
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
AGP
Протоколы транзакций
- Подробности
- Родительская категория: AGP (Порт графического акселератора )
- Категория: AGP
Транзакции в режиме PCI, инициируемые акселератором, начинаются с подачи сигнала FRAME# и выполняются обычным для PCI способом. Заметим, что при этом на все время транзакции шина AD занята, причем транзакции чтения памяти занимают шину на большее число тактов, чем транзакции записи, — после подачи адреса неизбежны такты ожидания на время доступа к памяти. Запись на шине происходит быстрее — данные записи задатчик посылает сразу за адресом, а на время доступа к памяти они «оседают» в буфере контроллера памяти. Контроллер памяти позволяет завершить транзакцию и освободить шину до физической записи в память.
Конвейерные транзакции AGP (команды AGP) инициируются только акселератором; логикой AGP они ставятся в очереди на обслуживание и исполняются в зависимости от приоритета, порядка поступления запросов и готовности данных. Эти транзакции могут быть адресованы акселератором только к системному ОЗУ. Если устройству на AGP требуется обратиться к локальной памяти каких-либо устройств PCI, то оно должно выполнять эти транзакции в режиме PCI.
Обращения со стороны процессора (или задатчиков шины PCI), адресованные к устройству на AGP, отрабатываются им как ведомым устройством PCI, однако имеется возможность быстрой записи в локальную память — FW (Fast Write), в которой данные передаются на скорости AGP (2x/4x/8x), и управление потоком их передач ближе к протоколу AGP, нежели PCI. Транзакции FW инициируются процессором и предназначены для принудительного «заталкивания» данных в локальную память акселератора.
Концепцию конвейера AGP иллюстрирует рисунок. Порт AGP может находиться в одном из четырех состояний:
- IDLE — покой;
- DATA — передача данных конвейеризированных транзакций;
- AGP — постановка в очередь команды AGP;
- PCI — выполнение транзакции в режиме PCI.
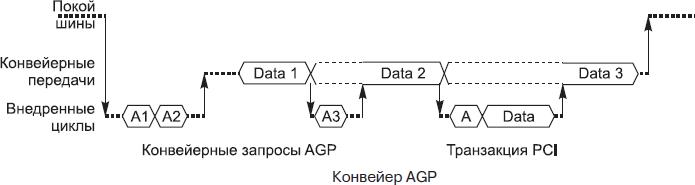
Из состояния покоя IDLE порт может вывести запрос транзакции PCI (как от акселератора, так и с системной стороны) или запрос AGP (только от акселератора). В состоянии PCI транзакция PCI выполняется целиком, от подачи адреса и команды до завершения передачи данных. В состоянии AGP ведущее устройство передает только команду и адрес для транзакции (по сигналу PIPE# или через шину SBA), ставящейся в очередь; несколько запросов могут следовать сразу друг за другом. В состояние DATA порт переходит, когда у него в очереди имеется необслуженная команда, готовая к исполнению. В этом состоянии происходит передача данных для команд, стоящих в очереди. Это состояние может прерываться вторжением запросов PCI (для выполнения целой транзакции) или AGP (для постановки в очередь новой команды), но прерывание1 возможно только на границах данных транзакций AGP. Когда порт AGP обслужит все команды, он снова переходит в состояние покоя. Все переходы происходят под управлением арбитра порта AGP, реагирующего на поступающие запросы (сигнал REQ# от акселератора и внешние обращения от процессора или других устройств PCI) и ответы контроллера памяти.
Транзакции AGP отличаются от транзакций PCI некоторыми деталями реализации:
- фаза данных отделена от фазы адреса, чем и обеспечивается конвейеризация;
- используется собственный набор команд;
- транзакции адресуются только к системной памяти, используя пространство физических адресов (как и в PCI). Транзакции могут иметь длину, кратную 8 байтам, и начинаться только по 8-байтной границе. Транзакции чтения иного размера должны выполняться только в режиме PCI; транзакции записи могут использовать сигналы C/BE[3:0]# для маскирования лишних байтов;
- длина транзакции явно указывается в запросе;
- конвейерные запросы не гарантируют когерентности памяти и кэша. Для операций, требующих когерентности, должны использоваться транзакции PCI. В AGP 3.0 возможно указать области памяти, для которых когерентность обеспечивается и для конвейерных транзакций.
Возможны два способа подачи команд AGP (постановок и запросов в очередь), из которых в текущей конфигурации выбирается один, причем изменение способа «на ходу» не допускается:
- запросы вводятся по шине AD[31:0] и C/BE[3:0] с помощью сигнала PIPE#, по каждому фронту CLK ведущее устройство передает очередное двойное слово запроса вместе с кодом команды;
- команды подаются через внеполосные (sideband) линии адреса SBA[7:0]. «Внеполосность» означает, что эти сигналы используются независимо от занятости шины AD. Синхронизация подачи запросов зависит от режима (1x/2x/4x/8x).
При подаче команд по шине AD во время активности сигнала PIPE# код команды AGP (CCCC) кодируется сигналами C/BE[3:0], при этом на шине AD помещаются начальный адрес (на AD[31:3]) и длина n (на AD[2:0]) запрашиваемого блока данных. Определены следующие команды (в скобках указан код CCCC):
- Read (0000) — чтение из памяти (n + 1) учетверенных слов (по 8 байт) данных, начиная с указанного адреса;
- HP Read (0001) — чтение с высоким приоритетом (упразднено в AGP 3.0);
- Write (0100) — запись в память;
- HP Write (0101) — запись с высоким приоритетом (упразднено в AGP 3.0);
- Long Read (1000) — «длинное» чтение (n + 1)×4 учетверенных слов (до 256 байт данных, упразднено в AGP 3.0);
- HP Long Read (1001) — «длинное» чтение с высоким приоритетом (упразднено в AGP 3.0);
- Flush (1010) — очистка, выгрузка данных всех предыдущих команд записи по адресам назначения (на порте AGP выглядит как чтение, возвращающее произвольное учетверенное слово в качестве подтверждения исполнения; адрес и длина, указанные в запросе, значения не имеют);
- Fence (1100) — установка «ограждений», позволяющих низкоприоритетному потоку записей не пропускать чтения;
- Dual Address Cycle, DAC (1101) — двухадресный цикл для 64-битной адресации: в первом такте по AD передаются младшая часть адреса и длина запроса, а во втором — старшая часть адреса (по AD) и код исполняемой команды (по C/BE[3:0]).
Для изохронных передач в AGP 3.0 выделены специальные команды.
При внеполосной подаче команд по шине SBA[7:0] передаются 16-битные посылки четырех типов. Тип посылки кодируется старшими битами:
- тип 1: 0AAA AAAA AAAA ALLL — поле длины (LLL) и младшие биты адреса (A[14:03]);
- тип 2: 10CC CCRA AAAA AAAA — код команды (CCCC) и средние биты адреса (A[23:15]);
- тип 3: 110R AAAA AAAA AAAA — старшие биты адреса (A[35:24]);
- тип 4: 1110 AAAA AAAA AAAA — дополнительные старшие биты адреса, если требуется 64-битная адресация.
Посылка из всех единиц является пустой командой (NOP); такие посылки означают покой шины SBA. Биты «R» зарезервированы. Посылки типов 2, 3 и 4 являются «липкими» (sticky) — значения, ими определяемые, сохраняются до введения новой посылки того же типа. Постановку команды в очередь инициирует посылка типа 1, задающая длину транзакции и ее младшие адреса, — код команды и остальная часть адреса должны быть определены ранее введенными посылками типов 2– 4. Такой способ очень экономно использует такты шины для подачи команд при пересылках массивов. Каждая 2-байтная посылка передается по 8-битной шине SBA за два приема (сначала старший, потом младший байт). Синхронизация байтов зависит от режима порта:
- в режиме 1x каждый байт передается по фронту CLK; начало посылки (старший байт) определяется по получению байта, отличного от 11111111b, по последующему фронту передается младший байт. Очередная команда (посылкой типа 1) может вводиться за каждую пару тактов CLK (при условии, что код команды и старший адрес уже введены предыдущими посылками). Полный цикл ввода команды занимает 10 тактов;
- в режиме 2x для SBA используется отдельный строб SB_STB, по его спаду передается старший байт, а по последующему фронту — младший. Частота этого строба (но не фаза) совпадает с CLK, так что очередная команда может вводиться в каждом такте CLK;
- в режиме 4x используется еще и дополнительный (инверсный) строб SB_STB#. Старший байт фиксируется по спаду SB_STB, а младший — по последующему спаду SB_STB#. Частота стробов в два раза выше, чем CLK, так что в каждом такте CLK может вводиться пара посылок. Однако мастер AGP может вводить в каждом такте не более одной посылки типа 1, то есть ставить в очередь не более одного запроса;
- В режиме 8x стробы называются иначе (SB_STBF и SB_STBS), их частота в четыре раза выше CLK, так что в каждом такте CLK умещаются уже 4 посылки. Однако темп постановки команд в очередь все равно ограничен одной командой за такт CLK.
В ответ на полученные команды порт AGP выполняет передачи данных, причем фаза данных AGP явно не привязана к фазе команды/адреса. Фаза данных будет вводиться портом AGP по готовности системной памяти к запрашиваемому обмену.
Передачи данных AGP выполняются, когда шина находится в состоянии DATA. Фазы данных вводит порт AGP (системная логика), исходя из порядка ранее пришедших к нему команд от акселератора. Акселератор узнает о назначения шины AD в последующей транзакции по сигналам ST[2:0] (действительны только во время сигнала GNT#, коды 100–110 зарезервированы):
- 000 — устройству будут передаваться данные низкоприоритетного запроса чтения (в AGP 3.0 — просто асинхронного чтения), ранее поставленного в очередь, или выполняется очистка;
- 001 — устройству будут передаваться данные высокоприоритетного запроса чтения (резерв в AGP 3.0);
- 010 — устройство должно будет предоставлять данные низкоприоритетного запроса записи (в AGP 3.0 — просто асинхронной записи);
- 011 — устройство должно будет предоставлять данные высокоприоритетного запроса записи (резерв в AGP 3.0);
- 111 — устройству разрешается поставить в очередь команду AGP (сигналом PIPE#) или начать транзакцию PCI (сигналом FRAME#);
- 110 — цикл калибровки приемопередатчиков (в AGP 3.0 для скорости 8x).
Акселератор узнает лишь тип и приоритет команды, результаты которой последуют в данной транзакции. Какую именно команду из очереди отрабатывает порт, акселератор определяет сам, так как именно он ставил их в очередь (ему известен порядок). Никаких тегов транзакций (как, например, в системной шине процессоров P6 или в PCI-X) в интерфейсе AGP нет. Имеются только независимые очереди для каждого типа команд (чтение низкоприоритетное, чтение высокоприоритетное, запись низкоприоритетная, запись высокоприоритетная). Фазы исполнения команд разных очередей могут чередоваться произвольным образом; порт имеет право исполнять их в порядке, оптимальном с точки зрения производительности. Реальный порядок исполнения команд (чтения и записи памяти) тоже может изменяться. Однако для каждой очереди порядок выполнения всегда совпадает с порядком подачи команд (об этом знают и акселератор, и порт). В AGP 3.0 приоритеты очередей отменили, но ввели возможность изохронных транзакций.
Запросы AGP с высоким приоритетом для арбитра системной логики являются более приоритетными, чем запросы от центрального процессора и ведущих устройств шины PCI. Запросы AGP с низким приоритетом для арбитра имеют приоритет ниже, чем от процессора, но выше, чем от остальных ведущих устройств. Хотя принятый протокол никак явно не ограничивает глубину очередей, спецификация AGP формально ее ограничивает до 256 запросов. На этапе конфигурирования устройства система PnP устанавливает реальное ограничение (в конфигурационном регистре акселератора) в соответствии с его возможностями и возможностями системной платы. Программы, работающие с акселератором (исполняемые и локальным, и центральным процессорами), не должны допускать превышения числа необслуженных команд в очереди (у них для этого имеется вся необходимая информация).
При передаче данных AGP управляющие сигналы, заимствованные от PCI, имеют почти такое же назначение, что и в PCI. Передача данных AGP в режиме 1x очень похожа на циклы PCI, но немного упрощена процедура квитирования (поскольку это выделенный порт и обмен выполняется только с быстрым контроллером системной памяти). В режимах 2x/4x/8x имеется специфика стробирования:
- в режиме 1x данные (4 байта на AD[31:0]) фиксируются получателем по положительному перепаду каждого такта CLK, что обеспечивает пиковую скорость 66,6×4 = 266 Мбайт/с;
- в режиме 2x используются стробы данных AD_STB0 и AD_STB1 для линий AD[0:15] и AD[16:31] соответственно. Стробы формируются источником данных, приемник фиксирует данные и по спаду, и по фронту строба. Частота стробов совпадает с частотой CLK, что и обеспечивает пиковую скорость 66,6×2×4 = 533 Мбайт/с;
- в режиме 4x используются еще и дополнительные (инверсные) стробы AD_STB0# и AD_STB1#. Данные фиксируются по спадам и прямых и инверсных стробов (пары стробов могут использоваться и как два отдельных сигнала, и как один дифференциальный). Частота стробов в два раза выше, чем CLK, что и обеспечивает пиковую скорость 66,6×2×2×4 = 1066 Мбайт/с;
- в режиме 8x пары стробов получили новые названия AD_STBF[1:0] (First — первый) и AD_STBS[1:0] (Second — второй), четные порции данных защелкиваются по положительному перепаду первого, нечетные — по перепаду второго. Частота переключения каждого из этих стробов в четыре раза выше CLK, стробы сдвинуты относительно друг друга на половину своего периода, чем и обеспечивается восьмикратная частота стробирования информации на линиях AD. Отсюда пиковая скорость 66,6×4×2×4 = 2132 Мбайт/с.
Порт AGP должен отслеживать состояние готовности буферов акселератора к посылке или получению данных транзакций, поставленных в очередь. Сигналом RBF# (Read Buffer Full) акселератор может информировать порт о неготовности к приему данных низкоприоритетных транзакций чтения (к приему высокоприоритетных он должен быть всегда готов). Сигналом WBF# (Write Buffer Full) он информирует о неспособности принять первую порцию данных быстрой записи FW.