
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Процессоры
Принцип работы архитектуры NetBurst
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура процессоров Pentium 4
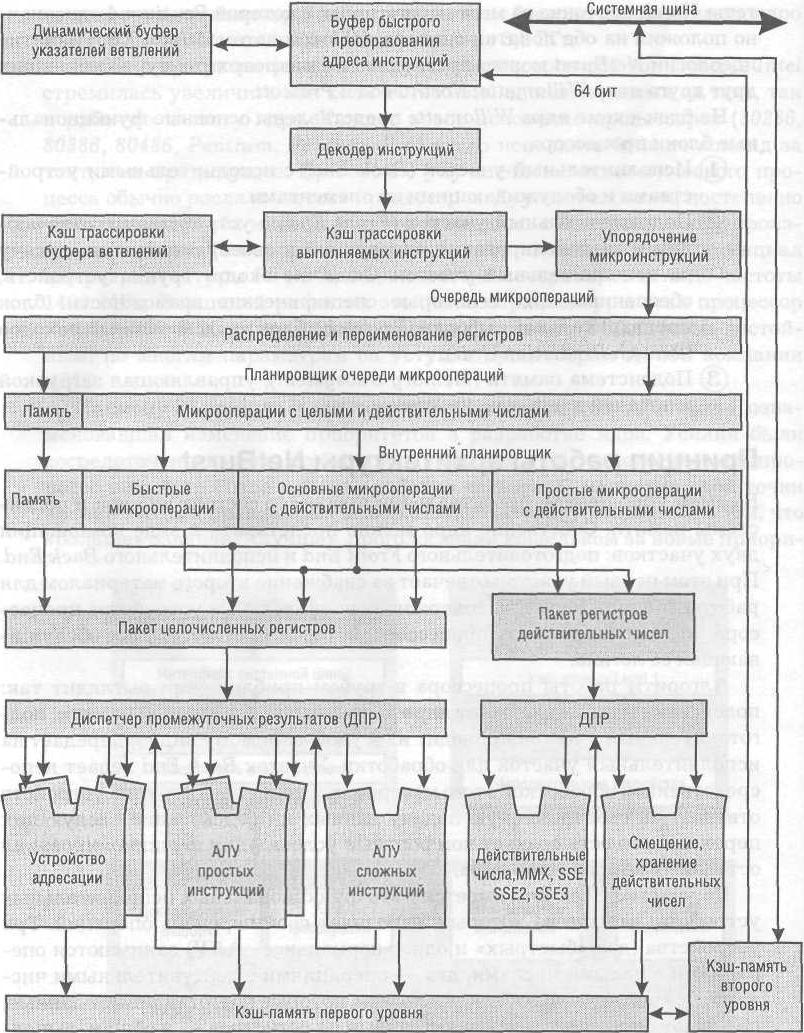
В самом упрощенном представлении процессор состоит из ядра и подсистемы памяти. Собственно ядро можно представить в виде комбинации двух участков: подготовительного Front End и исполнительного Back End. При этом первый участок отвечает за снабжение второго материалом для работы. Модуль Back End содержит исполнительные устройства процессора. Это именно та часть процессора, которая «считает», плюс обслуживающая ее логика.
Алгоритм работы процессора в грубом приближении выглядит так: подсистема памяти снабжает ядро данными из оперативной памяти, подготовительный участок приводит их к удобоваримому виду и передает на исполнительный участок для обработки. Участок Back End ведает непосредственной обработкой этого материала. Специальная группа устройств отвечает за своевременную подачу данных и предсказание следующих переходов, то есть создает комфортные условия для функционирования остальных компонентов ядра.
На участке Back End имеется пять функциональных исполнительных устройств, каждое из которых выполняет свой перечень операций. Три устройства (два «быстрых» и одно «нормальное» АЛУ) занимаются операциями с целыми числами, два — операциями с действительными числами. Все они связаны с блоками логики, которые подготавливают данные, передают операнды, считывают данные из регистров — в общем, выполняют ту работу, без которой нельзя произвести вычисления. Несколько обособленны два устройства вычисления и загрузки адресов.
Микроархитектура ядра Prescott процессора Pentium 4
Рассмотрим алгоритм выполнения простейшей операции: увеличения значения регистра на пять. Для этого необходимо выполнить ряд действий:
1. Взять содержимое регистра «X».
2. Взять число 5.
3. Отправить два числа и код операции «сложение» на исполнительное устройство.
4. Выполнить сложение.
5. Записать результат в регистр «X».
Из пяти перечисленных действий исполнительные устройства заняты только в одном (четвертым по порядку). Все подготовительные работы выполняет обслуживающая логика. Исполнительные же блоки принимают числа и код операции, производят саму операцию и выдают числовой результат. Их задача важна, но без обслуживающей логики они бессильны. Рассмотрим более сложную операцию: надо сложить содержимое регистров «X» и «Y», а также увеличить содержимое регистра «Z» на пять. Безусловно, можно выполнить операции по очереди, что займет довольно много времени. Но если поставить параллельно первому второе исполнительное устройство, то работу можно сделать вдвое быстрее.
Такая архитектура называется суперскалярной, что означает возможность исполнять более чем одну операцию за такт. Предположим, что второе задание предусматривает увеличение на единицу регистра «Y». Тогда процессор вынужден ждать, пока завершится первая операция, несмотря на то, что второе исполнительное устройство совершенно свободно. Таким образом, логика, обслуживающая исполнительные устройства, должна определять, есть ли взаимозависимости в заданиях или же их можно выполнять параллельно. Данная задача также возложена на участок Back End.
Для повышения производительности выгоднее как можно больше операций исполнять параллельно. Если подходящих операций не найдено в данном участке кода, можно пропустить несколько микроопераций с еще не готовыми операндами и далее выполнять только такие инструкции, изменение порядка которых не приведет к изменению результата. Такая технология называется Out-of-Order Execute (внеочередное исполнение).
Представим, что код программы содержит некоторое количество заданий. Причем выполняться они должны в определенной последовательности, потому что часть из них зависит от результатов предыдущих операций. А часть — не зависит. Некоторые задания ожидают поступления данных из памяти. Есть два варианта решения проблемы: либо ждать, пока все задания не будут выполнены поочередно, согласно последовательному коду программы, либо попытаться выполнить ту часть работы, для которой есть все необходимое. Разумеется, все задания выполнить «вне очереди» не удастся, но выполнение хотя бы части из них сэкономит некоторое количество времени.
Для решения такой задачи принципиально необходимы некоторые устройства. В первую очередь нужен буфер, в котором накапливаются задания. Из буфера устройство под названием планировщик (Sheduler) выбирает те задания, которые уже снабжены операндами и могут быть выполнены немедленно. Предварительно планировщик сортирует задания на те, которые можно исполнять вне очереди, и те, которые требуютп редыдущих результатов.
Полученные промежуточные данные необходимо куда-то записывать. Для этого предназначены служебные регистры. В частности, процессор Pentium 4 имеет 128 служебных регистров. Поскольку любая программа для платформы х86 не подозревает о существовании более чем 8 регистров общего назначения (РОН), надо, чтобы служебные регистры могли «притворяться» РОН. Этим занимается блок переименования регистров. Он берет первый попавшийся свободный служебный регистр и представляет его программе как «дозволенный» регистр общего назначения. Так результаты внеочередных операций записываются в «черновик» — служебные регистры. После выполнения очередных операций поступают «внеочередные» результаты из «черновика» и размещаются в РОН согласно порядку, указанному в программе.
Раскладка операций на составляющие позволяет упростить каждую стадию конвейера, уменьшить число логических элементов и тем самым повысить рабочую частоту ядра. Но инструкции CISC платформы х86 имеют нерегулярную структуру: разную длину, разное количество операндов и даже разный синтаксис. Две инструкции одинаковой длины могут содержать команды, отличающиеся по трудоемкости на порядок. В конвейер же надо подавать простые микрооперации, имеющие регулярную структуру: одинаковую длину, стандартное расположение операндов и служебных меток, примерно равную сложность исполнения. Упрощением и выравниваем инструкций занимается декодер, преобразующий инструкции CISC в микрооперации RISC.