позволяет передавать данные пакета по тактам, благодаря чему ОЗУ может работать бесперебойно на более высоких частотах, чем асинхронные ОЗУ.
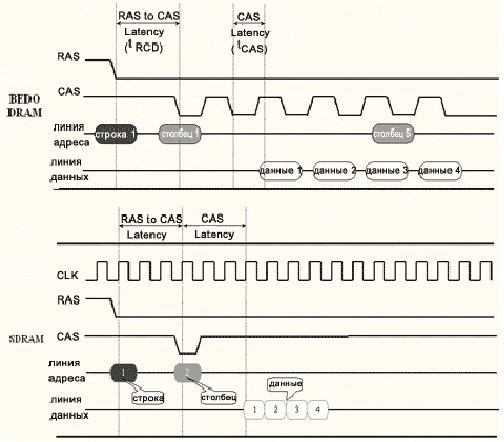
Временные диаграммы BEDO DRAM, SDRAM
Микросхемы DDR SDRAM. Важным этапом в дальнейшем развитии технологии SDRAM стала DDR SDRAM (Double Data Rate SDRAM — SDRAM с удвоенной скоростью передачи данных). В отличие от SDRAM, новая модификация выдает данные в пакетном режиме по обоим фронтам импульса синхронизации, из-за чего пропускная способность возрастает вдвое.
Микросхемы RDRAM, DRDRAM. Принципиально отличный подход к построению DRAM был предложен компанией Rambus в 1997 году. В нем используется оригинальная система обмена данными между ядром и контроллером памяти. В таблице (см. таблица ниже) приведены сравнительные характеристики перечисленных выше микросхем памяти. Ведутся работы по повышению быстродействия, в частности, связанные с применением КЭШ в микросхемах (CDRAM).
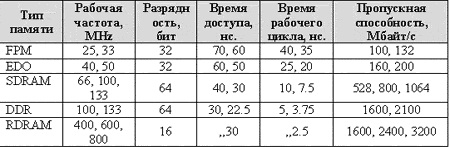
Сравнительные характеристики микросхем памяти
Ассоциативная память
- Подробности
- Родительская категория: Память. Нижний уровень
- Категория: КЭШ-память
Ассоциативная память
В ассоциативной памяти элементы выбираются не по адресу, а по содержимому. Поясним последнее понятие более подробно. Для памяти с адресной организацией было введено понятие минимальной адресуемой единицы (МАЕ) как порции данных, имеющей индивидуальный адрес. Введем аналогичное понятие для ассоциативной памяти, и будем эту минимальную единицу хранения в ассоциативной памяти называть строкой ассоциативной памяти (СтрАП). Каждая СтрАП содержит два поля: поле тега (англ. tag — ярлык, этикетка, признак) и поле данных. Запрос на чтение к ассоциативной памяти словами можно выразить следующим образом: выбрать строку (строки), у которой (у которых) тег равен заданному значению.
Особо отметим, что при таком запросе возможен один из трех результатов:
- имеется в точности одна строка с заданным тегом;
- имеется несколько строк с заданным тегом;
- нет ни одной строки с заданным тегом.
Поиск записи по признаку — это действие, типичное для обращений к базам данных, и поиск в базе зачастую чвляется ассоциативным поиском. Для выполнения такого поиска следует просмотреть все записи и сравнить заданный тег с тегом каждой записи. Это можно сделать и при использовании для хранения записей обычной адресуемой памяти (и понятно, что это потребует достаточно много времени — пропорционально количеству хранимых записей!). Об ассоциативной памяти говорят тогда, когда ассоциативная выборка данных из памяти поддержана аппаратно. При записи в ассоциативную память элемент данных помещается в СтрАП вместе с присущим этому элементу тегом. Для этого можно использовать любую свободную СтрАП. Рассмотрим разновидности структурной организации КЭШ-памяти или способы отображения оперативной памяти на КЭШ.
Полностью ассоциативный КЭШ
Схема полностью ассоциативного КЭШа представлена на рисунке (см. рисунок ниже).
Опишем алгоритм работы системы с КЭШ-памятью. В начале работы КЭШ-память пуста. При выполнении первой же команды во время выборки ее код, а также еще несколько соседних байтов программного кода, — будут перенесены (медленно) в одну из строк КЭШа, и одновременно старшая часть адреса будет записана в соответствующий тег. Так происходит заполнение КЭШ-строки.
Если следующие выборки возможны из этого участка, они будут сделаны уже из КЭШа (быстро) — "КЭШ-попадание". Если же окажется, что нужного элемента в КЭШе нет, — "КЭШ-промахом". В этом случае обращение происходит к ОЗУ (медленно), и при этом одновременно заполняется очередная КЭШ-строка.

Схема полностью ассоциативной КЭШ-памяти
Обращение к КЭШу происходит следующим образом. После формирования исполнительного адреса его старшие биты, образующие тег, аппаратно (быстро) и одновременно сравниваются с тегами всех КЭШ-строк. При этом возможны только две ситуации из трех, перечисленных ранее: либо все сравнения дадут отрицательный результат (КЭШ-промах), либо положительный результат сравнения будет зафиксирован в точности для одной строки (КЭШ-попадание).
При считывании, если зафиксировано КЭШ-попадание, младшие разряды адреса определяют позицию в КЭШ-строке, начиная с которой следует выбирать байты, а тип операции определяет количество байтов. Очевидно, что если длина элемента данных превышает один байт, то возможны ситуации, когда этот элемент (частями) расположен в двух (или более) разных КЭШ-строках, тогда время на выборку такого элемента увеличится. Противодействовать этому можно, выравнивая операнды и команды по границам КЭШ-строк, что и учитывают при разработке оптимизирующих трансляторов или при ручной оптимизации кода.
Если произошел КЭШ-промах, а в КЭШе нет свободных строк, необходимо заменить одну строку КЭШа на другую строку.
Основная цель стратегии замещения — удерживать в КЭШ-памяти строки, к которым наиболее вероятны обращения в ближайшем будущем, и заменять строки, доступ к которым произойдет в более отдаленном времени или вообще не случится. Очевидно, что оптимальным будет алгоритм, который замещает ту строку, обращение к которой в будущем произойдет позже, чем к любой другой строке-КЭШ.
К сожалению, такое предсказание практически нереализуемо, и приходится привлекать алгоритмы, уступающие оптимальному. Вне зависимости от используемого алгоритма замещения, для достижения высокой скорости он должен быть реализован аппаратными средствами.
Среди множества возможных алгоритмов замещения наиболее распространенными являются четыре, рассматриваемые в порядке уменьшения их относительной эффективности. Любой из них может быть применен в полностью ассоциативном КЭШ.
Наиболее эффективным является алгоритм замещения на основе наиболее давнего использования (LRU — Least Recently Used), при котором замещается та строка КЭШ-памяти, к которой дольше всего не было обращения. Проводившиеся исследования показали, что алгоритм LRU, который "смотрит" назад, работает достаточно хорошо в сравнении с оптимальным алгоритмом, "смотрящим" вперед.
Наиболее известны два способа аппаратурной реализации этого алгоритма. В первом из них с каждой строкой КЭШ-памяти ассоциируют счетчик. К содержимому всех счетчиков через определенные интервалы времени добавляется единица. При обращении к строке ее счетчик обнуляется. Таким образом, наибольшее число будет в счетчике той строки, к которой дольше всего не было обращений и эта строка — первый кандидат на замещение.
Второй способ реализуется с помощью очереди, куда в порядке заполнения строк КЭШ-памяти заносятся ссылки на эти строки. При каждом обращении к строке ссылка на нее перемещается в конец очереди. В итоге первой в очереди каждый раз оказывается ссылка на строку, к которой дольше всего не было обращений. Именно эта строка прежде всего и заменяется.
Другой возможный алгоритм замещения — алгоритм, работающий по принципу "первый вошел, первый вышел" (FIFO — First In First Out). Здесь заменяется строка, дольше всего находившаяся в КЭШ-памяти. Алгоритм легко реализуется с помощью рассмотренной ранее очереди, с той лишь разницей, что после обращения к строке положение соответствующей ссылки в очереди не меняется.
Еще один алгоритм — замена наименее часто использовавшейся строки (LFU — Least Frequently Used). Заменяется та строка в КЭШ-памяти, к которой было меньше всего обращений. Принцип можно воплотить на практике, связав каждую строку со счетчиком обращений, к содержимому которого после каждого обращения добавляется единица. Главным претендентом на замещение является строка, счетчик которой содержит наименьшее число.
Простейший алгоритм — произвольный выбор строки для замены. Замещаемая строка выбирается случайным образом. Реализовано это может быть, например, с помощью счетчика, содержимое которого увеличивается на единицу с каждым тактовым импульсом, вне зависимости от того, имело место попадание или промах. Значение в счетчике определяет заменяемую строку.
Кроме тега и байтов данных в КЭШ-строке могут содержаться дополнительные служебные поля, среди которых в первую очередь следует отметить бит достоверности V (от valid — действительный имеющий силу) и бит модификации M (от modify — изменять, модифицировать). При заполнении очередной КЭШ-строки V устанавливается в состояние "достоверно", а M — в состояние "не модифицировано". В случае, если в ходе выполнения программы содержимое данной строки было изменено, переключается бит M, сигнализируя о том, что при замене данной строки ее содержимое следует переписать в ОЗУ. Если по каким-либо причинам произошло изменение копии элемента данной строки, хранимого в другом месте (например в ОЗУ), переключается бит V. При обращении к такой строке будет зафиксирован КЭШ-промах (несмотря на то, что тег совпадает), и обращение произойдет к основному ОЗУ. Кроме того, служебное поле может содержать биты, поддерживающие алгоритм LRU.
Оценка объема оборудования
Типовой объем КЭШ-памяти в современной системе — 8…1024 кбайт, а длина КЭШ-строки 4…32 байт. Дальнейшая оценка делается для значений объема КЭШа 256 кбайт и длины строки 32 байт, что характерно для систем с процессорами Pentium и PentiumPro. Длина тега при этом равна 27 бит, а количество строк в КЭШе составит 256К/ 32=8192. Именно столько цифровых компараторов 27 битных кодов потребуется для реализации вышеописанной структуры.
Приблизительная оценка затрат оборудования для построения цифрового компаратора дает значение 10 транз/бит, а общее количество транзисторов только в блоке компараторов будет равно:
10*27*8192 = 2 211 840,
что приблизительно в полтора раза меньше общего количества транзисторов на кристалле Pentium. Таким образом, ясно, что описанная структура полностью ассоциативной КЭШ-памяти (ассоциативная память) реализуема только при малом количестве строк в КЭШе, т.е. при малом объеме КЭШа (практически не более 32…64 строк). КЭШ большего объема строят по другой структуре.
Иерархия запоминающих устройств
- Подробности
- Родительская категория: Память. Нижний уровень
- Категория: Методы доступа
Память часто называют "узким местом" фон-Неймановских ВМ из-за ее серьезного отставания по быстродействию от процессоров, причем, разрыв этот неуклонно увеличивается. Так, если производительность процессоров возрастает вдвое примерно каждые 1,5 года, то для микросхем памяти прирост быстродействия не превышает 9% в год (удвоение за 10 лет), что выражается в увеличении разрыва в быстродействии между процессором и памятью приблизительна на 50% в год. При создании системы памяти постоянно приходится решать задачу обеспечения требуемой емкости и высокого быстродействия за приемлемую цену. Наиболее эффективным решением является создание иерархической памяти. Иерархическая память состоит из ЗУ различных типов (см. рисунок ниже), которые, в зависимости от характеристик, относят к определенному уровню иерархии. Более высокий уровень меньше по емкости, быстрее и имеет большую стоимость в пересчете на бит, чем более низкий уровень. Уровни иерархии взаимосвязаны: все данные на одном уровне могут быть также найдены на более низком уровне, и все данные на этом более низком уровне могут быть найдены на следующем нижележащем уровне и т. д.
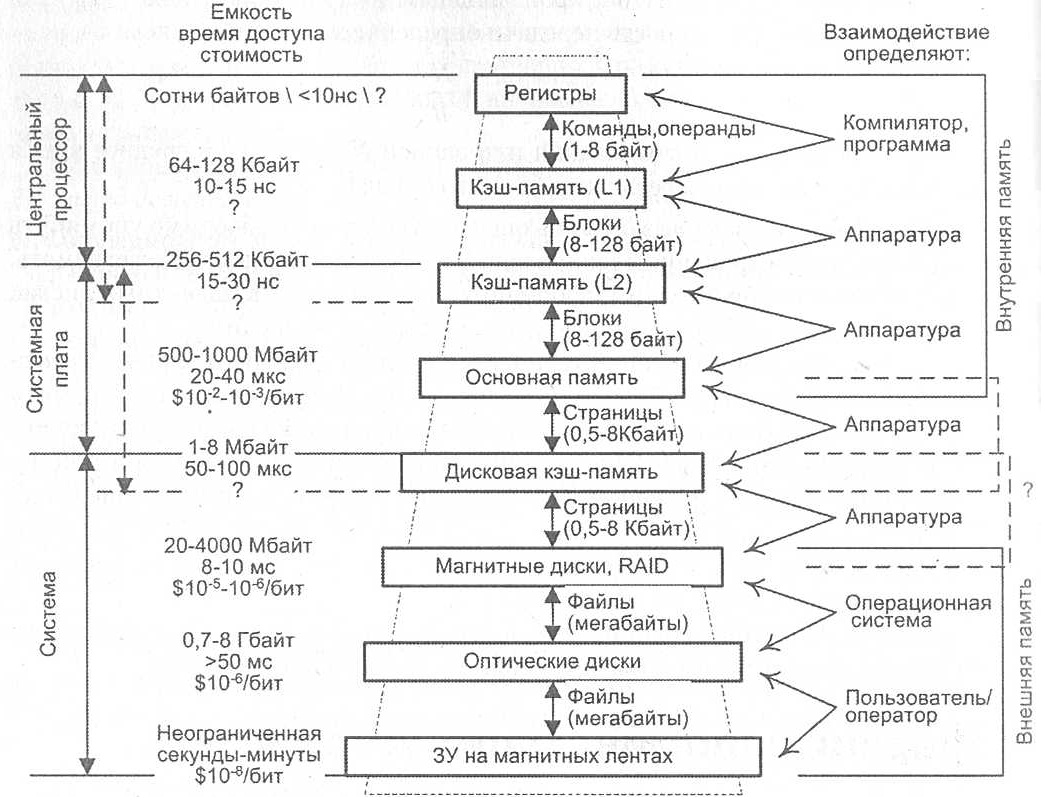
Схема иерархической памяти
Четыре верхних уровня иерархии образуют внутреннюю память ЭВМ, а все нижние уровни — это внешняя или вторичная память. По мере движения вниз по иерархической структуре:
- Уменьшается соотношение "стоимость/бит".
- Возрастает емкость.
- Растет время доступа.
- Уменьшается частота обращения к памяти со стороны центрального процессора.
Если память организована в соответствии с пунктами 1 — 3, а характер размещения в ней данных и команд удовлетворяет пункту 4, иерархическая организация ведет к уменьшению общей стоимости при заданном уровне производительности.
Справедливость этого утверждения вытекает из принципа локальности по обращению. Если рассмотреть процесс выполнения большинства программ, то можно заметить, что с очень высокой вероятностью адрес очередной команды программы либо следует непосредственно за адресом, по которому была считана текущая команда, либо расположен вблизи него. Такое расположение адресов называется пространственной локальностью программы. Обрабатываемые данные, как правило, структурированы, и такие структуры обычно хранятся в последовательных ячейках памяти. Данная особенность программ называется пространственной локальностью данных. Кроме того, программы содержат множество небольших циклов и подпрограмм. Это означает, что небольшие наборы команд могут многократно повторяться в течение некоторого интервала времени, то есть имеет место временная локальность. Все три вида локальности объединяет понятие локальность по обращению. Принцип локальности часто облекают в численную форму и представляют в виде так называемого правила "90/ 10": 90% времени работы программы связано с доступом к 10% адресного пространства этой программы. Из свойства локальности вытекает, что программу разумно представить в виде последовательно обрабатываемых фрагментов. Помещая такие фрагменты в более быструю память, можно существенно снизить общие задержки на обращение, поскольку команды и данные, будучи один раз переданы из медленного ЗУ в быстрое, затем могут использоваться многократно и среднее время доступа к ним в этом случае определяется уже более быстрым ЗУ. На каждом уровне иерархии информация разбивается на блоки, которые и пересылаются между уровнями. При доступе к командам и данным, например, для их считывания, сначала производится поиск в памяти верхнего уровня. Факт обнаружения нужной информации называют попаданием (hit), в противном случае говорят о промахе (miss). При промахе производится поиск в ЗУ следующего, более низкого уровня, где также возможны попадание или промах. После обнаружении необходимой информации выполняется последовательная пересылка блока, содержащего искомую информацию, с нижних уровней на верхние. Следует отметить, что, независимо от числа уровней иерархии, пересылка информации может осуществляться только между двумя соседними уровнями. При оценке эффективности подобной организации памяти обычно используют следующие характеристики:
- коэффициент попаданий (hit rate) — отношение числа обращений к памяти, при которых произошло попадание, к общему числу обращений к ЗУ данного уровня иерархии;
- коэффициент промахов (miss rate) — отношение числа обращений к памяти, при которых имел место промах, к общему числу обращений к ЗУ данного уровня иерархии;
- время обращения при попадании (hit time) — время, необходимое для поиска нужной информации в памяти верхнего уровня, плюс время на фактическое считывание данных;
- потери на промах (miss penalty) — время, требуемое для замены блока в памяти более высокого уровня на блок с нужными данными, расположенный в ЗУ следующего (более низкого) уровня.
Описание некоторого уровня иерархии ЗУ предполагает конкретизацию четырех моментов:
- размещения блока — допустимого места расположения блока на примыкающем сверху уровне иерархии;
- идентификации блока — способа нахождения блока;
- замещения блока — выбора блока, заменяемого при промахе с целью освобождения места для нового блока;
- согласования копий (когерентность данных) — обеспечения согласованности копий одних и тех же блоков, расположенных на разных уровнях.
Модули динамической памяти
- Подробности
- Родительская категория: Память. Нижний уровень
- Категория: Микросхемы памяти
Модули динамической полупроводниковой памяти прошли эволюцию от набора микросхем, устанавливаемых на системной плате и заметных по своему регулярному расположению (несколько смежных рядов одинаковых микросхем), до отдельных небольших плат, вставляемых в стандартный разъем (слот) системной платы. Первенство в создании таких модулей памяти обычно относят к фирме IBM. Основными разновидностями модулей динамических оперативных ЗУ с момента их оформления в виде самостоятельных единиц были:
•30-контактные однобайтные модули SIMM (DRAM);
•72-контактные четырехбайтные модули SIMM (DRAM);
•168-контактные восьмибайтные модули DIMM (SDRAM);
•184-контактные восьмибайтные модули DIMM (DDR SDRAM);
•184-контактные (20 из них не заняты) двухбайтные модули RIMM RDDRAM).
Сокращение SIMM означает Single In-Line Memory Module — модуль памяти с одним рядом контактов, так как контакты краевого разъема модуля, расположенные в одинаковых позициях с двух сторон платы, электрически соединены. Соответственно, DIMM значит Dual In-Line Memory Module — модуль памяти с двумя рядами контактов. А вот RIMM означает Rambus Memory Module — модуль памяти типа Rambus. Кроме этих модулей, имеются также варианты для малогабаритных компьютеров, для графических карт и некоторые другие.
Если микросхемы памяти физически располагаются только с одной стороны платы, то такой модуль называют односторонним, а если с двух сторон — то двухсторонним. При равной емкости модулей у двухстороннего модуля количество микросхем больше, поэтому на каждую линию шины данных приходится большая нагрузка, чем при использовании одностороннего. С этой точки зрения односторонние модули предпочтительней двусторонних. Однако количество банков в двусторонних модулях вдвое больше, чем в односторонних, поэтому при определенных условиях и хорошем контроллере памяти двусторонний модуль может обеспечить несколько большую производительность.
Помимо собственно конструктивной организации и типа памяти, модули имеют также и некоторые другие различия. Одним из таких различий является возможность (или ее отсутствие) контроля хранимых данных.
Контроль может основываться на использовании дополнительных (по одному на каждый хранимый байт) битов четности (Parity bits), т.е. в этом случае каждый байт занимает в памяти по 9 бит. Такой контроль позволяет выявить ошибки при считывании хранимой информации из памяти, но не исправить их. Более сложный контроль предполагает использование кодов, корректирующих ошибки, — ECC (Error Correcting Codes). Эти коды позволяют обнаруживать ошибки большей кратности, чем одиночные, а одиночные ошибки могут быть исправлены. Подобные схемы используются в серверных конфигурациях, когда требуется повышенная надежность. Память, устанавливаемая в настольные ПЭВМ, обычно не имеет никакого контроля.
Кроме того, известны также различные модификации схем контроля, вплоть до просто имитирующих контрольные функции, но не осуществляющие их, например, с генерацией всегда верного бита четности.
Модули DIMM также различаются по наличию или отсутствию в них буферных схем на шинах адреса и управляющих сигналов. Небуферизованные (unbuffered) модули больше нагружают эти шины, но более быстродействующие и дешевые. Их обычно применяют в настольных ЭВМ. Буферизованные (registered) имеют буферные регистры и, обеспечивая меньшую нагрузку на шины, позволяют подключить к ней большее количество модулей. Однако эти регистры несколько снижают быстродействие памяти, требуя лишнего такта задержки. Применяют буферизованные модули обычно в серверных системах.
Еще одной особенностью, различающей модули динамической памяти, является способ, посредством которого после включения компьютера определяется объем и тип установленной в нем памяти.
В первых персональных ЭВМ объем и быстродействие установленной памяти задавались переключателями (джамперами — jumpers), расположенными на системной плате. С появлением модулей SIMM (существовали также похожие на них модули SIPP) стал использоваться так называемый параллельный метод идентификации (parallel presence detect), при котором краевой разъем модуля имел дополнительные контакты, используемые только для целей указания присутствия модуля в том слоте, где он установлен, его объема и времени обращения. В самых первых (30-контактных) модулях таких дополнительных контактов было только два, в 72-контактных модулях их стало четыре: два указывали на объем модуля и два — на время обращения. Эти контакты могли заземляться непосредственно на модуле, что позволяло различить четыре вида модулей по объему и четыре по времени доступа.
Попытки использовать этот же прием в последующих модулях потребовали увеличения количества таких контактов, но решить все проблемы идентификации не смогли. Поэтому, начиная c модулей DIMM, используют так называемый последовательный способ идентификации (Serial Presence Detect — SPD), при котором на плату модуля устанавливается специальная дополнительная микросхема, так называемый SPD-чип, представляющая собой небольшую постоянную память на 128 или 256 байт с последовательным (I2C) интерфейсом доступа. В этой микросхеме записана основная информация об изготовителе микросхемы и ее параметрах. Формат этих данных стандартный, определенный советом JEDEC (Joint Electron Devices Engineering Council), стандартов которого придерживаются все изготовители полупроводниковой памяти.
КЭШ с прямым отображением памяти
- Подробности
- Родительская категория: Память. Нижний уровень
- Категория: КЭШ-память
КЭШ-памяти с прямым отображением (см. рисунок ниже) требует минимального объема оборудования. При этом всю основную память можно представить в виде двухмерного массива блоков (КЭШ-строк), в котором количество рядов равно числу строк в КЭШ-памяти, а в каждом ряду последовательно находятся блоки, переадресуемые на одну и ту же строку КЭШ-памяти. В приведенном примере количество строк соответствует разрядности индекса, а количество блоков в строке — разрядности тега. Общий объем КЭШ-памяти составляет 64К байт.
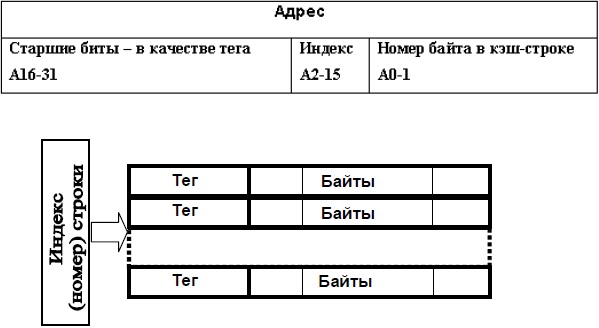
Схема КЭШ-памяти с прямым отображением
Логика работы КЭШ сводится к следующему. При поступления адреса анализируется поле "индекс". Оно указывает на одну из 16К строк, а именно, на ту, где могут быть данные (например, при чтении). Затем сравниваются старшие 16 бит адреса с тегом, который хранится в строке. При совпадении проискодит КЭШ-попадание, иначе — КЭШ- промах. В этом случае требуется всего лишь один многоразрядный компаратор, на вход которого подается тег с той единственной КЭШ- строки, которая оказывается выбранной полем "индекс". Именно так была устроена одна из первых реализаций КЭШа — накристальная КЭШ- память в микропроцессоре фирмы Motorola MC68020: 32 строки по 8 байтов образуют 256-байтовый КЭШ с прямым отображением.
Еще статьи...
Подкатегории
-
КЭШ-память
- Кол-во материалов:
- 7
-
Микросхемы памяти
- Кол-во материалов:
- 6
-
Основная память. ОЗУ
- Кол-во материалов:
- 1
-
Методы доступа
- Кол-во материалов:
- 3