
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Память. Верхний уровень
Память. Верхний уровень
Трансляция адреса в реальном режиме
- Подробности
- Родительская категория: Память. Верхний уровень
- Категория: Трансляция адреса в защищенном режиме в проц-х x86
В реальном режиме сегментный регистр содержит непосредственно компоненту адреса (см. рисунок ниже).
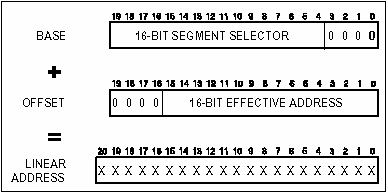
Схема трансляции адреса в реальном режиме
Для получения линейного адреса в реальном режиме содержимое сегментного регистра сдвигается на четыре позиции влево (т.е. умножается на 16) и полученный 20-битовый результат складывается с 16-битовым offset (внутрисегментным смещением), вычисленным в соответствии с используемым способом адресации). Эти действия выполняются в процессоре аппаратно блоком формирования адреса и не заметны для программиста. В каждый данный момент времени активны/ доступны программе (для 386+) шесть сегментов (по числу имеющихся в процессоре сегментных регистров).
В реальном режиме сформированный линейный адрес подается непосредственно на физическую адресную шину, т.е. в реальном режиме понятия линейного и физического адресов совпадают. Таким образом, в реальном режиме размер сегмента фиксирован. Максимальный адрес, который можно сформировать по приведенной схеме, равен 0xFFFF0 + 0xFFFF = 0x10FFEF, что дает общее количество адресов 0x10FFF0 = 0x10000 + 0x1000 — 0x10 = 220+216-24.
В реальном режиме содержимое сегментных регистров доступно прикладному программисту и может быть им изменено. Задавая содержимое сегментного регистра, программист может расположить сегмент в физическом адресном пространстве с шагом в 16 байтов.
Отладка и отладочные регистры
- Подробности
- Родительская категория: Память. Верхний уровень
- Категория: Сиситемные регистры процессоров Intel хх86
Процессор обеспечивает расширенные отладочные средства, которые, в частности, полезны для разработки сложных программных систем, таких, как мультизадачные операционные системы. Условия сбоя для этих программных систем могут быть очень сложными и зависимыми от времени. Отладочные средства процессора предоставляют системному программисту мощный инструмент просмотра динамического состояния процессора.
Отладка поддерживается посредством отладочных регистров. Они содержат адреса точек памяти, называемых контрольными точками (точками останова), которые запускают отладочное программное обеспечение. При выполнении операции с памятью по одному из этих адресов генерируется исключение. Контрольная точка задается для конкретной формы доступа к памяти, например, выборки команды или операции записи двойного слова. Отладочные регистры поддерживают как контрольные точки команд, так и контрольные точки данных.
Для других процессоров контрольные точки команд устанавливаются заменой нормальных команд командами контрольных точек. При выполнении команды контрольной точки вызывается отладчик. Однако в случае отладочных регистров процессора 386+ это не обязательно. При исключении необходимости записи в пространство кода процесс отладки упрощается (не требуется установки отображения сегментов данных в ту же область памяти, что и кодовый сегмент) и контрольные точки могут устанавливаться в ПЗУ-резидентном программном обеспечении. Кроме того, контрольные точки могут быть установлены для чтения и записи данных, что позволяет контролировать состояние данных в режиме реального времени. Доступ к этим регистрам имеют только программы с наивысшим уровнем привилегированности.
В число средств архитектуры, поддерживающих отладку, входят:
•Отладочные адресные регистры — задают адреса до четырех контрольных точек.
•Отладочный управляющий регистр — задает формы доступа к памяти для контрольных точек.
•Отладочный регистр состояния — сообщает об условиях, которые существовали в момент генерации исключения.
•Бит ловушки в TSS (T-бит) — генерирует отладочное исключение при попытке выполнить переключение задачи на задачу, для которой этот бит был установлен.
•Флаг возобновления (RF) — подавляет возобновление множественных исключений для одной и той же команды.
•Флаг трассировки (TF) — генерирует отладочное исключение после каждого выполнения команды.
•Команда контрольной точки — вызывает отладчик (генерирует отладочное исключение). Данная команда является альтернативным способом установки контрольныхточек в коде. Она особенно полезна, когда желательно иметь более четырех контрольных точек, либо при помещении контрольных точек в исходный код.
•Резервируемый вектор прерывания для исключения контрольной точки — вызывает процедуру или задачу при выполнении команды контрольной точки.
Эти средства позволяют вызывать отладчик как отдельную задачу или процедуру в контексте текущей задачи.
Для вызова отладчика могут быть использованы следующие условия:
•Переключение на конкретную задачу.
•Выполнение команды контрольной точки.
•Выполнение любой команды.
•Выполнение команды по заданному адресу.
•Чтение или запись байта, слова или двойного слова по конкретному заданному адресу.
•Запись в байт, слово или двойное слово по заданному адресу.
•Попытка изменить содержимое отладочного регистра.
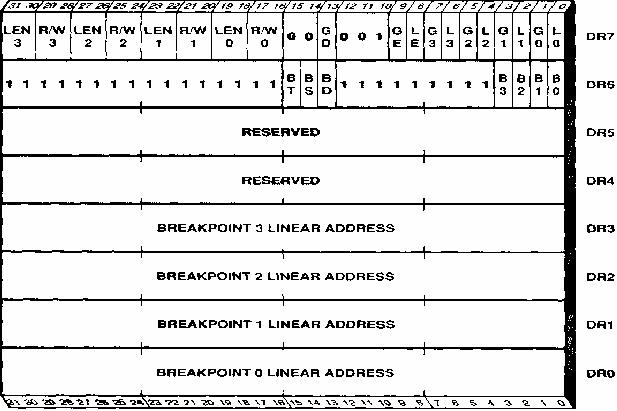
Формат регистров отладки
Правила выборки, размещения, замены страниц
- Подробности
- Родительская категория: Память. Верхний уровень
- Категория: Виртуальная память
Правила выборки страниц (fetch policy)
Методы выборки определяют правила выбора загружаемой в память страницы. Известны три правила:
1. Подкачка по требованию. Очередная страница в физическую память загружается только при страничной ошибке, а именно, только при отсутствии нужной страницы. При начальной загрузке программы или массива вызывается множество страничных ошибок, а затем интенсивность потока страничных ошибок снижается.
2. Подкачка по требованию с кластеризацией. При страничной ошибке загружается не только страница, вызвавшая ошибку, но и несколько последующих страниц. Эта стратегия обеспечивает минимизацию числа операций ввода-вывода, связанных с подкачкой. Размер кластера зависит от объема цизической памяти и составляет 2-8 страниц.
3. Упреждающая подкачка. Страница в ОЗУ загружается еще до того момента, когда она потребуется, т.е. по предположению. Эта стратегия обеспечивает максимальное быстродействие в системе. Однако, трудно определить какая страница понадобиться в будущем и возможны случаи, когда загружается не нужная страница.
Правила размещения (placement policy)
Определяют местоположения подкачиваемой страницы в памяти с учетом размеров кэшей и стремления свести нагрузку на них к минимуму. В мультипроцессорных сиcтемах правила размещения страниц по узлам системы определяются программным обеспечением.
Правила замены (replacement policy)
Политика замещения определяет какую страницу можно убрать из памяти при вызове новой страницы. Выбирать такую страницу наугад нельзя. Если, например, убрать из памяти страницу с командой, которая вызвала ошибку, то при повторном выполнении команды или при выполнении следующей команды произойдет еще одна ошибка из-за отсутствия страницы. Необходимо удалять из памяти те страницы, которые не будут нужны долгое время. Однако будущее использование страниц предсказать невозможно, поэтому используют алгоритмы основываясь на истории обращиний к страницам. Эти алгоритмы очень похожи на метода замещения кэш-строк.
LRU ( Least Recently Used). Замещается та страница, к которой дольше всего не было обращения.
FIFO (First In First Out). Здесь заменяется страница, дольше всего находившаяся в памяти.
Правила замены могут быть глобальными или локальными. При глобальной замене выгружается самая старая страница всех процессов, а при локальной — только текущего, при работе которого произошла страничная ошибка.
За счет виртуального механизма решаются следующие вопросы:
- Выполнение программы, объем которой превышает объем физической памяти.
- Независимость работоспособности программы от места ее расположения в физической памяти и от конфигурации этой памяти.
- Динамическое распределение памяти.
- Независимость (легкая сопрягаемость) разрядности компонентов логических адресов в программе (указателей), разрядности линейного адреса, разрядности физического адреса и реального объема памяти, установленной в системе.
Способы планирования
- Подробности
- Родительская категория: Память. Верхний уровень
- Категория: Многозадачность
1. Невытесняемое планирование. Новая задача переходит в состояние Running, если предыдущая задача закончила свое выполнение или перешла в состояние Waiting.
2. Посностью вытесняемое планирование (см. рисунок ниже). Задача вытесняется задачей с более высоким приоритетом. Така ситуация может быть в двух случаях: пришла задача большего приоритета или приоритет текущей задачи понизился. Когда задача вытесняется она встает в очередь готовых задач соответствующего уровня приоритета. На рисунке задача (поток) с приоритетом 18 выходит из состояния ожидания и захватывает процессор, вытесняя выполняемую в этот момент задачу (с приоритетом 16) в очередь готовых потоков. Заметьте, что вытесненная задача помещается не в конец, а в начало очереди. После завершения вытеснившей задачи вытесненная сможет отработать остаток своего времени.
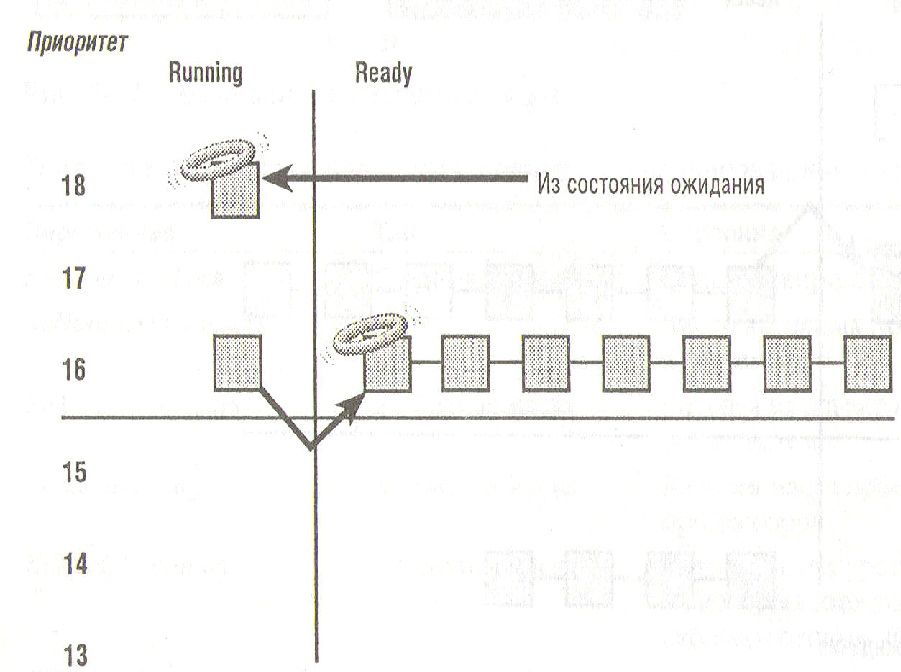
Полностью вытесняемое планирование
3. Круговое планирование. Используется операция уступить новой задаче. Такое планирование может применяться для задач одного приоритета.
4. Завершение кванта. Каждой задаче выделяется квант времени. По окончании выполняется другая задача с текущим уровнем приоритета. Если такой нет, то второй квант времени выполняется первая задача. Вытесненная задача ставится в очередь задач данного приоритета (см. рисунок ниже) и переводится из состояния Running в состояние Ready. В Win 2000 у каждой задачи (потока) свое значение кванта. Это значение выражается не в единицах времени, а целым числом в так называемых квантовых единицах. Минимальный квант (6 единиц) по умолчанию равен двум интервалам системного таймера. Максимальный соответствует 36 единиц. Длительный квант в ряде случаев позволяет свести к минимому переключения контекста. Получая больший квант программы обслуживания клиентского запроса (в серверах) имеют больше шансов выполнить запрос и вернуться в состояние ожидания до истечения выделенного кванта. Длина временного интервала таймера зависит от аппаратной платформы и на большинстве однопроцессорных х86систем составляет 10 мс, а на бльшинстве многопроцессорных систем — 15 мс. Величиной выделенного кванта можно управлять, в частности динамически приращивая квант при круговом планировании.
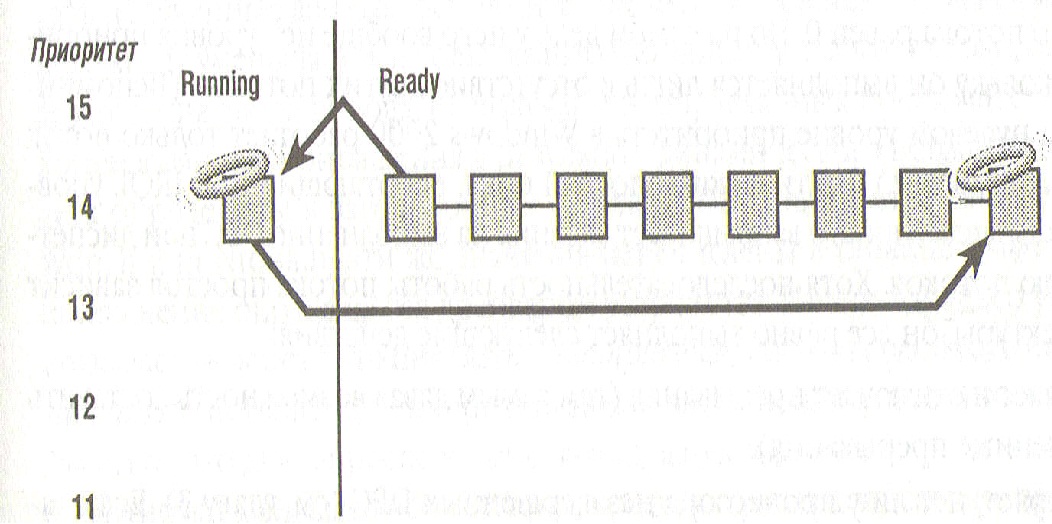
Завершение кванта
5. Адаптивное планирование (см. рисунок ниже). Основано на динамическом изменении приоритетов задач. По истечении выделенного кванта приоритет задачи снижается. Если с текущим уровнем приоритета нет задач, задача выполняется следующий квант, и приоритет снова снижается и так далее до базового. Если задача долгое время не выполнялась, то ее приоритет возрастает до тех пор, пока она не начнет выполняться. На рис. показан этот процесс. Техника назначения приоритетов и их изменения полностью определяется уровнем ОС.
6. Планирование по расписанию. Данное планирование предполагает использование комбинации разных способов.
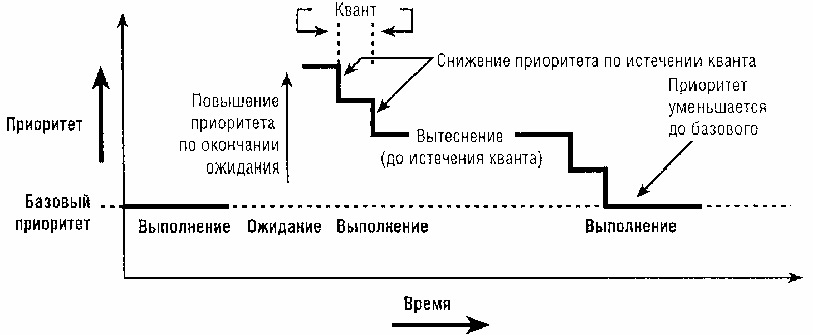
Адаптивное планирование
RAID 2: Матрица с поразрядным расслоением
- Подробности
- Родительская категория: Память. Верхний уровень
- Категория: Дисковые массивы и уровни RAID(RAID массивы)
Один из путей достижения надежности при снижении потерь емкости памяти может быть подсказан организацией основной памяти, в которой для исправления одиночных и обнаружения двойных ошибок используются избыточные контрольные разряды. Такое решение можно повторить путем поразрядного расслоения данных и записи их на диски группы, дополненной достаточным количеством контрольных дисков для обнаружения и исправления одиночных ошибок. Один диск контроля четности позволяет обнаружить одиночную ошибку, но для ее исправления требуется больше дисков.
Такая организация обеспечивает лишь один поток ввода/вывода для каждой группы, независимо от ее размера. Группы большого размера приводят к снижению избыточной емкости, идущей на обеспечение отказоустойчивости, тогда как при организации меньшего числа групп наблюдается снижение операций ввода/вывода, которые могут выполняться матрицей параллельно.
При записи больших массивов данных системы уровня 2 имеют такую же производительность, что и системы уровня 1, хотя в них используется меньше контрольных дисков и, таким образом, по этому показателю они превосходят системы уровня 1. При передаче небольших порций данных производительность теряется, так как требуется записать или считать группу целиком, независимо от конкретных потребностей. Таким образом, RAID уровня 2 предпочтительны для суперкомпьютеров, но не подходят для обработки транзакций. Компания “Thinking Machine” использовала RAID уровня 2 в ЭВМ Connection Machine при 32 дисках данных и 10 контрольных дисках, включая 3 диска горячего резерва.
Недостаток массива RAID 2 в том, что для его функционирования нужна структура из почти двойного количества дисков, поэтому такой вид массива не получил распространения.
Еще статьи...
Подкатегории
-
Сиситемные регистры процессоров Intel хх86
- Кол-во материалов:
- 3
-
Трансляция адреса в защищенном режиме в проц-х x86
- Кол-во материалов:
- 11
-
Дисковые массивы и уровни RAID(RAID массивы)
- Кол-во материалов:
- 9
-
Многозадачность
- Кол-во материалов:
- 4
-
Общие принципы защиты памяти
- Кол-во материалов:
- 1
-
Виртуальная память
- Кол-во материалов:
- 3
-
Динамическое распределение памяти
- Кол-во материалов:
- 1