
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Базовая организация ЭВМ
Архитектура ЭВМ
В данном разделе мы ознакомимся с основными принципами работы ЭВМ. Узнаем о особенностях построения и взаимодействия всех компонентах.... А так же многое многое друге. Этот раздел будет познавательным как для начинающих так и для "прошаренных" пользователей.....
Регистры. Шины. Вентили (Gates)
- Подробности
- Родительская категория: Процессор
- Категория: Процессор — аппаратный уровень.
Регистры
Регистр хранит двоичное слово. Регистр — это линейка триггеров, которые имеют входы для изменения состояния, влияющее на выходы.
Регистры могут быть:
- программно-видимые явно;
- видимые косвенно, такие, накпример, как "теневые" регистры дескрипторов сегментов;
- внутренние, предназначенные для специальных целей, например, регистр адреса памяти и регистр данных для обмена с памятью — про них ,по крайней мере, известно, для чего они предназначены;
- внутренние — для хранения внутренних промежуточных результатов и т.д.
Кроме того, в процессоре могут быть "псевдо-регистры", хранящие константы: 0, 1, -1, и др. (м.б. такие, как , e,...).
Шины
Это просто группа параллельных проводов, связывающих между собой два адресата и позволяющих передать слово данных параллельным кодом.
Вентили
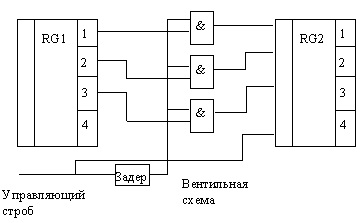
Регистры операционного устройства
Это логические элементы (коньюнкторы), разрешающие передачу данных (например, на вход триггера). Схема передачи слова данных от источника к приемнику изображена выше на рисунке. Она обеспечивает возможность управлять моментом передачи, подавая в нужный момент сигнал "строб". Слово данных от источника данных (им может быть другой регистр) подается на входы элементов "И". Выходы элементов "И" (вентилей) действуют на входы установки регистра-приемника. Для записи нового кода в регистр-приемник надо последовательно выполнить два действия:
- сбросить старый код в регистре,
- разрешить запись сигналом, подаваемым на вторые входы вентилей. Второй сигнал задержан относительно первого (в элементе задержки).
Несколько вентильных линеек В1, В2,...могут быть объединены по выходам линейкой элементов "ИЛИ". Такая структура позволяет передавать слово данных на вход регистра-приемника от одного из нескольких источников при действии разных стробовых сигналов. Такую структуру принято называть мультиплексором (ниже на рисунке).
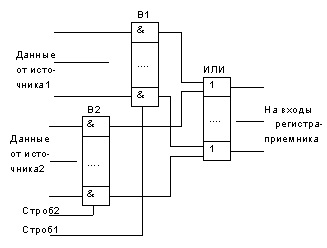
Простейший мультиплексор
Микропрограммный автомат с жесткой логикой. Микропрограммный автомат с программируемой логикой
- Подробности
- Родительская категория: Процессор
- Категория: Устройство управления. Микропрограммный автомат
Микропрограммный автомат с жесткой логикой
Тип микропрограммного автомата определяет название всего УУ. В микропрограммном автомате с жесткой логикой (см. рисунок ниже) выходные сигналы управления реализуются за счет однажды соединенных логических схем. Микропрограммный автомат с жесткой логикой. Код операций (КОП), хранящийся в регистре команды, используется для определения того, какие сигналы управления и в какой последовательности должны формироваться. При этом, желательно иметь в УУ отдельный логический сигнал для каждого кода операции (IK). Это может быть реализовано с помощью дешифратора.
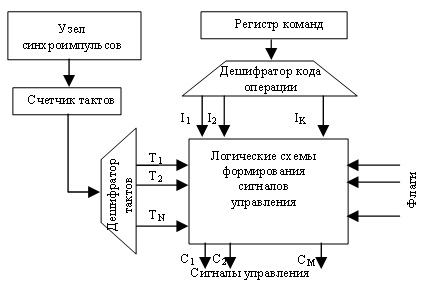
Микропрограммный автомат с жесткой логикой
Сигналы управления, по которым выполняется микрооперация, должны вырабатываться в строго определенные моменты времени, поэтому все сигналы управления "привязаны" к импульсам синхронизации. Счетчик тактов сбрасывается (устанавливается в состояние Т1) по окончании цикла очередной команды. Цикл команды может потребовать разного количества тактов. На каждом такте вырабатывается своя микрокоманда, состоящая из нескольких сигналов управления. Дополнительным фактором, влияющим на выработку сигналов управления, являются флаги.
Микропрограммный автомат с программируемой логикой
Отличительной особенностью микропрограммного автомата с программируемой логикой является наличие памяти микропрограмм. Каждой команде вычислительного устройства в этой памяти соответствует микропрограмма. Идею микропрограммирования сигналов управления предложил в 1951 г. Морис Уилкс (Кембриджский университет, Британия). ЭВМ стала иметь три уровня выполнения команд: между командами и сигналами управления появилась микропрограмма. Команда ЭВМ интерпретировалась в микропрограмму. Аппаратное обеспечение должно было выполнять только микропрограммы с ограниченным набором микрокоманд, отсюда существенно уменьшались аппаратные затраты. К 70-м годам идея о том, что написанная программа сначала должна интерпретироваться микропрограммами, а не выполняться непосредственно электроникой, стала преобладающей. Однако в современных процессорах, когда аппаратные затраты стали менее существенны, отказались от идеи микропрограммирования, так как она стала сдерживать рост производительности. Типичная схема микропрограммного автомата приведена на рисунке ниже.
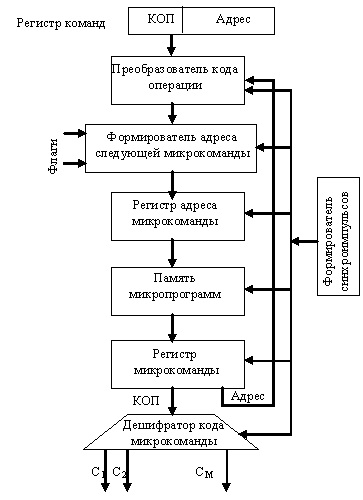
Микропрограммный автомат с программируемой логикой
Запуск микропрограммы выполнения операции осуществляется путем передачи кода операции из регистра команды на вход преобразователя, в котором код операции (КОП) преобразуется в начальный адрес микропрограммы. Выбранная по этому адресу из памяти микропрограмм микрокоманда заносится в регистр. Микрокоманда содержит КОП и адресную часть. КОП поступает на дешифратор и формирует управляющие сигналы, адрес передается для формирования адреса следующей микрокоманды. Этот адрес может зависеть от флагов, КОП, внешних устройств.
Стековая архитектура
- Подробности
- Родительская категория: Процессор
- Категория: Архитектуры системы команд
Стеком называется память, состоящая из взаимосвязанных ячеек, взаимодействующих по принципу "последним вошел — первым вышел" (LIFO, Last In First Out).
Верхнюю ячейку называют вершиной стека. Для работы со стеком предусмотрены две операции: рush (проталкивание данных в стек) и рор (выталкивание данныx из стека). Запись возможна только в верхнюю ячейку стека, при этом вся хранящаяся в стеке информация предварительно проталкивается на одну позицию вниз. Чтение допустимо также только из вершины стека. Извлеченная информация удаляется из стека, а оставшееся его содержимое продвигается вверх. В вычислительных машинах, где реализована АСК на базе стека (их обычно называют стековыми), операнды перед обработкой помещаются в две верхних ячейки стековой памяти. Результат операции заносится в стек.
В большинстве процессоров стек (т.е. память со стековым доступом) организован в участке обычной памяти с адресной организацией. Для этого в процессоре имеется специальный регистр — указатель стека (Stack Pointer SP). Этот регистр содержит адрес памяти того участка, в который будет осуществляться стековый доступ, а, говоря более точно, адрес "верхушки стека". Указатель стека обычно программно доступен, то есть к нему можно производить обращение как к любому другому регистру.
При описании вычислений с использованием стека обычно используется иная форма записи математических выражений, известная как обратная польская запись (обратная польская нотация), которую предложил польский математик Я. Лукашевич. Особенность ее в том, что в выражении отсутствуют скобки, а знак операции располагается не между операндами, а следует за ними (постфиксная форма). Последовательность операций определяется их приоритетами. Выражение а = а + b + а х с в постфиксной форме будет записано в виде: а = а b + а с х +.
АСК на основе стека долгое время считался неперспективным. Однако в послнеднее время возрождается интерес к стековой архитектуре ВМ. Это связано с популярностью языкa Java и расширением сферы применения языка Forth, семантике которых наиболее близка именно стековая архитектура.
Способы адресации при адресной организации памяти
- Подробности
- Родительская категория: Процессор
- Категория: Способы адресации
Понятие косвенной адресации
Пусть какой-нибудь способ адресации (1) указывает место положения операнда (неважно, регистр процессора или адрес в памяти). Можно представить себе другой способ адресации (2), во всем аналогичный способу (1) за исключением того, что в указываемом месте расположен не сам операнд, а его адрес, т.е. номер ячейки в ОЗУ, где находится операнд. Тогда будем говорить, что способ (1) — прямой, а соответствующий ему способ (2) — косвенный по отношению к способу (1). В символике языков ассемблера для обозначения косвенности используются скобки или символ @.
1) add ax,loc — эта ассемблерная запись означает "прибавить к содержимому регистра AX содержимое ячейки памяти, адрес которой обозначен символическим именем LOC”.
2) ADD AX,(LOC)или ADD AX,@LOC — в этой записи используется косвенная адресация, запись означает "прибавить к содержимому регистра AX содержимое ячейки памяти, адрес которой хранится в ячейке памяти с символическим именем LOC”.
Можно провести аналогию между использованием косвенной адресации в языке ассемблера и использованием указателей в языке Си. В строке iA+ = iB ; обращение к операнду iB произойдет с использованием прямой адресации. Строка iA+ = *piB; использует косвенную адресацию переменной через указатель piB = &iB. По индукции можно представить себе двойную, тройную косвенность и т.п. Существовали компьютеры, в которых была реализована косвенность произвольной глубины. Рассмотрим теперь конкретно различные способы адресации. При рассмотрении использованы мнемоники ассемблера для процессоров i*86. Используемый в команде способ адресации кодируется в адресном поле операнда. За исключением непосредственной и абсолютной адресации, адресное поле указывает на адресный регистр (может быть на несколько) и задает способ вычисления адреса с участием содержимого этого регистра (ов).
Неявная (inherent) адресация
Этот термин относится не к способу вычисления адреса (местоположения) операнда, а к способу обозначения этого местоположения в синтаксисе ассемблера. Например, команда "поместить в стек”: push ax.

Никаких вычислений для определения адреса операнда делать не надо, операнд выбирается из ОЗУ вслед за командой. Операнд может быть разной длины (занимать разное число ячеек/байтов).
Абсолютная или прямая адресация
В команде за КОП помещается заранее известный адрес операнда. Обратите внимание, что абсолютная адресация является косвенным вариантом для непосредственной адресации. add cx, [123] ; содержимое регистра складывается с содержимым ячейки, абсолютный адрес которой входит в состав команды (см. рисунок).
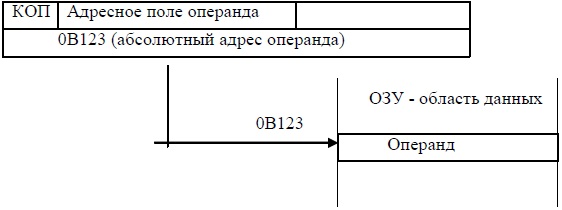
Для выборки операнда нужно дополнительное обращение к ОЗУ.
Регистровая адресация
Операнд находится в одном из регистров процессора. sub bx, si ; вычитаются два операнда, находящиеся в регистрах процессора (см. рисунок ниже).
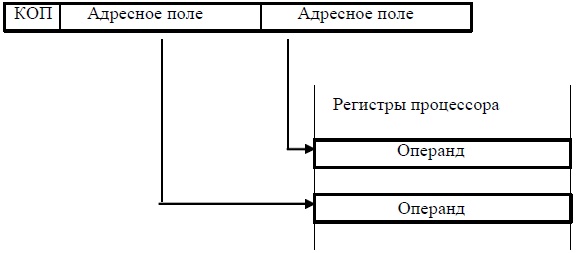
Обращение к регистру процессора гораздо быстрее, чем к ячейке ОЗУ. Код регистра занимает более короткое поле в команде, чем операнд или адрес.
Косвенно-регистровая адресация
Адрес операнда находится в одном из регистров процессора. Во многих процессорах регистры специализированы, и адрес может находиться не в любом из них (см. рисунок ниже).
mov [si], 12
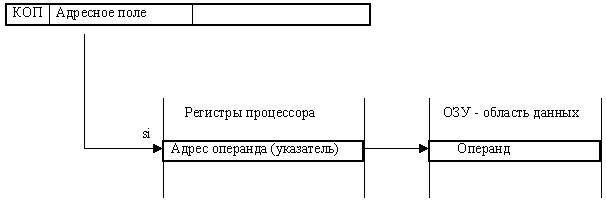
Указатель регистра Ri занимает более короткое поле чем адрес. Тот факт, что адрес операнда находится в регистре, позволяет вычислять или модифицировать этот адрес, при этом один и тот же участок программы может обрабатывать разные элементы данных (находящиеся в разных адресах).
Вот фрагмент, суммирующий в регистре ax элементы массива слов:
mov si, "начальный адрес массива"
mov cx, "количество элементов массива"
ckl add ax, [si]; прибавляем следующий элемент
add si, 2; модифицируем адрес в массиве
loop ckl; организуем цикл
Выделенные команды эквивлентны Си-фрагменту sum += *(piMas++); .
Автоинкрементная (автодекрементная) адресация
Модификация адреса, находящегося в адресном регистре, — частая и типичная операция (см. предыдущий пример). Во многих процессорах существует усовершенствованная разновидность косвенно-регистровой адресации, которая совмещает обращение к памяти по адресу, содержащемуся в регистре и модификацию адреса (содержимого регистра). Такая адресация называется автоинкрементной, если адрес, хранящийся в регистре, автоматически увеличивается при обращении к операнду, или автодекрементной, если адрес автоматически уменьшается. Общее название для этих двух типов адресации — автоиндексная (или адресация с автоиндексацией).
В ходе выполнения команды с данным типом адресации после (либо до) выборки операнда из ОЗУ содержимое регистра Ri модифицируется: к его старому содержимому прибавляется число L — длина операнда в байтах (в минимальных адресуемых единицах). Таким образом после этой модификации в Ri оказывается адрес следующего элемента данных. Автоинкрементная адресация позволяет обращаться к элементам данных, расположенных в памяти подряд по возрастанию адресов (например, к элементам массива). При автодекрементной адресации сложение с L заменяется на вычитание, и элементы данных перебираются в порядке убывания их адресов (см. рисунок ниже).
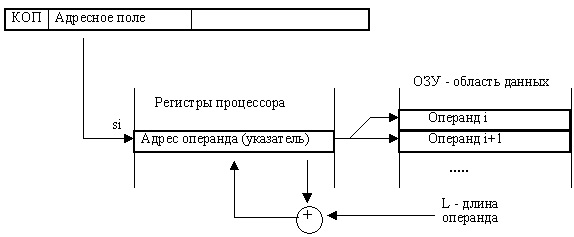
Величина L, на которую происходит увеличение или уменьшение адреса, в простейшем случае равна минимальной адресуемой единице (байту). Однако, если процессор поддерживает операции с операндами разной длины (байт, слово, двойное слово,...), то и автоиндексация/ декремент может быть реализован на 1, на 2, на 4, ...
Если модификация адресного регистра происходит после обращения к операнду, такую разновидность называют постинкрементной адресацией, если модификация адреса выполняется перед обращением к операнду — преинкрементной. Наиболее часто в процессоре реализуется сочетание постинкрементной и предекрементной адресации. В процессорах i*86 автоиндексная адресация в общем виде (т.е. для использования в произвольной команде) не реализована. Однако в неявном виде она использована в командах операций со строками. Например, при выполнении команды LODS происходит загрузка в регистр AL (или AX или EAX) содержимого ячейки памяти, на которую указывает адресный регистр SI, после чего содержимое регистра SI автоматически модифицируется.
Многокомпонентные способы формирования адреса
Многокомпонентное формирование адреса тесно связаны с идеей относительной адресации. Если отсчитывать адреса объектов программы от места, жестко привязанного к программе (например, от ее начала), то эти относительные значения не меняются, куда бы ни была загружена программа. То же можно сказать и про любую часть программы (например, про участок памяти с данными). Как же можно осуществить такую относительную адресацию?
Для этого можно формировать адрес из двух слагаемых:
•Одно (базовый адрес) зависит от того, куда загружаем программу, задается перед загрузкой, и в течение всего времени выполнения программы остается неизменным (но от загрузки к загрузке может изменяться).
•Второе (относительный адрес) представляет собой разность базового адреса и абсолютного адреса объекта. Адрес задается не как абсолютное значение, а как смещение относительно какого-либо базового значения.
Хочется обеспечить позиционную независимость (без пересчета адресных частей команд). Если вспомним, что после трансляции загружаемый (двоичный) образ программы не меняется, можем высказать идею отсчитывать адреса относительно чего-то в самой программе. Идея формировать адрес как комбинацию (сумму или конкатенацию) нескольких компонент используется как в способах адресации, так и при трансляции адресов. Между понятиями "способ адресации" и "процедура трансляции адреса" непросто провести более-менее четкую границу. Та часть преобразования адресной информации, которая изменяется от одной команды к другой — способ адресации. Трансляция адреса — часть преобразования адреса, одинаковая для разных команд. Трансляцией адреса тоже можно управлять (например, включить или выключить трансляцию страниц), однако это переключение выполняется редко, после чего значительная часть программы выполняется в заданном единожды режиме.
Многокомпонентные способы адресации
Во всех предыдущих случаях адрес операнда хранился где-то в одном месте и выбирался сразу весь, целиком. При реализации многокомпонентного формирования исполнительного адреса, он формируется в результате выполнения арифметически действий над несколькими числами, хранящимися в разных местах (в регистрах или в ячейках памяти). Эти действия (адресную арифметику) автоматически делает при выполнении команды (а именно на этапе вычисления исполнительного адреса) специальная схемотехника процессора . В простейшем случае адрес формируется путем конкатенации компонент, в более сложном случае используется сложение с учетом переносов. Такая организация адресации может обеспечить следующие преимущества:
•а) При вычислении адреса элемента в сложной структуре данных часть действий по этому вычислению можно возложить на адресную арифметику. Например, требуется определить адрес элемента двумерного массива с индексами i, j, если начальный адрес массива AddrM, длина строки массива LStr, а длина одного элемента LElm. Формула для вычисления адреса имеет вид:
Addr(i,j) = AddrM + LStr * (i-1) * LElm + (j-1) * LElm
При использовании многокомпонентной адресации, использующей три компоненты (например, базово-индексной адресации со смещением в процессорах i*86) с компонентами можно связывать адрес начала массива, смещение в массиве от начала до нужной строки и смещение в строке до нужного элемента. Сложение компонент выполнит автоматически адресная арифметика.
•б) Компонента адреса, хранящаяся в регистре или в команде, может быть короче полного адреса (и, значит, занимать меньше места). Это позволит адресовать более коротким полем память большего объема (см. например страничную адресацию).
•в) Возможно в любой момент перемещение в памяти блока объектов с одновременным изменением содержимого базового регистра, участвующего в формировании всех адресов при доступе к этим объектам..
•г) Использование в качестве адресной компоненты счетчика команд автоматически дает позиционную независимость (статическую и динамическую перемещаемость).
Страничная адресация
Это, пожалуй, простейший из многокомпонентных способов. Адрес разбивается на две части, которые объединяются не сложением, а конкатенацией (соединением двух частей числа). Старшая часть адреса указывает номер страницы. Она либо хранится в специальном регистре страницы (общий случай), либо берется из счетчика команд (адресация на текущую страницу), либо фиксирована (часто так делается адресация на нулевую страницу, которая используется для специальных целей). В команде (или в регистре) указывается только младшая часть адреса. Таким образом удается уменьшить длину команды.
Относительная адресация
В качестве одной из компонент при формировании адреса используется счетчик команд. При этом способе адресации операнд отстоит в памяти от команды на фиксированную величину. Иными словами, операнд указывается путем задания его смещения (displacement) в памяти относительно обращающейся к операнду команды. Использование только относительной адресации делает программы позиционно- независимыми, т.е. их можно перемещать в памяти без каких бы то ни было изменений в тексте программы. Относительная адресация используется во многих процессорах в командах условного ветвления, причем чаще всего смещение имеет формат "байт со знаком" и способно задать переход в диапазоне +127 -128 байтов.

Стековый доступ к памяти
Стековый доступ к памяти происходит в большинстве процессоров в следующих ситуациях:
1) При выполнении команд стекового доступа: "поместить в стек" pushили "извлечь из стека" pop.
2) При выполнении команды вызова подпрограммы и при возврате из нее.
3) При входе в прерывание и при возврате из прерывания.
Положение стека в адресуемой памяти определяется содержимым указателя стека. Поскольку указатель стека программно доступен, программист может задать его значение обычной командой пересылки. Например, команда mov sp,#1000h задает положение стека, начиная с адреса 1000h. При стековом доступе содержимое указателя стека используется как адрес операнда-приемника при записи в стек или как адрес операнда- источника при считывании из стека. При обращении к стеку автоматически модифицируется и содержимое указателя стека, чтобы обеспечить следующее обращение к очередной ячейке стека. Используя ранее введенную терминологию, можно сказать, что обращение к стеку происходит с использованием косвенно-регистровой адресации через указатель стека с автоиндексацией (см. таблицу ниже). В разных процессорах стековый доступ может быть реализован по-разному в нескольких аспектах:
1. Направление роста стека. Если при записи в стек, содержимое указателя стека автоматически увеличивается (и, соответственно, при считывании автоматически уменьшается), то говорят, что стек растет в сторону увеличения адресов. В противоположном случае говорят, что стек растет в сторону уменьшения адресов.
2. Если модификация указателя стека выполняется до записи и соответственно после считывания, то указатель стека всегда указывает на последнюю занятую ячейку стека. Наоборот, если модификация производится после записи и до считывания, указатель стека всегда указывает на первую свободную ячейку стека.
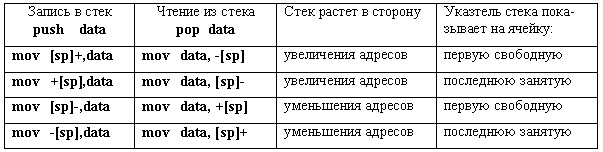
Если запись в стек происходит с преиндексацией, то считывание должно происходить с постиндексацией (и наоборот). Распространение различных видов адресации (см. таблицу ниже) зависит от типа АСК. Достаточно ясна ситуация с RISC архитектурой. Из самой идеи подхода вытекает преимущественный способ адресации: регистровая. Для аккумуляторной архитектуры главные способы адресации — прямая и непосредственная. В таблице показана частота применения разных способов адресации на двух тестовых программах для процессоров типа Intel 80x86. Видно, что наиболее активно используется прямая и базово-регистровая адресации, хотя интенсивность использования различных способов тесно связана с решаемой задачей.

Команды пересылки
- Подробности
- Родительская категория: Процессор
- Категория: Система команд процессора
Пересылки общего назначения
Пересылки общего назначения MOV, L**, LD*, LOD* (от Load — загрузить), ST* (от Store — сохранить). Передают слово/байт данных из одной части ЭВМ в другую без изменения. Иногда в эту группу включают также и команды ввода-вывода для ЭВМ у которых область адресов внешних устройств включена в общее адресное пространство.
Пересылки из/в стек
Пересылки из/в стек: PUSH (втолкнуть), POP (вынуть). Обычно отличаются тем, что используют стековую адресацию (задаваемую неявно.
Пересылки двоичных слов
Пересылки двоичных слов, представляющих собой адреса операндов или части (компоненты) адресов. Для операций с адресами нередко в процессор вводят специальные команды. Это связано с тем, что разрядность адреса в процессоре не всегда совпадает с разрядностью АЛУ и регистров.
Пересылки между элементами вычислительного ядра
Пересылки между элементами вычислительного ядра (регистры процессора, элементы памяти) и периферийными устройствами. Хотя эти команды выполняют простую передачу двоичного слова, соответствующая группа команд (называемая командами ввода-вывода) обычно рассматривается отдельно.
Еще статьи...
Подкатегории
-
Базовая организация ЭВМ
.
- Кол-во материалов:
- 11
-
Процессор
•Процессор — аппаратный уровень. Операционные устройства.
•Устройство управления. Микропрограммный автомат.
•Конвейер команд.
•Архитектуры системы команд.
•Система команд процессора.
•Способы адресации.
•Управление вычислительным процессом.
•Кодирование команд в процессоре х86.- Кол-во материалов:
- 30
-
Кодирование команд в процессоре х86
- Кол-во материалов:
- 2
-
Управление вычислительным процессом
- Кол-во материалов:
- 8
-
Способы адресации
- Кол-во материалов:
- 2
-
Система команд процессора
- Кол-во материалов:
- 6
-
Архитектуры системы команд
- Кол-во материалов:
- 5
-
Конвейер команд
- Кол-во материалов:
- 1
-
Устройство управления. Микропрограммный автомат
- Кол-во материалов:
- 2
-
Процессор — аппаратный уровень.
- Кол-во материалов:
- 4