Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Память. Нижний уровень
КЭШ-память
КЭШ-память
- Подробности
- Родительская категория: Память. Нижний уровень
- Категория: КЭШ-память
Как уже отмечалось, в качестве элементной базы основной памяти в большинстве ЭВМ служат микросхемы динамических ОЗУ, на порядок уступающие по быстродействию центральному процессору. В результате процессор вынужден простаивать несколько тактовых периодов. Если ОЗУ выполнить на быстрых микросхемах статической памяти, стоимость ЭВМ возрастет весьма существенно. Экономически приемлемое решение этой проблемы было предложено М. Уилксом в 1965 году в процессе разработки ЭВМ Atlas. Заключается оно в использовании двухуровневой памяти, когда между ОЗУ и процессором размещается небольшая, но быстродействующая буферная память. В процессе работы такой системы в буферную память копируются участки ОЗУ, к которым производится обращение со стороны процессора. Выигрыш достигается за счет ранее рассмотренного свойства локальности. Уилкс называл рассматриваемую буферную память подчиненной (slave). Позже распространение получил термин КЭШ-память (от английского слова cache — “убежище, тайник”), поскольку такая память обычно скрыта от программиста в том смысле, что он не может ее адресовать и может даже вообще не знать о ее существовании. Впервые КЭШ- системы появились в машинах ceмейства IВM 360.
В общем виде использование КЭШ-памяти поясним следующим образом. Когда ЦП пытается прочитать слово из основной памяти, сначала осуществляется поиск копии этого слова в КЭШе. Если такая копия существует, обращение к ОП не производится, а в ЦП передается слово, извлеченное из КЭШ-памяти. Данную ситуацию принято называть успешным обращением или попаданием (hit). При отсутствии слова в КЭШе, то есть при неуспешном обращении — промахе (miss), требуемое слово передается в ЦП из основной памяти, но одновременно из 0П в КЭШ-память пересылается блок данных, содержащий это слово. Выигрыш в скорости при использовании КЭШ получается только в том случае, если перенесенные один раз в КЭШ фрагменты затем используются многократно. Причем, целесообразно помещать в КЭШ одновременно несколько разных участков ОЗУ, так как процессор одновременно работает с разными адресами, например, программой и данными. Согласно описанной выше локальности (локальной серийности), достаточно в КЭШ помещать 10 часть объема программы, чтобы 90% времени процессор работал с КЭШ.
КЭШ-память в вычислительной системе оказывается "двойником" участков основной памяти с адресной организацией. При обращении к основной памяти формируется физический адрес, размер которого соответствует разрядности адресной шины (реальный объем физической памяти обычно меньше, а размер КЭШа в 20…100 раз меньше объема основной памяти). Как в этих условиях схемотехника управления памятью может "понять", что элемент, к которому происходит обращение, находится в КЭШе? КЭШ представляет собой ассоциативную память.
При наличии КЭШ-памяти адресуемый объект может существовать в нескольких экземплярах.
В двухпроцессорной системе с двухуровневым КЭШем, выполняющей самомодифицируемую программу (т.е. программу, изменяющую собственные команды), один и тот же фрагмент кода может существовать в 9 экземплярах:
- 1) в основном ОЗУ,
- 2) и 3) в КЭШах второго уровня двух процессоров,
- 4) и 5) в КЭШах команд первого уровня обоих процессоров,
- 6) и 7) в КЭШах данных первого уровня обоих процессоров,
- 8) и 9) в буферах предвыборки обоих процессоров).
При записи результата операции в КЭШ может оказаться, что содержимое КЭШа и соответствующего элемента ОЗУ становится различным (нарушение когерентности памяти). Другой bus-master может в такой ситуации считать недействительные (старые) данные. Такая ситуации недопустима. Для обеспечения когерентности используется механизм отслеживания достоверности строк КЭШа и объявления содержимого этих строк недостоверным в случае нарушения когерентности. После этого данными из КЭШа пользоваться нельзя, и потребуется обращение к основной памяти для замены значения на обновленное.
На эффективность применения КЭШ-памяти в иерархической системе памяти влияет целый ряд моментов. К наиболее существенным из них можно отнести:
- емкость КЭШ-памяти;
- размер строки;
- способ отображения основной памяти на КЭШ-память;
- алгоритм замещения информации в заполненной КЭШ-памяти;
- алгоритм согласования содержимого основной и КЭШ-памяти;
- число уровней КЭШ-памяти.
Ассоциативная память
- Подробности
- Родительская категория: Память. Нижний уровень
- Категория: КЭШ-память
Ассоциативная память
В ассоциативной памяти элементы выбираются не по адресу, а по содержимому. Поясним последнее понятие более подробно. Для памяти с адресной организацией было введено понятие минимальной адресуемой единицы (МАЕ) как порции данных, имеющей индивидуальный адрес. Введем аналогичное понятие для ассоциативной памяти, и будем эту минимальную единицу хранения в ассоциативной памяти называть строкой ассоциативной памяти (СтрАП). Каждая СтрАП содержит два поля: поле тега (англ. tag — ярлык, этикетка, признак) и поле данных. Запрос на чтение к ассоциативной памяти словами можно выразить следующим образом: выбрать строку (строки), у которой (у которых) тег равен заданному значению.
Особо отметим, что при таком запросе возможен один из трех результатов:
- имеется в точности одна строка с заданным тегом;
- имеется несколько строк с заданным тегом;
- нет ни одной строки с заданным тегом.
Поиск записи по признаку — это действие, типичное для обращений к базам данных, и поиск в базе зачастую чвляется ассоциативным поиском. Для выполнения такого поиска следует просмотреть все записи и сравнить заданный тег с тегом каждой записи. Это можно сделать и при использовании для хранения записей обычной адресуемой памяти (и понятно, что это потребует достаточно много времени — пропорционально количеству хранимых записей!). Об ассоциативной памяти говорят тогда, когда ассоциативная выборка данных из памяти поддержана аппаратно. При записи в ассоциативную память элемент данных помещается в СтрАП вместе с присущим этому элементу тегом. Для этого можно использовать любую свободную СтрАП. Рассмотрим разновидности структурной организации КЭШ-памяти или способы отображения оперативной памяти на КЭШ.
Полностью ассоциативный КЭШ
Схема полностью ассоциативного КЭШа представлена на рисунке (см. рисунок ниже).
Опишем алгоритм работы системы с КЭШ-памятью. В начале работы КЭШ-память пуста. При выполнении первой же команды во время выборки ее код, а также еще несколько соседних байтов программного кода, — будут перенесены (медленно) в одну из строк КЭШа, и одновременно старшая часть адреса будет записана в соответствующий тег. Так происходит заполнение КЭШ-строки.
Если следующие выборки возможны из этого участка, они будут сделаны уже из КЭШа (быстро) — "КЭШ-попадание". Если же окажется, что нужного элемента в КЭШе нет, — "КЭШ-промахом". В этом случае обращение происходит к ОЗУ (медленно), и при этом одновременно заполняется очередная КЭШ-строка.

Схема полностью ассоциативной КЭШ-памяти
Обращение к КЭШу происходит следующим образом. После формирования исполнительного адреса его старшие биты, образующие тег, аппаратно (быстро) и одновременно сравниваются с тегами всех КЭШ-строк. При этом возможны только две ситуации из трех, перечисленных ранее: либо все сравнения дадут отрицательный результат (КЭШ-промах), либо положительный результат сравнения будет зафиксирован в точности для одной строки (КЭШ-попадание).
При считывании, если зафиксировано КЭШ-попадание, младшие разряды адреса определяют позицию в КЭШ-строке, начиная с которой следует выбирать байты, а тип операции определяет количество байтов. Очевидно, что если длина элемента данных превышает один байт, то возможны ситуации, когда этот элемент (частями) расположен в двух (или более) разных КЭШ-строках, тогда время на выборку такого элемента увеличится. Противодействовать этому можно, выравнивая операнды и команды по границам КЭШ-строк, что и учитывают при разработке оптимизирующих трансляторов или при ручной оптимизации кода.
Если произошел КЭШ-промах, а в КЭШе нет свободных строк, необходимо заменить одну строку КЭШа на другую строку.
Основная цель стратегии замещения — удерживать в КЭШ-памяти строки, к которым наиболее вероятны обращения в ближайшем будущем, и заменять строки, доступ к которым произойдет в более отдаленном времени или вообще не случится. Очевидно, что оптимальным будет алгоритм, который замещает ту строку, обращение к которой в будущем произойдет позже, чем к любой другой строке-КЭШ.
К сожалению, такое предсказание практически нереализуемо, и приходится привлекать алгоритмы, уступающие оптимальному. Вне зависимости от используемого алгоритма замещения, для достижения высокой скорости он должен быть реализован аппаратными средствами.
Среди множества возможных алгоритмов замещения наиболее распространенными являются четыре, рассматриваемые в порядке уменьшения их относительной эффективности. Любой из них может быть применен в полностью ассоциативном КЭШ.
Наиболее эффективным является алгоритм замещения на основе наиболее давнего использования (LRU — Least Recently Used), при котором замещается та строка КЭШ-памяти, к которой дольше всего не было обращения. Проводившиеся исследования показали, что алгоритм LRU, который "смотрит" назад, работает достаточно хорошо в сравнении с оптимальным алгоритмом, "смотрящим" вперед.
Наиболее известны два способа аппаратурной реализации этого алгоритма. В первом из них с каждой строкой КЭШ-памяти ассоциируют счетчик. К содержимому всех счетчиков через определенные интервалы времени добавляется единица. При обращении к строке ее счетчик обнуляется. Таким образом, наибольшее число будет в счетчике той строки, к которой дольше всего не было обращений и эта строка — первый кандидат на замещение.
Второй способ реализуется с помощью очереди, куда в порядке заполнения строк КЭШ-памяти заносятся ссылки на эти строки. При каждом обращении к строке ссылка на нее перемещается в конец очереди. В итоге первой в очереди каждый раз оказывается ссылка на строку, к которой дольше всего не было обращений. Именно эта строка прежде всего и заменяется.
Другой возможный алгоритм замещения — алгоритм, работающий по принципу "первый вошел, первый вышел" (FIFO — First In First Out). Здесь заменяется строка, дольше всего находившаяся в КЭШ-памяти. Алгоритм легко реализуется с помощью рассмотренной ранее очереди, с той лишь разницей, что после обращения к строке положение соответствующей ссылки в очереди не меняется.
Еще один алгоритм — замена наименее часто использовавшейся строки (LFU — Least Frequently Used). Заменяется та строка в КЭШ-памяти, к которой было меньше всего обращений. Принцип можно воплотить на практике, связав каждую строку со счетчиком обращений, к содержимому которого после каждого обращения добавляется единица. Главным претендентом на замещение является строка, счетчик которой содержит наименьшее число.
Простейший алгоритм — произвольный выбор строки для замены. Замещаемая строка выбирается случайным образом. Реализовано это может быть, например, с помощью счетчика, содержимое которого увеличивается на единицу с каждым тактовым импульсом, вне зависимости от того, имело место попадание или промах. Значение в счетчике определяет заменяемую строку.
Кроме тега и байтов данных в КЭШ-строке могут содержаться дополнительные служебные поля, среди которых в первую очередь следует отметить бит достоверности V (от valid — действительный имеющий силу) и бит модификации M (от modify — изменять, модифицировать). При заполнении очередной КЭШ-строки V устанавливается в состояние "достоверно", а M — в состояние "не модифицировано". В случае, если в ходе выполнения программы содержимое данной строки было изменено, переключается бит M, сигнализируя о том, что при замене данной строки ее содержимое следует переписать в ОЗУ. Если по каким-либо причинам произошло изменение копии элемента данной строки, хранимого в другом месте (например в ОЗУ), переключается бит V. При обращении к такой строке будет зафиксирован КЭШ-промах (несмотря на то, что тег совпадает), и обращение произойдет к основному ОЗУ. Кроме того, служебное поле может содержать биты, поддерживающие алгоритм LRU.
Оценка объема оборудования
Типовой объем КЭШ-памяти в современной системе — 8…1024 кбайт, а длина КЭШ-строки 4…32 байт. Дальнейшая оценка делается для значений объема КЭШа 256 кбайт и длины строки 32 байт, что характерно для систем с процессорами Pentium и PentiumPro. Длина тега при этом равна 27 бит, а количество строк в КЭШе составит 256К/ 32=8192. Именно столько цифровых компараторов 27 битных кодов потребуется для реализации вышеописанной структуры.
Приблизительная оценка затрат оборудования для построения цифрового компаратора дает значение 10 транз/бит, а общее количество транзисторов только в блоке компараторов будет равно:
10*27*8192 = 2 211 840,
что приблизительно в полтора раза меньше общего количества транзисторов на кристалле Pentium. Таким образом, ясно, что описанная структура полностью ассоциативной КЭШ-памяти (ассоциативная память) реализуема только при малом количестве строк в КЭШе, т.е. при малом объеме КЭШа (практически не более 32…64 строк). КЭШ большего объема строят по другой структуре.
КЭШ с прямым отображением памяти
- Подробности
- Родительская категория: Память. Нижний уровень
- Категория: КЭШ-память
КЭШ-памяти с прямым отображением (см. рисунок ниже) требует минимального объема оборудования. При этом всю основную память можно представить в виде двухмерного массива блоков (КЭШ-строк), в котором количество рядов равно числу строк в КЭШ-памяти, а в каждом ряду последовательно находятся блоки, переадресуемые на одну и ту же строку КЭШ-памяти. В приведенном примере количество строк соответствует разрядности индекса, а количество блоков в строке — разрядности тега. Общий объем КЭШ-памяти составляет 64К байт.
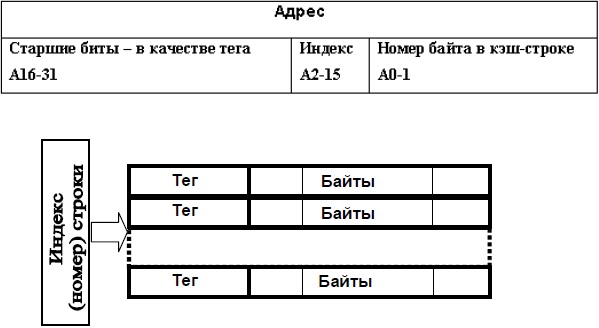
Схема КЭШ-памяти с прямым отображением
Логика работы КЭШ сводится к следующему. При поступления адреса анализируется поле "индекс". Оно указывает на одну из 16К строк, а именно, на ту, где могут быть данные (например, при чтении). Затем сравниваются старшие 16 бит адреса с тегом, который хранится в строке. При совпадении проискодит КЭШ-попадание, иначе — КЭШ- промах. В этом случае требуется всего лишь один многоразрядный компаратор, на вход которого подается тег с той единственной КЭШ- строки, которая оказывается выбранной полем "индекс". Именно так была устроена одна из первых реализаций КЭШа — накристальная КЭШ- память в микропроцессоре фирмы Motorola MC68020: 32 строки по 8 байтов образуют 256-байтовый КЭШ с прямым отображением.
КЭШ, ассоциативный по множеству (set-associative)
- Подробности
- Родительская категория: Память. Нижний уровень
- Категория: КЭШ-память
Синонимы: наборно-ассоциативный, множественно-ассоциативный.
Множественно-ассоциативное отображение относится к группе методов частично-ассоциативного отображения. Оно сочетает в себе достоинства предыдущих двух методов. КЭШ включает несколько страниц КЭШ- памяти с прямым отображением (см. рисунок ниже). Строки с одинаковым индексом образуют набор. При такой организации элемент данных с заданным адресом можно поместить не в любую КЭШ-строку, а только в строку, принадлежащую набору строк, выбираемых частью адреса, обозначенной на рисунке как "индекс". По количеству строк в каждом наборе говорят о "двухвходовой, четырехвходовой и т.д." наборно-ассоциативной КЭШ-памяти. Еще раз подчеркнем, что за уменьшение количества компараторов кодов в наборно-ассоциативной памяти приходится платить усложнением входной схемотехники компараторов и увеличением относительной частоты КЭШ-промахов.
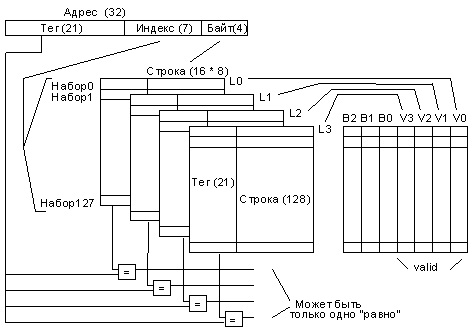
Схема КЭШ-памяти, ассоциативной по множеству
Алгоритмы обеспечения когерентности системы памяти
- Подробности
- Родительская категория: Память. Нижний уровень
- Категория: КЭШ-память
Проблема когерентности состоит в том, что при наличии в системе КЭШ-памяти одному исполнительному адресу соответствует более чем одно место хранения данных. Проблема возникает тогда, когда имеется более, чем одно устройство, способное модифицировать содержимое памяти. В этом случае одно устройство может изменить значение элемента (например, контроллер ПДП записывает блок данных в основную память), в то время как другое устройство (процессор), работая с другим экземпляром того же элемента данных, находящимся в КЭШе, будет использовать старое (неизмененное) значение. Понятно, что такие ситуации недопустимы.
Рассмотрим, что следует сделать, если когерентность нарушается при модификации КЭШ-строки. В этом случае требуется:
- записать (может быть с некоторой задержкой) измененное значение в основную память;
- сбросить признаки достоверности в прочих копиях (КЭШ-памяти других процессоров системы, если таковые имеются).
Для записи модифицированного данным процессором значения из его КЭШа в основную память используются две стратегии: сквозная запись (write-through) и обратная запись (write-back).
При сквозной записи перенос модифицируемого значения из КЭШа в ОЗУ происходит одновременно с изменением в КЭШе. Достоинство этой стратегии состоит в автоматическом обеспечении когерентности данного КЭШа и ОЗУ, а недостаток — в заметном снижении скорости (каждая запись безусловно идет в ОЗУ, даже если следующая команда снова будет модифицировать тот же элемент данных). На время обращения к ОЗУ дальнейшее выполнение программы приостанавливается.
Существует модификация этой стратегии, называемая буферизованной сквозной записью, при которой копирование модифицированной КЭШ- строки в ОЗУ происходит не сразу, а через промежуточный буфер, работающий по схеме FIFO. Копирование в этот буфер происходит так же быстро, как и в КЭШ. При этом в многопроцессорной системе сразу же происходит сброс битов достоверности в КЭШ-памяти других процессоров. Перенос содержимого буфера в ОЗУ осуществляется затем параллельно с продолжением выполнения программы в те промежутки, когда данный процессор освобождает шину, связывающую его с основной памятью. В этом случае также возможны задержки (например, если следующее обращение к КЭШу тоже вызовет КЭШ-промах), однако это будет происходить реже, чем в отсутствие буфера.
Существуют определенные правила работа с указанным буфером. В частности, если буфер занят и идет чтение ячейки ОЗУ, то чтение происходит в обход буфера (изменяется последовательность обращения к памяти).
При использовании стратегии обратной записи перенос модифицированной КЭШ-строки в ОЗУ происходит только при ее замене, что в среднем случается реже, чем обращения к ней (в КЭШ). Как следствие, эта стратегия обеспечивает меньшую по сравнению со сквозной записью, долю обращений к ОЗУ, т.е. более высокую эффективность кэширования.
Недостатки обратной записи:
- более сложная аппаратная реализация,
- сложнее обеспечить когерентность,
- при замене модифицированной строки возникает задержка, обусловленная необходимостью обращения к ОЗУ.
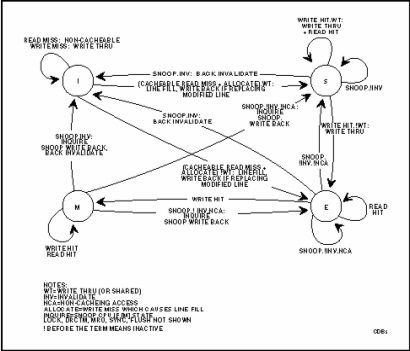
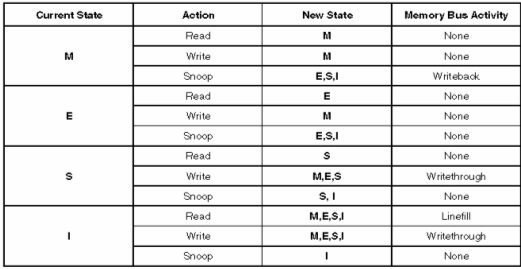
Последний недостаток можно частично устранить, используя упреждающую обратную запись: строка-кандидат на замену определяется заранее, переносится из КЭШа в ОЗУ в интервалах, когда шина свободна, и затем объявляется в данном КЭШе недостоверной. В результате в КЭШ-памяти почти всегда имеется свободная строка, которую можно без задержки использовать при КЭШ-промахе. Для обеспечения когерентности в сложных системах с несколькими КЭШами разработан и стандартизован протокол обеспечения когерентности, называемый MESI по названиям состояний, в которых может находиться КЭШ-строка: Modified, Exclusive, Shared, Invalid.
•Invalid. Это состояние означает, что строка недостоверна в данном КЭШе. При обращении к этому элементу будет зафиксирован КЭШ-промах и произойдет внешнее обращение в память следующего уровня (в КЭШ L2 или в основную память).
•Shared. Строка в КЭШе содержит достоверные данные и совпадает с содержимым основной памяти. Обращение будет внутренним (в данный КЭШ) и не приведет к активизации внешней шины.
•Exclusive. Строка достоверна, находится в КЭШе, совпадает с содержимым основной памяти, а экземпляры этой строки, находящиеся в других КЭШах, являются недостоверными.
•Modified. Строка находится в КЭШе, достоверна, но содержит более поздний (модифицированный) экземпляр данных, нежели остальные экземпляры в основной памяти и в других КЭШах.
Замечание 1: Строка достоверна, если она находится в состояниях S, E или M.
Замечание 2: Если строка находится в состоянии I, это означает, что она свободна.
Собственно протокол состоит из набора правил, по которым меняется состояние КЭШ-строки в результате возникновения разных событий, могущих быть причинами нарушения когерентности. В основе этих правил лежит принцип объявления строки недостоверной в случае подозрения в нарушении когерентности, что при обращении к этой строке вызовет КЭШ-промах и обновление содержимого этой строки новым значением из основной памяти. Таблица(см. ниже) и рисунок (см. ниже), взятые из технического описания процессора Pentium, показывают эти правила.
Basic MESI State Transitions