
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Ввод-вывод
Ввод-вывод
Прямой доступ к памяти (ПДП)
- Подробности
- Родительская категория: Ввод-вывод
- Категория: Прямой доступ к памяти (ПДП)
В ЭВМ используются два основных способа организации передачи данных между памятью и периферийными устройствами: программно- управляемая передача и прямой доступ к памяти (ПДП).
Программно-управляемая передача данных осуществляется при непосредственном участии и под управлением процессора. Например, при пересылке блока данных из периферийного устройства в оперативную память процессор должен выполнить следующую последовательность шагов:
- Cформировать начальный адрес области обмена ОП.
- Занести длину передаваемого массива данных в один из внутренних регистров, который будет играть роль счетчика.
- Выдать команду чтения информации из УВВ. При этом на шину адреса из МП выдается адрес УВВ, на шину управления — сигнал чтения данных из УВВ, а считанные данные заносятся во внутренний регистр МП.
- Выдать команду записи информации в ОП. При этом на шину адреса из МП выдается адрес ячейки оперативной памяти, на шину управления — сигнал записи данных в ОП, а на шину данных выставляются данные из регистра МП, в который они были помещены при чтении из УВВ.
- Модифицировать регистр, содержащий адрес оперативной памяти.
- Уменьшить счетчик длины массива на длину переданных данных.
- Если переданы не все данные, то повторить шаги 3-6, в противном случае закончить обмен.
Программа чтения данных в память, реализующая описанные выше действия, может иметь следующий вид:
SETUP: MOV AX,SEGMENT ; настройка сегментного регистра
MOV DS,AX
MOV DI,OFFSET ; настройка адреса
MOV CX,COUNT ; количество байт
MOV DX,IOPORT ; DX = порт ввода/вывода
READ: IN AL,DX ; чтение байта из порта
MOV [DI],al ; сохранить данные
INC DI ; увеличить индекс
LOOP READ ; продолжить до тех пор, пока CX = 0
CONT: ...... ; продолжение программного кода
Как видно, программно-управляемый обмен ведет к нерациональному использованию мощности микропроцессора, который вынужден выполнять большое количество относительно простых операций, приостанавливая работу над основной программой. При этом действия, связанные с обращением к оперативной памяти и к периферийному устройству, обычно требуют удлиненного цикла работы микропроцессора из-за их более медленной по сравнению с микропроцессором работы, что приводит к еще более существенным потерям производительности ЭВМ.
Альтернативой программно-управляемому обмену служит прямой доступ к памяти — способ быстродействующего подключения внешнего устройства, при котором оно обращается к оперативной памяти, не прерывая работы процессора. Такой обмен происходит под управлением отдельного устройства — контроллера прямого доступа к памяти (КПДП). Структура ЭВМ, имеющей в своем составе КПДП, представлена на рисунке (см. рисунок ниже).
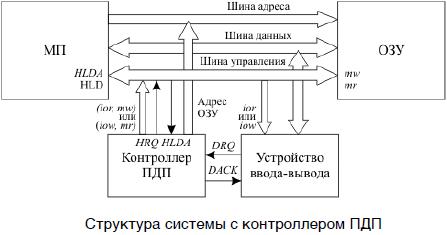
Процедура передачи данных в режиме ПДП состоит в следующем:
- Запрос DREQ (Dma REQuest) на начало передачи поступает в контроллер ПДП в виде элек-трического сигнала из внешнего устройства.
- КПДП посылает в процессор запрос канала HOLD.
- Процессор заканчивает текущий канальный цикл и предоставляет канал, о чем сообщает сигналом HLDA (предоставление канала).
- КПДП сообщает устройству ввода-вывода о начале выполнения циклов прямого доступа к памяти (DACK).
- КПДП генерирует канальные циклы (т.е. нужные адреса и последовательности управляющих сигналов), в которых между памятью и внешним устройством происходит обмен байтами (или словами).
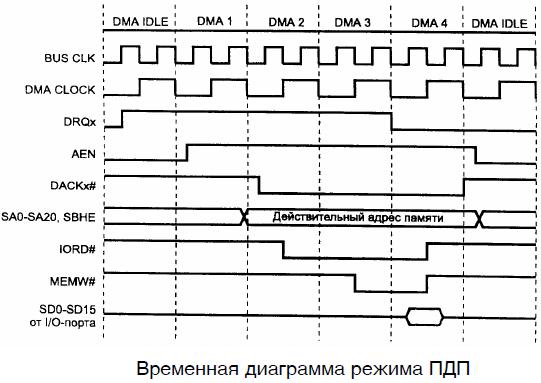
Временная диаграмма режима ПДП приведена на рисунке (см. рисунок ниже).
Перед началом обмена программа должна указать контроллеру ПДП:
- начальный адрес массива в памяти, куда (или откуда) будет передача;
- направление передачи (в память или из нее);
- количество байтов (или слов), которые надо передать;
- как реагировать на сигнал запроса......
- некоторые другие условия (см. далее описание КПДП для PC-совместимых компьютеров).
Передача массива данных по каналу состоит из последовательности так называемых циклов DMA. Цикл DMA для передач между памятью и устройством ввода-вывода представляет собой комбинацию одновременного выполнения шинных команды обращения к памяти (-MEMR или -MEMW) и команды обращения к порту (-IOW или -IOR, соответственно), во время которого на шине адреса активен адрес памяти. Активный порт в цикле DMA определяется косвенным образом по комбинации активных сигналов DRQ и -DACK. Реагировать на сигналы -IOW и -IOR в цикле DMA может только тот порт, который вызвал активизацию сигнала DRQ и получил подтверждение в виде соответствующего сигнала -DACK.
После того как один из каналов запрограммирован на необходимую передачу (запрограммирован канал контроллера DMA и регистр памяти страниц DMA), запускается устройство ввода-вывода, подключенное к этому каналу. С этого момента обслуживание обмена поручается подсистеме DMA, а микропроцессор может быть занят чем-либо другим. Когда устройство становится готовым к обмену, оно выдает запрос на обслуживание DRQ (см. рисунок ниже). Если данный канал в этот момент не замаскирован, подсистема DMA выдает запрос на захват шины у микропроцессора.
Когда микропроцессор готов освободить шину, он подтверждает запрос на захват шины сигналом HOLDA, а шина поступает в распоряжение подсистемы DMA. После этого выполняются действия по выдаче адреса ячейки памяти, с которой будет выполняться обмен по каналу контроллера DMA.
Начало передачи может происходить не только по внешнему сигналу, но и по команде, устанавливающей нужный бит в нужном порте, — по аналогии с прерыванием.
В ходе передачи КПДП может поддерживать три режима передачи:
- Одиночная передача — на каждый фронт сигнала запроса передается одно слово данных. DRQ должен быть активным, пока не активизируется соответствующий DACK. Если DRQ активен на протяжении одиночной передачи, контроллер переходит в неактивное состояние по выполнении одной передачи и освобождает шину системе.
- Передача по запросу — после подачи сигнала запроса передача продолжается до тех пор, пока сигнал запроса активен, и прекращается, если ВНУ снимает сигнал запроса, хотя передача и не завершена (т.е. не передано количество слов, указанное при программировании КПДП
- Блочная передача — после подачи сигнала запроса передаются все запрошенные слова, независимо от дальнейшего поведения сигнала запроса. DRQ должен быть активным, пока не появится активный DACK.
В качестве примера отметим шину ISA. Магистраль обеспечивает подключение до семи внешних устройств, работающих в режиме прямого доступа к памяти, и до 11 запросов прерываний от УВВ. Еще четыре запроса прерываний зарезервированы за устройствами, входящими в состав стандартной конфигурации ЭВМ, и на магистраль не выведены.
Требования к организации и решения систем ввода-вывода
- Подробности
- Родительская категория: Ввод-вывод
- Категория: Подключение периферийных устройств к ЭВМ
Организация взаимодействия и обмена информации в вычислительной информационной системе требует решения целого ряда проблем, среди которых выделим следующие:
- Возможность изменять конфигурацию: необходимо обеспечить возможность реализации ЭВМ с переменным составом оборудования, в первую очередь, с различным набором устройств ввода-вывода, с тем, чтобы пользователь мог выбирать конфигурацию машины в соответствии с ее назначением, легко добавлять новые устройства и отключать те, в использовании которых он не нуждается;
- Параллельная работа ЭВМ и ПУ: для эффективного и высокопроизводительного использования оборудования компьютера следует реализовать параллельную во времени работу процессора над вычислительной частью программы и выполнение периферийными устройствами процедур ввода-вывода;
- Унификация программирования: необходимо упростить для пользователя и стандартизовать программирование операций ввода-вывода, обеспечить независимость программирования ввода-вывода от особенностей того или иного периферийного устройства;
- Синхронизация работы ЭВМ и ПУ: в ЭВМ должно быть обеспечены автоматическое распознавание и реакция процессора на многообразие ситуаций, возникающих в УВВ (готовность устройства, отсутствие носителя, различные нарушения нормальной работы и др.).
Указанные требования решаются за счет:
- Унифицированных (независящих от типа внешнего устройства) интерфейсов;
- Унифицированных соединений;
- Унифицированного программирования.
Интерфейс — это совокупность программных и аппаратных средств, предназначенных для передачи информации между компонентами ЭВМ и включающих в себя электронные схемы, линии, шины и сигналы адресов, данных и управления, алгоритмы передачи сигналов и правила интерпретации сигналов устройствами. Интерфейсы характеризуются следующими параметрами:
- пропускная способность — количество информации, которая может быть передана через интерфейс в единицу времени;
- максимальная частота передачи информационных сигналов через интерфейс;
- максимально допустимое расстояние между соединяемыми устройствами;
- общее число проводов (линий) в интерфейсе;
- информационная ширина интерфейса — число бит или байт данных, передаваемых параллельно через интерфейс.
Основным назначением интерфейса является унификация внутрисистемных и межсистемных связей и устройств сопряжения с целью эффективной реализации прогрессивных методов проектирования функциональных элементов вычислительных систем.
Основными архитектурами соединений устройств являются:
- Каскадное соединение. Информация передается только в одном направлении: от предыдущего функционального элемента (ФЭ) к последующему. Если сообщение не адресовано данному ФЭ, она транслируется без изменений. Такая структура характеризуется малой скоростью обмена, но имеет минимальное число шин.
- Радиальное соединение. Центральный ФЭ связывается с каждым ФЭ. Такая система обладает наибольшей надежностью и производительностью, но ограничена по числу ФЭ. В ней невозможен непосредственный обмен между ФЭ.
- Магистрально-модульное соединение. Все устройства, составляющие компьютер, включая и микропроцессор, организуются в виде модулей, которые соединяются между собой общей магистралью (см. рисунок ниже). Обмен информацией по магистрали удовлетворяет требованиям некоторого общего интерфейса, установленного для магистрали данного типа. Каждый модуль подключается к магистрали посредством специальных интерфейсных схем (Иi).
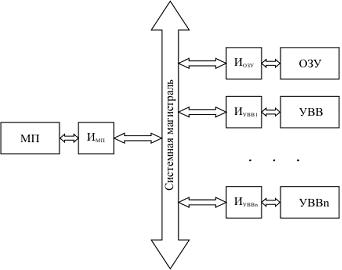
Схема магистрально-модульного соединения
На интерфейсные схемы модулей возлагаются следующие задачи:
- обеспечение функциональной и электрической совместимости сигналов и протоколов обмена модуля и системной магистрали;
- преобразование внутреннего формата данных модуля в формат данных системной магистрали и обратно;
- обеспечение восприятия единых команд обмена информацией и преобразование их в последовательность внутренних управляющих сигналов.
Эти интерфейсные схемы могут быть достаточно сложными и по своим возможностям соответствовать универсальным микропроцессорам. Такие схемы принято называть контроллерами.
Унификация программирования достигается за счет унифицированных форматов команд в ЭВМ и унифицированных форматов регистров ПУ. На уровне операционной системы унификация достигается путем использования драйверов внешних устройств.
Временные диаграммы
- Подробности
- Родительская категория: Ввод-вывод
- Категория: Шина ISA
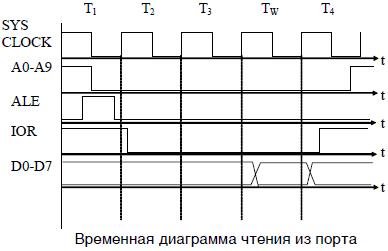
Чтение из порта ввода
Временная диаграмма операции чтения из порта (in port) занимает четыре такта опорной частоты и один такт ожидания (см. рисунок ниже). Само чтение данных происходит в начале четвертого периода. При необходимости удлинения времени чтения подают сигнал I/O CH RDY готовности канала, который увеличивает такт ожидания. Максимальное время ожидания определяется необходимостью регенерации памяти.
Запись в порт вывода
Временная диаграмма операции записи в порт (out port) занимает то же время, что и чтения из порта (см. рисунок ниже). Данные на шине находятся в течение всей длительности синхросигнала IOW.
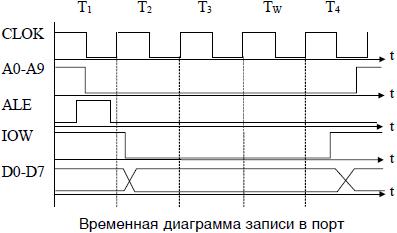
В порт можно записывать и соответственно считывать как байт так и слово (два байта). Второй байт может появиться на старших разрядах шины данных или после первого — на младших разрядах. В первом случае внешнее устройство должно сформировать сигнал IO CS16, а процессор записать в (считать из) четный адрес порта. Если сигнал IO CS16 отсутствует, то запись первого и второго байта происходит в последовательные адреса портов, причем увеличение адреса порта на шине адреса происходит автоматически. При обращении к нечетным адресам считывается и записывается младший байт.
Способы синхронизации: программный опрос готовности
- Подробности
- Родительская категория: Ввод-вывод
- Категория: Синхронизация программ с внешними процессами
Перечислим способы синхронизации:
- Программный безусловный обмен;
- Программный опрос готовности;
- Прерывание;
- Прямой доступ в память;
- Удлинение канального цикла ввода-вывода.
Простейший способ, программный опрос готовности (polling) схематично представлен на рисунке (см. рисунок ниже).
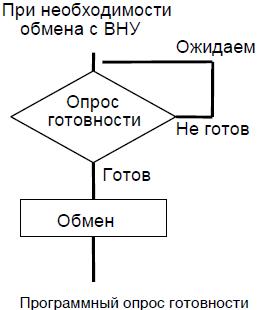
Опрос готовности состоит чаще всего в анализе состояния определенных битов в регистре статуса (состояния): при достижении состояния готовности к обмену ВНУ устанавливает этот (эти) бит(ы) в определенное состояние. Обмен с ВНУ состоит в чтении или записи в регистр данных.
Так, если приемник последовательного интерфейса принял извне байт, автоматически устанавливается флаг готовности — младший байт в порте 03FDh. Фрагмент программы, ожидаю-щий приема байта, может выглядеть так:

Недостаток: при ожидании готовности нерационально расходуется время процессора. Можно опрашивать не постоянно, а периодически, при этом появляется задержка реакции на готовность. Поэтому был разработан механизм прерывания.
Примечание: Термин “прерывание” в русскоязычной компьютерной литературе многозначен и употребляется для обозначения трех различных вещей.В англоязычной литературе используются три разных термина:
- hardware interrupt — аппаратное прерывание;
- exсeption — исключение, прерывание по исключительной (экстраординарной) внутренней ситуации;
- software interrupt — программное прерывание.

Будем далее называть подпрограмму, обрабатывающую факт наступления события, обработчиком прерывания (interrupt handler или exception handler).
Термин “обработка прерывания” может использоваться для обозначений двух различных вещей:
- действия, которые автоматически выполняет процессор при возникновении запроса, они реализованы аппаратно;
- действия, которые выполняет программа-обработчик прерывания (handler). Мы будем использовать термин “обработка прерывания” только во втором смысле, а для первой группы действий будем использовать термин “вход в прерывание”.
Механизм прерывания, его общие свойства (как это обычно делается)
- Подробности
- Родительская категория: Ввод-вывод
- Категория: Прерывания
При возникновении события, на которое надо отреагировать (запроса на прерывание), обычно процессор автоматически (без участия программиста) выполняет следующие действия:
1. Заканчивается выполнение текущей команды (иногда прерывается, если команда длинная, а иногда выполняется еще одна или несколько команд).
2. Анализируется, разрешено ли прерывание. Если нет, то осуществляется переход к выполнению следующей команды.
3. Если запросов несколько, принимается решение, какой запрос обслуживать (разрешение приоритета, priority resolving). Если система запросов радиальная или источник запроса — внутреннее событие процессора (exception), то переход к .п.6.
4. При магистральной схеме запросов:
Процессор передает источникам запросов подтверждение приема запроса (этот сигнал должен достигнуть только того источника запроса, который имеет наивысший приоритет).
5. Источник запроса передает процессору идентифицирующую его информацию (каждый источник запроса может иметь собственную программу обработки, и процессор должен узнать, какой обработчик использовать).
6. Процессор сохраняет информацию о текущем контексте (текущий вектор состояния — почти всегда неполностью).
7. Адрес перехода на программу обработки прерывания хранится в определенной для каждого источника запроса прерывания области памяти, называемой вектором прерывания. Процессор загружает начальный адрес программы обработки прерывания из вектора прерывания в счетчика команд.
8. Для возврата из прерывания в системе команд обычно есть специальная команда "возврат из прерывания" (мнемоника iret, retiили rti). По этой команде восстанавливается контекст прерванной программы в том объеме, в котором он быь сохранен при входе в перывание (п.6). Эта команда должна быть последней исполняемой командой обработчика.
Приведенное описание соответствует обработке внешнего аппаратного прерывания. В случае, если причина прерывания — внутреннее событие процессора (исключительная ситуация — exception), то этапы 4 и 5 отсутствуют, как в случае радиальных прерываний.
Опишем перечисленные этапы более детально.
1. Внешний запрос прерывания приходит асинхронно (без какой-либо привязки во времени) по отношению к выполняемому потоку команд. Произвести переход на обработчик в большинстве процессоров можно только в промежутке между выполнением соседних команд, поэтому обычно выполнение текущей команды заканчивается.
В некоторых процессорах, если время выполнения текущей команды велико, ее выполнение прерывается, а после выхода из прерывания команда начинает выполняться сначала (это, например, типично для команд плавающей точки в процессорах, где они реализованы микропрограммно). В процессорах х86 прерываются команды строковых операций, но после выхода из прерывания они не начинаются сначала, а продолжают работу с того места, где были прерваны. Некоторые комбинации команд используются совместно, и прерывание между ними может привести к фатальным результатам. Такова в х86 пара команд, переустанавливающих положение стека: для этого надо поменять содержимое регистра сегмента стека и затем содержимое указателя стека. Поскольку в х86 для сохранения контекста используется стек, то прерывание между указанными двумя командами вызовет сохранение контекста (якобы в стеке) в неверном месте памяти. Для исключения такой ситуации команда загрузки в регистр сегмента стека автоматически запрещает прерывание до окончания следующей команды.
2. В некоторых ситуациях прерывание недопустимо (например, при выполнении участков программы, критичных ко времени выполнения), поэтому во всех процессорах имеется возможность запретить прерывания (по крайней мере, некоторые). Возникшие в этот период запросы могут быть потеряны, либо могут ждать обслуживания, которое произойдет, когда прерывания будут разрешены. Это зависит от устройства конкретного процессора и от свойств входов запроса прерываний. В некоторых процессорах можно программно управлять свойствами входа: запоминается или теряется запрос, который приходит в период, когда прерывания процессору запрещены. В системе команд обычно есть команды, запрещающие и разрешающие прерывание. Кроме того, внешние устройства-источники запросов нередко позволяют программно разрешить/запретить прерывание от данного устройства (прерывания от других устройств при этом будут обрабатываться).
3. При нескольких источниках запроса возможна ситуация, когда в процессор поступают одновременно несколько запросов. Это вовсе не значит, что запросы одновременно возникают, это крайне маловероятно. Однако нередка ситуация, когда в течение некоторого времени прерывание запрещено и в этот период (не одновременно) возникает несколько запросов. Когда выполнится команда "разрешить прерывание", запросы поступают в процессор равноправно. Надо каким-нибудь способом определить порядок, в котором запросы будут обрабатываться (их приоритеты). Используется несколько способов:
•а) приоритеты фиксированы и не могут быть изменены;
•б) приоритеты определяются электрической схемой, и для их изменения надо произвести переключения в схеме;
•в) приоритеты изменяются циклически: последнему обслуженному устройству присваивается самый низкий приоритет;
•г) приоритеты могут быть программно заданы в произвольной комбинации;
•... и множество других и вариантов...
4. Далее происходит обмен сигналами между источником запроса и процессором. Сначала процессор посылает сигнал подтверждения приема запроса. В частном случае сигнал подтверждения распространяется только до устройства, наиболее близкого к процессору из всех, выставивших запрос прерывания.
5. Используется несколько способов идентификации источника прерывания. В случае магистральной архитектуры устройство обычно передает процессору по магистрали информацию о себе. Эта информация обычно содержит условный код (номер) источника запроса, по которому процессор способен определить адрес памяти, содержащий информацию о местонахождении в памяти обработчика. В качестве условного кода может использоваться адрес вектора прерывания, стартовый адрес обработчика или даже полный код команды call перехода на обработчик (так было сделано в процессоре i8080).
Термин “вектор прерывания” используют в двух разных значениях:
•а) контекст (вектор состояния) обработчика, автоматически загружаемый при выполнении прерывания,
•б) участок памяти, где хранится этот контекст. Обычно для хранения контекстов обработчиков разработчики процессора выделяют в адресном пространстве специальную область векторов прерывания.
Для некоторых из прерываний разработчики процессора могут предопределить положение векторов и значения адресов перехода, в то время как другие программист может задавать по своему усмотрению программно.
6. Сохранение текущего контекста процессор чаще всего делает в стеке. В простейшем случае сохраняется содержимое счетчика команд и содержимое регистра состояния. Во многих процессорах в регистре состояния отдельные биты имеют отношение к управлению прерываниями и автоматическое сохранение слова состояния предоставляет ряд дополнительных возможностей, а иногда является просто необходимым (см. например далее "пошаговую отладку" для процессоров х86).
7. Загрузка контекста обработчика (вектора прерывания). Результат этого действия — переход на первую команду обработчика. Используются различные способы указания того, в каком адресе памяти расположена эта первая команда. Чаще всего адрес обработчика содержится в соответствующем векторе прерывания. Существенным является вопрос о том, разрешено ли прерывание после перехода на обработчик. В большинстве процессоров при входе в прерывание повторное (вложенное) прерывание автоматически запрещается. Обработчик может разрешить прерывание соответствующей командой (например, в процессорах х86 это команда sti). В этом случае возможно "вложенное" прерывание, в том числе, и от этого же источника, но для этого обработчик прерывания должен быть реентерабельным, т.е. допускать рекурсивный вызов. Кроме того, это может привести к нарушению приоритетов: менее приоритетное событие будет обслужено раньше, чем более приоритетное.
8. Возврат из прерывания восстанавливает контекст прерванной программы. Существенно, что восстанавливается состояние "разрешено/запрещено прерывание": после возврата из прерывания возможно следующее прерывание, если есть запрос.
Еще статьи...
Подкатегории
-
Прямой доступ к памяти (ПДП)
- Кол-во материалов:
- 2
-
Программирование контроллера прерываний i8259А
- Кол-во материалов:
- 11
-
Прерывания
- Кол-во материалов:
- 9
-
Синхронизация программ с внешними процессами
- Кол-во материалов:
- 2
-
Шина ISA
- Кол-во материалов:
- 4
-
Подключение периферийных устройств к ЭВМ
- Кол-во материалов:
- 3