Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Процессоры
Эксклюзивный кэш
- Подробности
- Родительская категория: Процессоры
- Категория: Архитектура AMD64
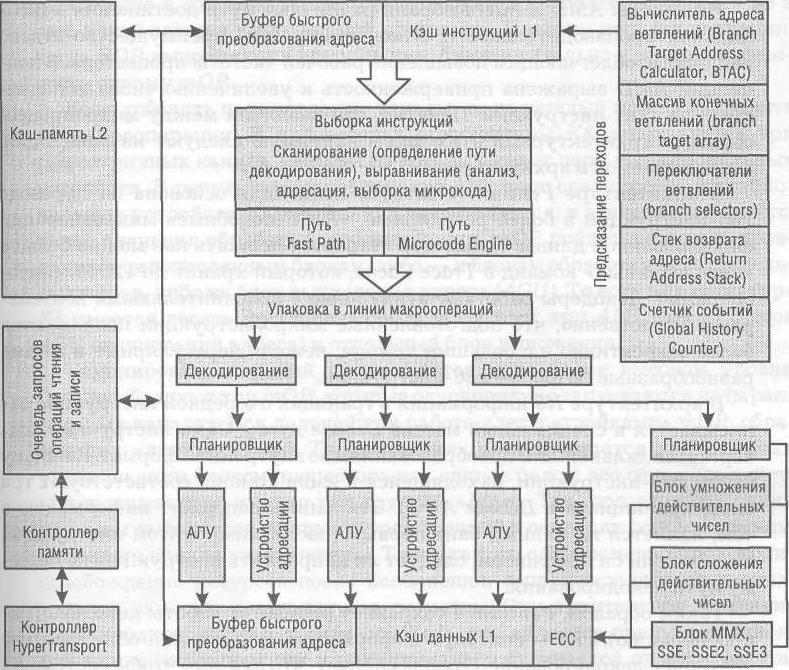
Поскольку производительность подсистемы кэширования вносит заметный вклад в общую производительность процессора, рассмотрим ее микроархитектуру подробнее. В общем случае, производительность кэш-памяти характеризуется несколькими параметрами: задержками (Latency), пропускной способностью (Throughput), типом ассоциативности и некоторыми другими. Первые два параметра влияют на производительность заметно больше остальных.
Оригинальность организации кэш-памяти процессоров AMD заключается в ее «эксклюзивности» (exclusive). Суть этой технологии в том, что содержимое кэша L1 не копируется в кэш L2, то есть они дополняют друг друга. Таким образом, суммарный объем кэша рассчитывается как сумма объемов L1 и L2. Эксклюзивная архитектура обусловливает некоторые особенности в работе кэша. Особенность первая: поскольку в процессе работы данные «складываются» прежде всего в кэш L1, то практически всегда возникает нехватка места. В этом случае кэш L1 перебрасывает самые ненужные данные в L2, а затем принимает новые. Для временного хранения перебрасываемых данных предусмотрен специальный буфер (Victim buffer). Необходимость в таком буфере возникает потому, что кэши L1 и L2 работают с разными задержками, как показано в таблице.

Вторую особенность архитектуры кэша AMD K8 хорошо иллюстрирует вариант работы с данными, которых не оказалось в кэше L1, но они есть в кэше L2. В этом случае задержки обусловлены следующими операциями. На первом этапе процессор выполняет поиск данных в кэше L1, на это уходит три такта. На втором этапе освобождается место в L1 для пересылки данных из L2. Соответственно, строка кэша сбрасывается в Victim buffer, освобождая место в L1. До окончания пересылки первого блока данных из L2 (после чего процессор может продолжить работу) необходимо еще 8 тактов.
Если буфер свободен, 8 + 3 такта дают минимальную задержку в 11 татов. Это так называемый «лучший» сценарий.
Если же Victim buffer занят, то на его очистку уходит 8 тактов. Переключение режимов записи/чтения кэша L2 занимает два такта. Еще 8 тактов тратится на перенос данных в L1. Последние два такта опять расходуются на переключение режимов записи/чтения. Таким образом, в худшем случае операция загрузки занимает 8 + 2 + 8 + 2 = 20 тактов. Это значение точно равно задержке, так как операция чтения на разделяемой 64-битной шине L1-L2 не может начаться, пока не будет закончена операция записи из Victim buffer.
По теоретической пропускной способности кэш второго уровня К7 проигрывает инклюзивному кэшу Pentium 4. Это объясняется как особенностями эксклюзивной архитектуры кэша, так и более узкой шиной (у Pentium 4 шина L1-L2 имеет ширину 256 бит). Но в реальных приложениях таких ситуаций, которые бы демонстрировали несостоятельность эксклюзивной архитектуры кэша, практически не возникает.
Разрабатывая архитектуру К8, инженеры AMD модернизировали шину кэш-памяти L1-L2. Вместо одной двунаправленной шины шириной 64 бит уровни кэша связаны двумя однонаправленными шинами шириной по 64 бита. Такое решение позволило практически полностью нивелировать отрицательные эффекты «перегруза» шины L1-L2 и снизить задержки в «худшем» варианте до 16 тактов.