
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
программа для поиска автозапчастей.
Шина IEEE 1394 — FireWire
Шина IEEE 1394 — FireWire
Введение
- Подробности
- Родительская категория: Шина IEEE 1394 — FireWire
- Категория: Основная информация
Высокопроизводительная последовательная шина (High Performance Serial Bus) IEEE 1394 — FireWire создавалась как более дешевая и удобная альтернатива параллельным шинам (SCSI) для соединения равноранговых устройств. Шина позволяет связать до 63 устройств без применения дополнительной аппаратуры (хабов). Устройства бытовой электроники — цифровые камкордеры (записывающие видеокамеры), камеры для видеоконференций, фотокамеры, приемники кабельного и спутникового телевидения, цифровые видеоплееры (CD и DVD), акустические системы, цифровые музыкальные инструменты, а также периферийные устройства компьютеров (принтеры, сканеры, устройства хранения данных) и сами компьютеры могут объединяться в единую сеть. Шина не требует управления со стороны компьютера. Шина поддерживает динамическое реконфигурирование — возможность «горячего» подключения и отключения устройств. События подключения/отключения вызывают сброс и реинициализацию: определение структуры шины (дерева), назначение физических адресов всем узлам и, если требуется, выборы мастера циклов, диспетчера изохронных ресурсов и контроллера шины. Через доли секунды после сброса все ресурсы становятся доступными для последующего использования, и каждое устройство имеет полное представление обо всех подключенных устройствах и их возможностях. Благодаря наличию линий питания, интерфейсная часть устройства может оставаться подключенной к шине даже при отключении питания функциональной части устройства.
По инициативе VESA шина позиционируется как основа «домашней сети», объединяющей всю бытовую и компьютерную технику в единый комплекс. Эта сеть является одноранговой (peer-to-peer), чем существенно отличается от USB.
Основные свойства шины FireWire перечислены далее:
- Равноранговость. Шина позволяет любым своим абонентам обмениваться данными друг с другом. Для организации обменов не требуется хост-компьютер (и его ресурсы — память и процессор), который мог бы стать «бутылочным горлом» при интенсивных обменах.
- Универсальность. Шина обеспечивает передачу как асинхронного, так и изохронного трафика. Это позволяет объединять в единую сеть компьютеры, их периферийные устройства (принтеры, сканеры, устройства хранения) и цифровую аудио-видеотехнику.
- Надежность. Шина обеспечивает контроль достоверности передачи, обработку и исправление ошибок.
- Легкость установки и использования. Для начала работы достаточно соединить устройства, соблюдая несложные топологические правила.
- Большое число соединяемых устройств. Одна шина может объединять до 63 устройств (узлов). Возможно объединение в единую сеть нескольких шин (формально — до 1024) с помощью мостов или коммутаторов.
- Свободная топология. Устройства могут иметь один или несколько портов. Посредством унифицированных кабелей устройства соединяются произвольным образом, исключая лишь петлевые соединения. Ограничение — между любой парой конечных узлов должно быть не более 16 промежуточных узлов.
- Большая протяженность. Длина одного кабельного сегмента, соединяющего пару устройств, может достигать 4,5 м. Ограничение — суммарная длина кабеля в одной шине не должна превышать 72 м.
- Полная поддержка PnP с динамическим конфигурированием:
- автоматическое конфигурирование. В процессе инициализации устройства шины автоматически организуются в иерархическую структуру (дерево) и самоидентифицируются (определяют свои номера узлов и предоставляют информацию о себе);
- поддержка «горячего» подключения-отключения. Любое событие подключения/отключения вызывает реинициализацию шины, после которой формируются новое дерево и новая нумерация узлов. Во время реинициализации «полезный» обмен данными прерывается, но время реконфигурирования невелико — менее 400 мс в старой шине и менее 200 мкс для 1394a.
- Сосуществование на одной шине устройств с различными скоростями обмена. Для шины определен ряд стандартных скоростей: S100, S200, S400; в IEEE 1394b (2002 год) определены новые скорости: S800, S1600 и S3200. При обменах выбирается скорость, доступная узлам, вовлеченным в передачу.
- Высокая скорость обмена и изохронные передачи. Даже на начальном уровне S100 (около 100 Мбит/с) по шине можно передавать одновременно два канала видео вещательного качества (30 кадров в секунду) и аудиосигнал с качеством CD (стерео).
- Питание от шины. Шина обеспечивает питание устройств постоянным током до 1,5 А с напряжением 8–40 В.
- Малое число цепей. В шине используются две экранированные витые пары для передачи сигналов и дополнительно пара проводов для питания от шины.
- Возможность гальванической развязки. Компоненты физического уровня, электрически связанные с коннекторами и кабелями, могут быть развязаны по постоянному току от остальных компонентов устройства. В новых вариантах среды передачи IEEE 1394b возможна полная гальваническая развязка узла от кабеля и применение оптоволоконной связи.
- Низкая цена компонентов и кабеля (по сравнению со SCSI).
Общая информация о передаче данных
- Подробности
- Родительская категория: Шина IEEE 1394 — FireWire
- Категория: Передача данных по шине IEEE 1394
Шина IEEE 1394 поддерживает два типа передач данных:
- асинхронные передачи без каких-либо требований к скорости и задержке доставки. Целостность данных контролируется CRC-кодом. По адресации различают две разновидности:
- направленная асинхронная передача адресуется конкретному узлу, гарантированную доставку обеспечивает механизм квитирования и повторов;
- широковещательная асинхронная передача адресуется всем узлам и выполняется без гарантии доставки (квитирование и повторы не применяются).
- Изохронные передачи с гарантированной пропускной способностью. Целостность данных контролируется CRC-кодом, гарантии доставки нет — квитирование и повторы не применяются.
Направленные асинхронные передачи являются основой для выполнения асинхронных транзакций — логически завершенных обменов между парами узлов. Протокол шины позволяет узлам с помощью асинхронных транзакций обращаться к памяти (регистрам) друг друга в режиме прямого доступа (DMA). При этом они не нуждаются в памяти и процессорных ресурсах «третьих лиц».
Изохронные передачи представляют собой потоки пакетов данных. Эти передачи ведутся широковещательно и адресуются через номер канала, передаваемый в каждом пакете. На шине может быть организовано до 64 изохронных каналов, передачи всех каналов «слышат» все устройства шины, но из всех пакетов принимают только данные интересующих их каналов. По шине могут передаваться и асинхронные потоки, для которых, в отличие от изохронных, не предоставляется гарантированная полоса пропускания.
Общая информация
- Подробности
- Родительская категория: Шина IEEE 1394 — FireWire
- Категория: Арбитраж и распределение времени шины IEEE 1394
Арбитраж определяет, какому из узлов, запрашивающих передачу, предоставляется это право. Арбитраж обеспечивает гарантированную пропускную способность для изохронных передач и справедливое предоставление доступа узлам для асинхронных транзакций. Арбитраж на шине IEEE 1394 выполняется перед посылкой любого пакета запроса (синхронного или изохронного) или ответа. Исключением является соединенная (concatenated) форма выполнения транзакций. Пакеты квитирования посылаются без арбитража — право на их передачу разыгрывать не надо, поскольку квитанцию посылает только тот единственный узел, к которому адресовался подтверждаемый пакет запроса или ответа.
Арбитражем занимается физический уровень каждого узла шины. Арбитраж выполняется распределенно иерархически: им занимаются все узлы, «верховным» арбитром является корневой узел (root node), автоматически выбираемый на этапе конфигурирования шины.
Физический уровень (PHY) предоставляет канальному уровню (LINK) следующие сервисы арбитража, перечисленные в порядке нарастания приоритетности:
- справедливый арбитраж (fair arbitration service), используемый для передачи обычных асинхронных пакетов;
- приоритетный арбитраж (priority arbitration service), используемый для передачи пакетов начала цикла и приоритетных асинхронных пакетов;
- немедленный арбитраж (immediate arbitration service), используемый для передачи пакетов квитирования;
- изохронный арбитраж (isochronous arbitration service), используемый для передачи изохронных пакетов.
Приоритет в арбитраже на шине IEEE 1394 определяется длительностью зазора арбитража (arbitration gap) — временем, в течение которого узел наблюдает покой шины перед началом передачи запроса арбитража. Чем меньше этот зазор, тем больше шансов у узла получить право на передачу. Исходная схема арбитража 1394 усовершенствовалась дважды: в 1394a были введены механизмы ускоренного арбитража, а в 1394b с его дуплексными соединениями был введен новый механизм — BOSS-арбитраж. Все усовершенствования направлены на снижение непродуктивных затрат времени.
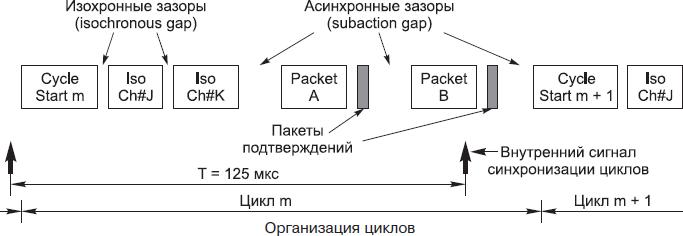
Если на шине используются изохронные передачи, то все транзакции организуются в последовательность циклов — интервалов времени с номинальной длительностью 125 мкс. Начало каждого цикла отмечается широковещательным пакетом начала цикла (Cycle Start). Эти пакеты посылает узел, являющийся мастером циклов. Право на передачу этого пакета мастер получает через арбитраж, используя высокий приоритет. Организация циклов представлена на рисунке, где изображена работа двух изохронных каналов (Ch#J и Ch#K) и передача асинхронных пакетов A и B. После пакета начала цикла каждый узел, которому выделены изохронные каналы, имеет право передать по одному пакету для каждого канала (до прихода следующего пакета начала цикла). Для изохронных передач используется короткий зазор арбитража, так что асинхронные транзакции, использующие более длинный зазор, в изохронную часть цикла вклиниться не могут. После того как иссякнут изохронные пакеты данного цикла, выполняются асинхронные передачи, у которых для арбитража используются более длинные зазоры. Когда наступает пора посылки следующего пакета начала цикла, мастер цикла, дождавшись освобождения шины, снова получает право доступа (пользуясь своим приоритетом, обусловленным его положением в корне дерева) и посылает следующий пакет начала цикла. Таким образом, длительность цикла может отклоняться от номинального значения 125 мкс. Отклонения длительности цикла от номинального не страшны, поскольку пакет начала цикла несет значение системного времени точно на момент фактической передачи этого пакета.
Если на шине не используются изохронные передачи, то мастер циклов может отсутствовать и пакетов начала цикла на шине не будет. В этом случае все время на шине может заполняться асинхронными передачами с их длинными зазорами арбитража.
Общая информация о конфигурировании шины и узлов IEEE 1394
- Подробности
- Родительская категория: Шина IEEE 1394 — FireWire
- Категория: Конфигурирование шины и узлов IEEE 1394
Конфигурирование шины IEEE 1394 выполняется в различных ситуациях:
- автоматически при изменении конфигурации — при подсоединении и отсоединении устройств, а также включении/выключении их PHY-уровня;
- при обнаружении каким-либо узлом фатальной ошибки — «зависания» шины;
- по инициативе какого-либо узла, желающего, например, изменить топологию (сменить корневой узел).
Конфигурирование состоит из трех последовательных этапов.
- Сброс (Bus Reset), с момента которого прекращается передача полезного трафика.
- Идентификация дерева (Tree Identification), во время которой узлы выстраиваются в иерархическую структуру.
- Самоидентификация узлов (Self Identification), во время которой узлы присваивают себе уникальные физические идентификаторы.
Конфигурирование шины приводит ее в состояние, пригодное для передачи полезного трафика. Конфигурирование шины осуществляется исключительно аппаратными средствами PHY-уровня каждого узла (LINK-уровень конфигурируемых узлов может быть и отключен). Программные средства в этом процессе не участвуют. Благодаря чисто аппаратной реализации автоконфигурирование производится настолько быстро, что возможно сохранение непрерывности изохронных потоков.
В первоначальной версии шины самое большое время во всей процедуре конфигурирования занимал сброс. В физический уровень 1394 вносились усовершенствования, направленные на минимизацию потерь времени при сбросе. Остальные этапы конфигурирования происходят быстрее, но в случае образования петлевого соединения идентификация дерева никогда не закончится. Эта ситуация обнаруживается любым узлом, и сообщение о ней доводится до пользователя. В 1394b приняты меры по автоматическому исключению петлевых соединений.
Свойства любого узла сконфигурированной шины наблюдаемы и управляемы через его архитектурные регистры и память конфигурации. Они доступны со стороны шины через асинхронные транзакции к определенным адресам. Архитектурные регистры определяют поведение узла на шине. Память конфигурации раскрывает «прикладную ценность» узла и обеспечивает его уникальную идентификацию, не зависящую от непостоянного физического идентификатора.
Мастер циклов
- Подробности
- Родительская категория: Шина IEEE 1394 — FireWire
- Категория: Управление шиной IEEE 1394
Общая информация
Шина IEEE 1394, обеспечивая равноранговые взаимодействия между узлами, нуждается в централизованном управлении некоторыми функциями. Управляющие функции могут брать на себя разные узлы шины; в зависимости от наличия реализации тех или иных функций различают следующие варианты шины IEEE 1394:
- неуправляемая шина, нуждающаяся только в корневом узле (root), управляющем арбитражем. Корень, который становится «верховным арбитром», выбирается на этапе идентификации дерева. Первоначальный кандидат на эту «должность» выбирается исходя из топологии соединений, с возможным случайным розыгрышем этого права между двумя победителями предпоследнего тура. После завершения выборов корня производится самоидентификация (и назначение физических адресов) узлов, после чего шина становится готовой к асинхронным транзакциям между узлами. Впоследствии программным путем (через асинхронные сообщения по шине) возможно переназначение корня (с определением новой структуры дерева и адресов узлов);
- частично управляемая шина, которая в дополнение к корню должна иметь узлы, выполняющие роль мастера циклов и диспетчера изохронных ресурсов. Их работа обеспечивает возможность использования шины для изохронных передач;
- полностью управляемая шина, которая должна иметь узел-диспетчер шины, обеспечивающий дополнительные сервисы управления.
Мастер циклов
Мастер циклов (Cycle Master) отвечает за регулярную передачу пакетов начала цикла. Для этого он должен быть устройством с поддержкой изохронных обменов, иметь регистры CYCLE_TIME и BUS_TIME. В информационном блоке BUS_INFO_BLOCK его памяти конфигурации должен быть установлен бит cmc (Cycle Master Capable) — признак способности к исполнению этой роли. Текущим мастером циклов является узел, у которого в регистре состояния (STATE) установлен бит cmstr (Cycle Master). Все узлы, кроме корневого, во время идентификации дерева (после сброса) должны обнулить у себя этот бит; корневой узел должен сохранять значение, которое было до сброса.
Если выбранный корневой узел не способен быть мастером циклов, а требуются изохронные передачи, то из узлов, способных быть мастером (судя по биту cmc), выбирается новый кандидат на роль корня. Для этого посылается широковещательный PHY-пакет конфигурирования с идентификатором нового кандидата и установленным битом R. Этот узел установит у себя бит RHB, а остальные его сбросят, что и обеспечит выбор данного узла новым корнем во время идентификации, вызванной посылкой этого пакета.
Мастер циклов является источником системного времени; для этого он имеет регистры CYCLE_TIME и BUS_TIME. Текущее значение регистра CYCLE_TIME передается мастером циклов в пакетах начала цикла. Сброс на шине (в любой форме) на значения этих регистров не влияет.

Регистр CYCLE_TIME (32 бита, рис. а) состоит из трех полей, соответствующих значениям трех счетчиков, соединенных каскадно:
- cycle_offset — 12-битный счетчик по модулю 3072 (максимальное значение 3071, после него обнуляется), считающий импульсы с частотой 24,576 МГц. Период этого счетчика соответствует номинальной длительности цикла — 125 мкс;
- cycle_count — 13-битный счетчик по модулю 8000, считающий циклы. Период этого счетчика — 1 с;
- second_count — 7-битный счетчик, считающий секунды; период счета — 128 с.
Регистр BUS_TIME (32 бита, рис. б) содержит значение системного времени в секундах. Его младшие 7 бит (second_count_lo) отображают поле second_count предыдущего регистра. Остальные 25 бит (second_count_hi) отсчитывают 128-секундные интервалы. Период счетчика составляет 232 = 4 294 967 296 с (около 136 лет).
Еще статьи...
Подкатегории
-
Основная информация
- Кол-во материалов:
- 8
-
Физический уровень шины IEEE 1394
- Кол-во материалов:
- 13
-
Управление шиной IEEE 1394
- Кол-во материалов:
- 9
-
Конфигурирование шины и узлов IEEE 1394
- Кол-во материалов:
- 8
-
Арбитраж и распределение времени шины IEEE 1394
- Кол-во материалов:
- 5
-
Передача данных по шине IEEE 1394
- Кол-во материалов:
- 12
-
«Открытый» хост-контроллер IEEE 1394 — OHCI
- Кол-во материалов:
- 11
-
Взаимодействие с физическим уровнем шины IEEE 1394
- Кол-во материалов:
- 7