
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
новости. ყიდვა გაყიდვა ავტომანქანის ნაწილების საქართველოში.
Память. Нижний уровень
Память. Нижний уровень
Методы доступа
- Подробности
- Родительская категория: Память. Нижний уровень
- Категория: Методы доступа
Различают четыре основных метода доступа. С каждым из них связана своя организация памяти, и их необходимо учитывать при оценке быстродействия ЭВМ.
Последовательный доступ. ЗУ с последовательным доступом, ориентированные на хранение информации в виде последовательности блоков данных, называемых записями. Для доступа к нужному элементу (слову или байту) необходимо прочитать все предшествующие ему данные. Время доступа зависит от положения требуемой записи в последовательности записей на носителе информации и позиции элемента внутри данной записи. Примером может служить ЗУ на магнитной ленте.
Прямой доступ. Каждая запись имеет уникальный адрес, отражающий ее физическое размещение на носителе информации. Обращение осуществляется как адресный доступ к началу записи с последующим последовательным доступом к определенной единице информации внутри записи. В результате время доступа к определенной позиции является величиной переменной. Такой режим характерен для магнитных дисков.
Произвольный доступ. Каждая ячейка памяти имеет уникальный физический адрес. Обращение к любой ячейке занимает одно и то же время и может проводиться в произвольной очередности. Примерами могут служить запоминающие устройства основной памяти.
Ассоциативный доступ. Этот вид доступа позволяет выполнять поиск ячеек, содержащих такую информацию, в которой значение отдельных битов совпадает с состоянием одноименных битов в заданном образце. Сравнение осуществляется параллельно для всех ячеек памяти, независимо от ее емкости. По ассоциативному принципу построены блоки КЭШ-памяти.
Основная память. ОЗУ. Блочная организация основной памяти
- Подробности
- Родительская категория: Память. Нижний уровень
- Категория: Основная память. ОЗУ
Основная память представляет собой единственный вид памяти, к которой ЦП может обращаться непосредственно. Основную память образуют запоминающие устройства с произвольным доступом. Каждая ячейка имеет уникальный адрес, позволяющий различать ячейки при обращении к ним для выполнения операций записи и считывания. Основная память может включать в себя два типа устройств: оперативные запоминающие устройства (ОЗУ) и постоянные запоминающие устройства (ПЗУ).
Преимущественную долю основной памяти образует ОЗУ, называемое оперативным, потому что оно допускает как запись, так и считывание информации, причем обе операции выполняются однотипно, практически с одной и той же скоростью. В англоязычной литературе ОЗУ соответствует аббревиатура RAM — Random Access Memory. Для большинства типов полупроводниковых ОЗУ характерна энергозависимость: даже при кратковременном прерывании питания хранимая информация теряется. Микросхема ОЗУ должна быть постоянно подключена к источнику питания и поэтому может использоваться только как временная память. Вторую группу полупроводниковых ЗУ основной памяти образуют энергонезависимые микросхемы ПЗУ (ROM — Read-Only Меmоrу). ПЗУ обеспечивает считывание информации, но не допускает ее изменения (в ряде случаев информация в ПЗУ может быть изменена, но этот процесс сильно отличается от считывания и требует значительно большего времени). Энергозависимые ОЗУ можно подразделить на две основные подгруппы: динамическую память (DRAM — Dynamic Rаndоm Access Меmory) и статическую память (SRAM — Static Rаndоm Access Меmory). В статических ОЗУ запоминающий элемент может хранить записанную информацию неограниченно долго (при наличии питающего напряжения). Запоминающий элемент динамического ОЗУ способен хранить информацию только в течение достаточно короткого промежутка времени, после которого информацию нужно восстанавливать заново, иначе она будет потеряна. Динамические ЗУ, как и статические, энергозависимы. Роль запоминающего элемента в статическом ОЗУ исполняет триггер. Taкой триггер представляет собой схему с двумя устойчивыми состояниями, обычно состоящую из четырех или шести транзисторов(см. рисунок ниже)
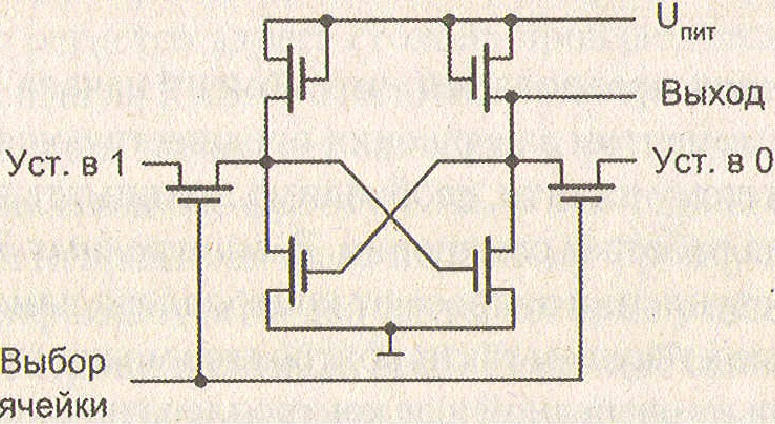
Схема элемента статического ЗУ
Запоминающий элемент (ЗЭ) динамической памяти значительно проще. Он состоит из одного конденсатора и запирающего транзистора (см. рисунок ниже). Простота схемы позволяет достичь высокой плотности размещения, в итоге, снизить стоимость. Главный недостаток подобной технологии связан с тем, что накапливаемый на конденсаторе заряд со временем теряется. Среднее время утечки заряда ЗЭ динамической памяти составляет сотни или даже десятки миллисекунд, поэтому, заряд необходимо успеть восстановить в течение данного отрезка времени, иначе информация будет утеряна. Периодическое восстановление заряда ЗЭ называется регенерацией и осуществляется каждые 2-10 мс.
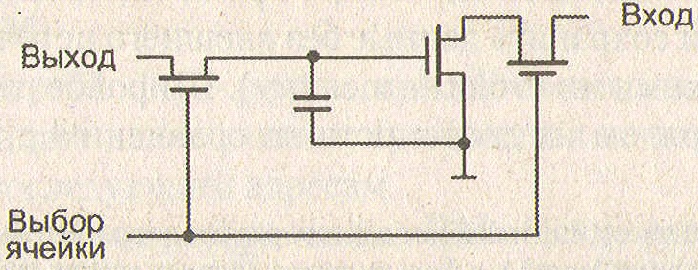
Схема элемента динамического ЗУ
Адресное пространство памяти разбито на группы последовательных адресов. Каждая такая группа обеспечивается отдельным банком памяти. Для обращения используется 9-разрядный адрес, семь младших разрядов которого (А6 — А0) поступают параллельно на все банки памяти и выбирают в каждом из них одну ячейку. Два старших разряда адреса (А8, А7) содержат номер банка. Выбор банка обеспечивается либо с помощью дешифратора номера банка памяти, либо путем мультиплексирования информации (см. рисунок ниже, иллюстрирует оба варианта). В функциональном отношении такая ОП может рассматриваться как единое ЗУ, емкость которого равна суммарной емкости отдельных банков, а быстродействие — быстродействию отдельного банка.
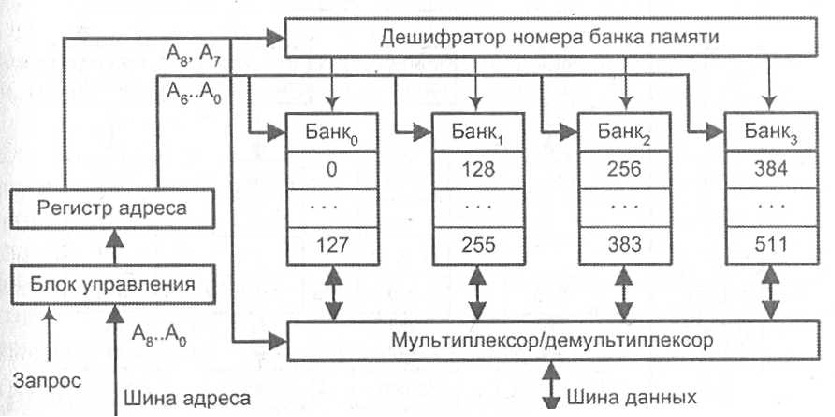
Микросхемы памяти
- Подробности
- Родительская категория: Память. Нижний уровень
- Категория: Микросхемы памяти
Интегральные микросхемы памяти организованы в виде матрицы ячеек, каждая из которых, в зависимости от разрядности, состоит из одного или более запоминающих элементов (ЗЭ) и имеет свой адрес. Каждый ЗЭ способен хранить один бит информации. При матричной организации ИМС памяти (см. рисунок ниже) реализуется координатный принцип адресации ячеек.
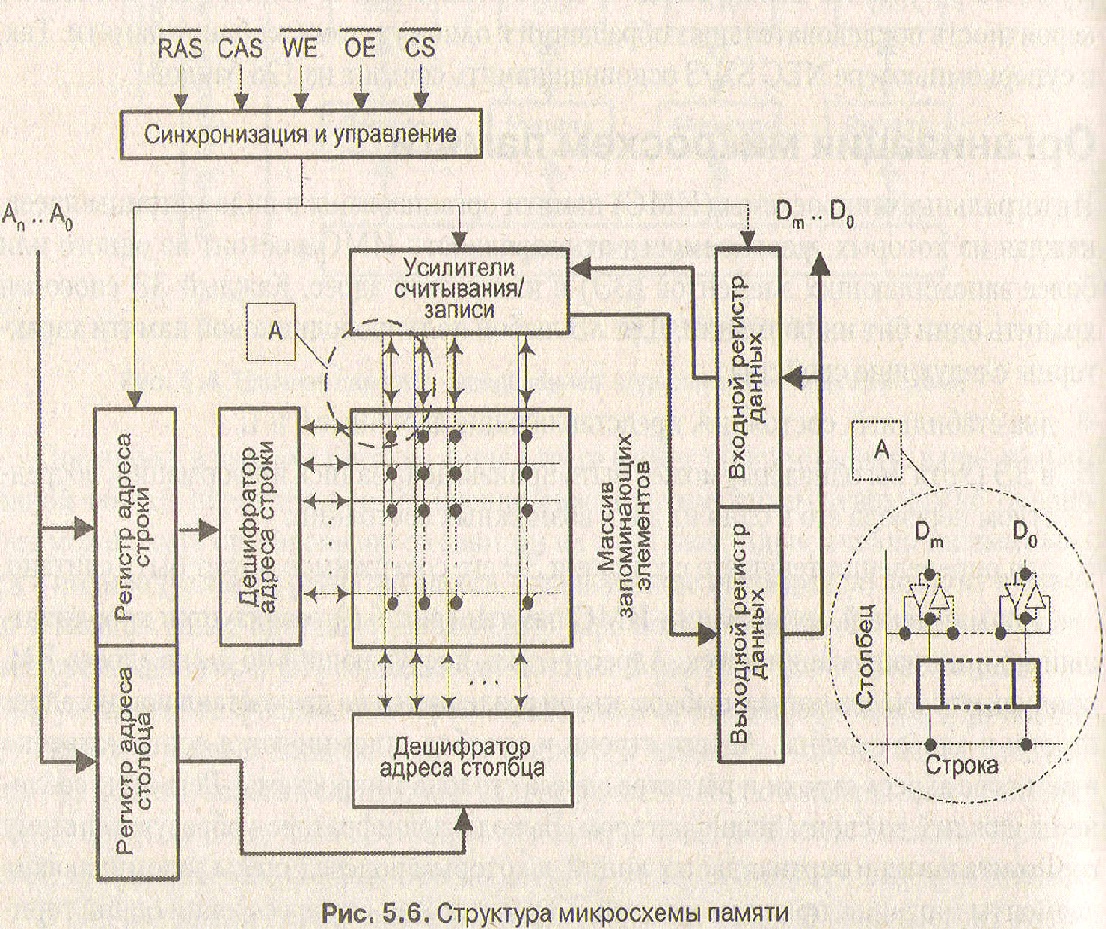
Структурная схема микросхемы памяти
Адрес ячейки, поступающий по шине адреса ЭВМ, пропускается через логику выбора, где он разделяется на две составляющие: адрес строки и адрес столбца. Адреса строки и столбца запоминаются соответственно в регистре адреса строки и регистре адреса столбца микросхемы. Регистры соединяются каждый со своим дешифратором. Выходы дешифраторов образуют систему горизонтальных и вертикальных линий, к которым подсоединены запоминающие элементы матрицы, при этом каждый ЗЭ расположен на пересечении одной горизонтальной и одной вертикальной линии. ЗЭ, объединенные общим горизонтальным проводом, принято называть строкой (row). Запоминающие элементы, подключенные к общему вертикальному проводу, называют столбцом (column). Фактически вертикальных проводов в микросхеме должно быть, по крайней мере, вдвое больше, чем это требуется для адресации, поскольку к каждому ЗЭ необходимо подключить линию, по которой будет передаваться считываемая и записываемая информация. Совокупность запоминающих элементов и логических схем, связанных с выбором строк и столбцов, называют ядром микросхемы памяти. Помимо ядра, в микросхеме имеется еще интерфейсная логика, обеспечивающая взаимодействие ядра с внешним миром. В ее задачи, в частности, входит коммутация нужного столбца на выход при считывании и на вход — при записи. На физическую организацию ядра, как матрицы однобитовых ЗЭ, накладывается логическая организация памяти, под которой понимается разрядность микросхемы, то есть количество линий ввода/вывода. Разрядность микросхемы определяет количество ЗЭ, имеющих один и тот же адрес (такая совокупность запоминающих элементов называется ячейкой), то есть каждый столбец содержит столько разрядов, сколько есть линий ввода/вывода данных. Для уменьшения числа контактов микросхемы адреса строки и столбца в большинстве микросхем подаются через одни и те же контакты последовательно во времени (мультиплексируются) и запоминаются, соответственно, в регистре адреса строки и регистре адреса столбца микросхемы.
Мультиплексирование обычно реализуется внешней логикой. Для синхронизации процессов фиксации и обработки адресной информации адрес строки (RA) сопровождается сигналом RAS (Row Address Strobe — строб строки), а адрес столбца (СА) — сигналом CAS (Column Address Strobe — строб столбца). Чтобы стробирование было надежным, эти сигналы подаются с задержкой, достаточной для завершения переходных процессов на шине адресаj/I в адресных цепях микросхемы. Сигнал выбора микросхемы CS (Crystal Select) разрешает работу схемы и используется для выбора определенной микросхемы в системах, состоящих из нескольких микросхем. Вход WE (Write Enable — разрешение записи) определяет вид выыполняемой операции (считывание или запись). На все время, пока микросхемы памяти не использует шину данных, информационные выходы микросхемы переводятся в третье (высокоимпедансное) состояние. Управление переключением в третье состояние о6еспечивается сигналом ОЕ (Output Enable — разрешение выдачи выходных сигналов). Этот сигнал активизируется при выполнении операции чтения. На рисунке (см. рисунок ниже) представлено изображение ОЗУ на принципиальных схемах.
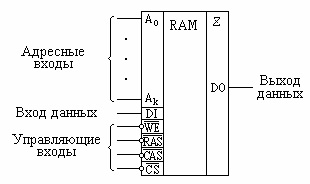
Условное изображение ОЗУ
Структурная схема БИС динамического ОЗУ с четырьмя банками памяти показана на рисунке (см. рисунок ниже). Основными ее компонентами являются четыре банка памяти, представляющих собой матрицы элементов памяти с дешифраторами строк и столбцов и усилителями чтения-записи. Кроме собственно банков памяти, в состав ОЗУ входят:
- буфер адреса, фиксирующий адреса строки и столбца;
- счетчик регенерации, формирующий адрес строки, в которой должна выполняться очередная регенерация;
- дешифратор команд, определяющий, какое действие (команду) должна выполнить микросхема в соответствии с поданными управляющими сигналами (и сигналомA10);
- схемы управления, формирующие управляющие сигналы для остальных узлов микросхемы;
- схемы коммутации данных, передающие читаемые или записываемые данные из/в банки памяти;
- буфер ввода/вывода данных, обеспечивающий связь микросхемы памяти с шиной данных.
Управление операциями с основной памятью осуществляется контроллером памяти. Обычно этот контроллер входит в состав центрального процессора или реализуется в виде внешнего по отношению к памяти устройства. В последних микросхемах памяти часть функций контроллера возлагается на микросхему.
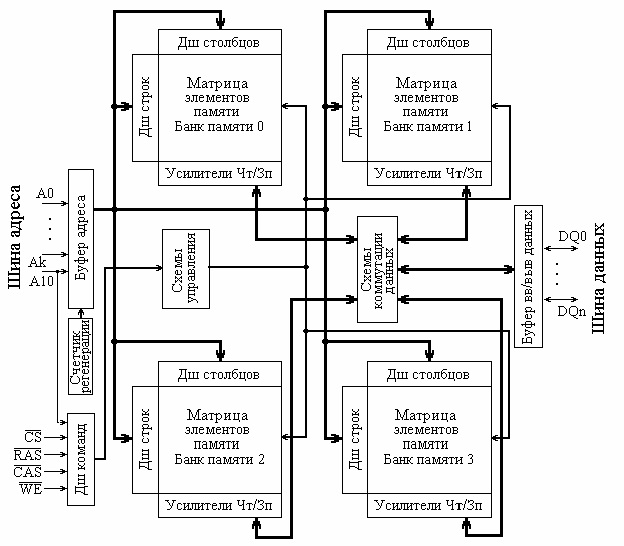
Структурная схема БИС динамического ОЗУ
В общем случае на каждую операцию (считывание или запись) требуется как минимум пять тактов, которые используются следующим образом:
1. Указание типа операции (чтение или запись) и установка адреса строки.
2. Формирование сигнала RAS.
3. Установка адреса столбца.
4. Формирование сигнала CAS.
5. Возврат сигналов RAS и CAS в неактивное состояние. Обратная запись.
Типовую процедуру доступа к памяти рассмотрим на примере чтения с мультиплексированием адресов строки столбцов. Сначала на входе WE
устанавливается уровень, соответствующий операции чтения, а на адресные контакты микросхемы подается адрес строки, сопровождаемый сигналом RAS. По заднему фронту этого сигнала адрес запоминается в регистре адреса строки, после чего дешифрируется. После стабилизации процессов, вызванных сигналом RAS, выбранная строка подключается к усилителям считывания/записи (УСЗ). Далее на вход подается адрес столбца, который по заднему фронту сигнала CAS заносится в регистр адреса столбца. Одновременно подготавливается выходной регистр данных, куда после стабилизации сигнала CAS загружается информация с выбранных УСЗ. Разработчики микросхем памяти тратят значительные усилия на повышение быстродействия микросхем. Возможности "ускорения" ядра микросхемы ЗУ весьма ограничены и связаны, в основном, с миниатюризацией запоминающих элементов. Наибольшие успехи достигнуты в интерфейсной части. Касаются они, главным образом, операций чтения, то есть способов доставки содержимого ячейки на шину данных. Наибольшее распространение получили следующие шесть фундаментальных подходов: последовательный, конвейерный, регистровый, страничный, пакетный, удвоенной скорости. Они будут рассмотрены при обсуждении типов микросхем.
КЭШ-память
- Подробности
- Родительская категория: Память. Нижний уровень
- Категория: КЭШ-память
Как уже отмечалось, в качестве элементной базы основной памяти в большинстве ЭВМ служат микросхемы динамических ОЗУ, на порядок уступающие по быстродействию центральному процессору. В результате процессор вынужден простаивать несколько тактовых периодов. Если ОЗУ выполнить на быстрых микросхемах статической памяти, стоимость ЭВМ возрастет весьма существенно. Экономически приемлемое решение этой проблемы было предложено М. Уилксом в 1965 году в процессе разработки ЭВМ Atlas. Заключается оно в использовании двухуровневой памяти, когда между ОЗУ и процессором размещается небольшая, но быстродействующая буферная память. В процессе работы такой системы в буферную память копируются участки ОЗУ, к которым производится обращение со стороны процессора. Выигрыш достигается за счет ранее рассмотренного свойства локальности. Уилкс называл рассматриваемую буферную память подчиненной (slave). Позже распространение получил термин КЭШ-память (от английского слова cache — “убежище, тайник”), поскольку такая память обычно скрыта от программиста в том смысле, что он не может ее адресовать и может даже вообще не знать о ее существовании. Впервые КЭШ- системы появились в машинах ceмейства IВM 360.
В общем виде использование КЭШ-памяти поясним следующим образом. Когда ЦП пытается прочитать слово из основной памяти, сначала осуществляется поиск копии этого слова в КЭШе. Если такая копия существует, обращение к ОП не производится, а в ЦП передается слово, извлеченное из КЭШ-памяти. Данную ситуацию принято называть успешным обращением или попаданием (hit). При отсутствии слова в КЭШе, то есть при неуспешном обращении — промахе (miss), требуемое слово передается в ЦП из основной памяти, но одновременно из 0П в КЭШ-память пересылается блок данных, содержащий это слово. Выигрыш в скорости при использовании КЭШ получается только в том случае, если перенесенные один раз в КЭШ фрагменты затем используются многократно. Причем, целесообразно помещать в КЭШ одновременно несколько разных участков ОЗУ, так как процессор одновременно работает с разными адресами, например, программой и данными. Согласно описанной выше локальности (локальной серийности), достаточно в КЭШ помещать 10 часть объема программы, чтобы 90% времени процессор работал с КЭШ.
КЭШ-память в вычислительной системе оказывается "двойником" участков основной памяти с адресной организацией. При обращении к основной памяти формируется физический адрес, размер которого соответствует разрядности адресной шины (реальный объем физической памяти обычно меньше, а размер КЭШа в 20…100 раз меньше объема основной памяти). Как в этих условиях схемотехника управления памятью может "понять", что элемент, к которому происходит обращение, находится в КЭШе? КЭШ представляет собой ассоциативную память.
При наличии КЭШ-памяти адресуемый объект может существовать в нескольких экземплярах.
В двухпроцессорной системе с двухуровневым КЭШем, выполняющей самомодифицируемую программу (т.е. программу, изменяющую собственные команды), один и тот же фрагмент кода может существовать в 9 экземплярах:
- 1) в основном ОЗУ,
- 2) и 3) в КЭШах второго уровня двух процессоров,
- 4) и 5) в КЭШах команд первого уровня обоих процессоров,
- 6) и 7) в КЭШах данных первого уровня обоих процессоров,
- 8) и 9) в буферах предвыборки обоих процессоров).
При записи результата операции в КЭШ может оказаться, что содержимое КЭШа и соответствующего элемента ОЗУ становится различным (нарушение когерентности памяти). Другой bus-master может в такой ситуации считать недействительные (старые) данные. Такая ситуации недопустима. Для обеспечения когерентности используется механизм отслеживания достоверности строк КЭШа и объявления содержимого этих строк недостоверным в случае нарушения когерентности. После этого данными из КЭШа пользоваться нельзя, и потребуется обращение к основной памяти для замены значения на обновленное.
На эффективность применения КЭШ-памяти в иерархической системе памяти влияет целый ряд моментов. К наиболее существенным из них можно отнести:
- емкость КЭШ-памяти;
- размер строки;
- способ отображения основной памяти на КЭШ-память;
- алгоритм замещения информации в заполненной КЭШ-памяти;
- алгоритм согласования содержимого основной и КЭШ-памяти;
- число уровней КЭШ-памяти.
Параметры быстродействия ЗУ
- Подробности
- Родительская категория: Память. Нижний уровень
- Категория: Методы доступа
Время доступа. Для памяти с произвольным доступам оно соответствует интервалу времени от момента поступления адреса до момента, когда данные заносятся в память или становятся доступными. В ЗУ с подвижным носителем информации это время, затрачиваемое на установку головки записи/считывания (или носителя) в нужную позицию.
Длительность цикла памяти или период обращения (ТЦ). Понятиеприменяется к памяти с произвольным доступом, для которой оноозначает минимальное время между двумя последовательными обращениями к памяти. Период обращения включает в себя время доступа плюс некоторое дополнительное время. Дополнительное время может требоваться для затухания сигналов на линиях, а в некоторых типах ЗУ, где считывание информации приводит к ее разрушению, — для восстановления считанной информации.
Скорость передачи. Это скорость, с которой данные могут передаваться в память или из нее. Для памяти с произвольным доступом она равна 1/ТЦ. Для других видов памяти скорость передачи определяется соотношением:
TN = ТА + N/R ,
где TN — среднее время считывания или записи N битов; ТА — среднее время доступа; R — скорость пересылки в битах в секунду.
Еще статьи...
Подкатегории
-
КЭШ-память
- Кол-во материалов:
- 7
-
Микросхемы памяти
- Кол-во материалов:
- 6
-
Основная память. ОЗУ
- Кол-во материалов:
- 1
-
Методы доступа
- Кол-во материалов:
- 3
Американские сигареты смотрите на sigarety-rublevka.online.