
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Процессоры
Архитектура AMD64
Эксклюзивный кэш
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура AMD64
Поскольку производительность подсистемы кэширования вносит заметный вклад в общую производительность процессора, рассмотрим ее микроархитектуру подробнее. В общем случае, производительность кэш-памяти характеризуется несколькими параметрами: задержками (Latency), пропускной способностью (Throughput), типом ассоциативности и некоторыми другими. Первые два параметра влияют на производительность заметно больше остальных.
Оригинальность организации кэш-памяти процессоров AMD заключается в ее «эксклюзивности» (exclusive). Суть этой технологии в том, что содержимое кэша L1 не копируется в кэш L2, то есть они дополняют друг друга. Таким образом, суммарный объем кэша рассчитывается как сумма объемов L1 и L2. Эксклюзивная архитектура обусловливает некоторые особенности в работе кэша. Особенность первая: поскольку в процессе работы данные «складываются» прежде всего в кэш L1, то практически всегда возникает нехватка места. В этом случае кэш L1 перебрасывает самые ненужные данные в L2, а затем принимает новые. Для временного хранения перебрасываемых данных предусмотрен специальный буфер (Victim buffer). Необходимость в таком буфере возникает потому, что кэши L1 и L2 работают с разными задержками, как показано в таблице.

Вторую особенность архитектуры кэша AMD K8 хорошо иллюстрирует вариант работы с данными, которых не оказалось в кэше L1, но они есть в кэше L2. В этом случае задержки обусловлены следующими операциями. На первом этапе процессор выполняет поиск данных в кэше L1, на это уходит три такта. На втором этапе освобождается место в L1 для пересылки данных из L2. Соответственно, строка кэша сбрасывается в Victim buffer, освобождая место в L1. До окончания пересылки первого блока данных из L2 (после чего процессор может продолжить работу) необходимо еще 8 тактов.
Если буфер свободен, 8 + 3 такта дают минимальную задержку в 11 татов. Это так называемый «лучший» сценарий.
Если же Victim buffer занят, то на его очистку уходит 8 тактов. Переключение режимов записи/чтения кэша L2 занимает два такта. Еще 8 тактов тратится на перенос данных в L1. Последние два такта опять расходуются на переключение режимов записи/чтения. Таким образом, в худшем случае операция загрузки занимает 8 + 2 + 8 + 2 = 20 тактов. Это значение точно равно задержке, так как операция чтения на разделяемой 64-битной шине L1-L2 не может начаться, пока не будет закончена операция записи из Victim buffer.
По теоретической пропускной способности кэш второго уровня К7 проигрывает инклюзивному кэшу Pentium 4. Это объясняется как особенностями эксклюзивной архитектуры кэша, так и более узкой шиной (у Pentium 4 шина L1-L2 имеет ширину 256 бит). Но в реальных приложениях таких ситуаций, которые бы демонстрировали несостоятельность эксклюзивной архитектуры кэша, практически не возникает.
Разрабатывая архитектуру К8, инженеры AMD модернизировали шину кэш-памяти L1-L2. Вместо одной двунаправленной шины шириной 64 бит уровни кэша связаны двумя однонаправленными шинами шириной по 64 бита. Такое решение позволило практически полностью нивелировать отрицательные эффекты «перегруза» шины L1-L2 и снизить задержки в «худшем» варианте до 16 тактов.
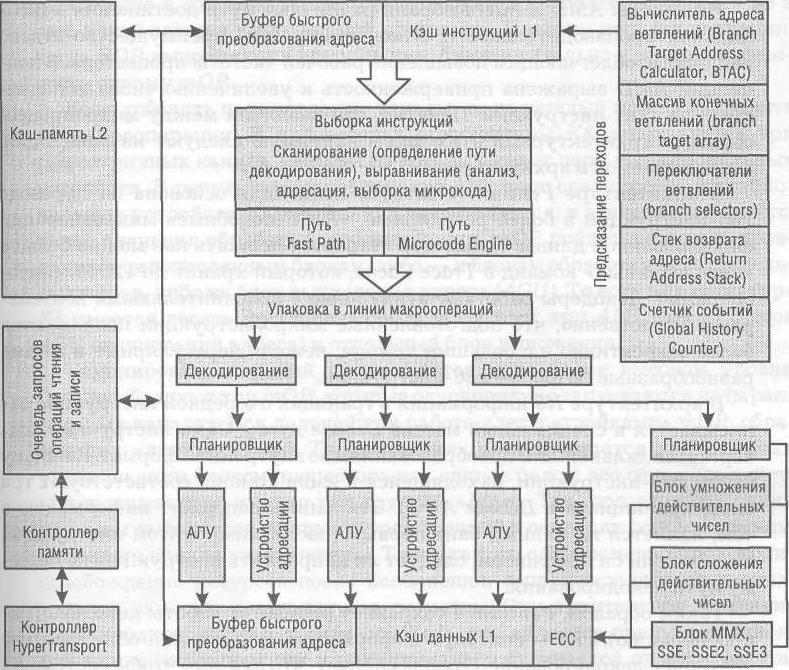
Функциональная схема микроархитектуры AMD K8
Декодеры и конвейеры
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура AMD64
Процессор архитектуры К8 получил совершенно новый декодер х86-команд, что обусловлено необходимостью обработки инструкций AMD64, поддерживающих 64-битные приложения. Не секрет, что внутренняя система команд современных процессоров х86 разительно отличается от внешней. Внешние команды для любого х86-процессора одинаковы. Но практически одинаковый программный код внутри процессоров раскладывается на совершенно разные простые инструкции, что хорошо заметно при сравнении архитектуры К8 и Pentium 4.
Инженеры AMD и Intel выбрали различные пути достижения максимальной производительности. В концепции Intel преимущество отдано решениям, облегчающим повышение рабочей частоты процессора. В концепции AMD выражена приверженность к увеличению числа исполняемых за такт инструкций. Понятно, что различия между микропроцессорными архитектурами этих фирм напрямую следуют из концепции, закладываемой в архитектуру.
В архитектуре Pentium 4 базовая концепция основана на переводе х86-инструкций в более регулярные, «RISC-подобные» микрооперации фиксированной длины. Процессор старается держать как можно больше «переведенных» команд в Trace Cache, который хранит до 12 000 микроопераций. Декодеры работают асинхронно с исполнительными конвейерами. Естественно, что подготовленные микроинструкции исполняются более эффективно и с большим темпом, нежели нерегулярные и весьма разнообразные по форме х86 -инструкции.
В архитектуре К8 информация о границах очередной инструкции записывается в специальный массив Decode Array. Сама инструкция под вергается дальнейшим преобразованиям во внутренний формат. Каждому байту х86-инструкции, находящейся в кэше команд, соответствуют три бита, хранящиеся в Decode Array. Эта запись содержит информацию о том, является ли данный байт первым (последним) байтом инструкции, является ли он префиксом, следует ли направлять инструкцию по особому пути декодирования.
Таким образом, Pentium 4 сохраняет результат работы декодера (микрооперацию), а К8 — полезную информацию, существенно облегчающую повторное декодирование. Отсюда следует, что для того чтобы система К8 могла использовать все преимущества большого кэша команд, она должна обладать совершенным механизмом повторного декодирования. Такой механизм реализован в декодере следующим образом.
Внешние инструкции на завершающих этапах работы декодера «переводятся» в специальные внутренние команды — макрооперации (тОР). Большинству х86-инструкций соответствует одна макрооперация, некоторые инструкции преобразуются в две или три тОР, а наиболее сложные, например деление или тригонометрические функции, — в последовательность из нескольких десятков тОР. Макрооперации имеют фиксированную длину и регулярную структуру.
Макрооперация в определенный момент раскладывается на две простейшие микрооперации (ROP), одновременно посылаемые на исполнение функциональным элементам процессора (ALU или FPU). Для этого тОР содержит всю необходимую для запуска двух команд информацию, включая служебную. Объединение ROP в макрооперации позволяет сократить количество перемещаемых блоков данных и число промежуточных операций записи/считывания результата. При этом ROP направляются на исполнение в том порядке, который окажется наиболее удобным, а не в том, какой задан в выполняемой программе. Поэтому нередки ситуации, когда ROP выполняются вперемешку, безотносительно к их принадлежности одному тОР.
Если добавить параллельные каналы, то на каждый можно направить по макрооперации. В процессорах архитектуры К8 используется три симметричных канала, каждый из которых имеет пару функциональных устройств. В результате одновременно работают сразу шесть функциональных устройств. Каждый канал разветвляется: в зависимости от того, какие значения обрабатывает инструкция, тОР пойдет либо по направлению к целочисленным блокам, либо — к блокам обработки действительных чисел, либо на блок вычисления адреса (AGU). То есть в архитектуре К8 имеется десять функциональных устройств: три ALU, три FPU, три AGU (вычисления адреса) и отдельный блок умножения.
Группировка операций продолжается и на более высоком уровне.
Группу образуют три тОР, которые одновременно запускаются на параллельных каналах. Вся дальнейшая работа идет с «тройками» тОР, образующих «линию» (Line). Такая «линия» воспринимается центральным управляющим блоком процессора как единое целое: все основные действия выполняются именно над группой «Line». Так, под «линию» одним приемом выделяется группа из трех позиций в очередях (как мы помним, у каждого канала своя очередь). Точно так же одновременно происходит освобождение ресурсов после исполнения, сопровождающееся окончательной записью результатов в регистры. Эту архитектуру компания AMD характеризует как «line-oriented», она является предметом законной гордости корпорации и принципиально отличается от архитектуры Pentium 4.
Контроллер памяти
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура AMD64
Интегрированный контроллер памяти микроархитектуры К8 — уникальное явление среди процессоров для настольных систем. Во всех остальных вариантах (Pentium 4, Celeron, Pentium M, AthlonXP, Sempron) контроллер памяти размещается в микросхеме набора системной логики. Внедрение контроллера в архитектуру процессора позволило лучше согласовать возможности процессорного ядра и памяти. В оптимальном варианте пропускная способность памяти должна быть больше максимального потока данных, обрабатываемых процессором, а задержки (латентность) памяти должны быть минимальными.
Что касается пропускной способности, то процессор Athlon 64 (Socket 939) с частотой 1400 МГц в 32-битном режиме выдает «на гора» поток данных до 5,6 Гбайт/с. Двухканальная память DDR400 обеспечивает пропускную способность 6,4 Гбайт/с. В этом аспекте проблем не возникает. Но каковы задержки обращения к памяти? Оказывается, всего 65 тактов. То есть время доступа к памяти составляет 33 наносекунды. Это намного меньше показателей, демонстрируемых классическими чипсетами с интегрированным контроллером памяти. Например, платформа Pentium 4 + i925 + dual channel DDR400, самая быстрая среди конкурентов, обеспечивает время доступа к памяти 63 наносекунды.
Благодаря небольшим задержкам контроллер процессора Athlon 64 обеспечивает эффективность памяти до 96% от теоретической пропускной способности, что с лихвой покрывает потребности платформы. В целом эффективность встроенного контроллера можно охарактеризовать как великолепную. Впервые архитектура процессоров AMD обеспечивает равные или лучшие по сравнению с процессорами Intel показатели эффективности памяти.